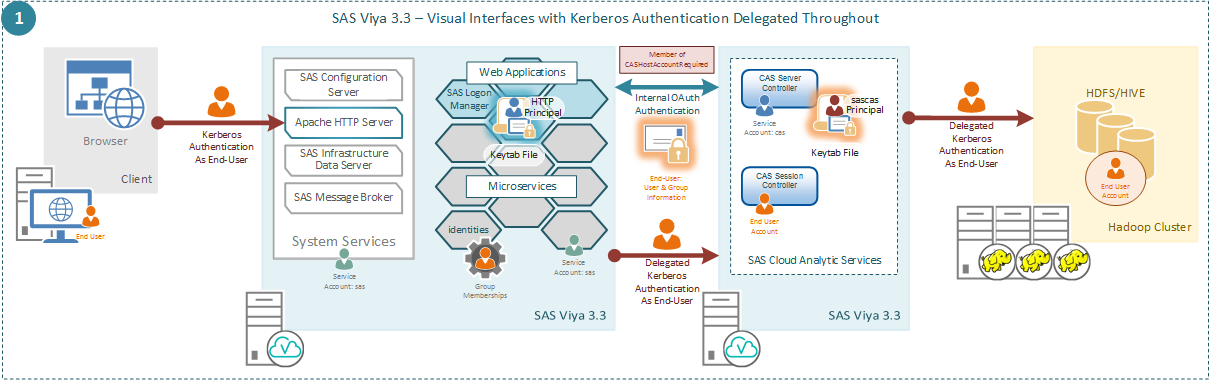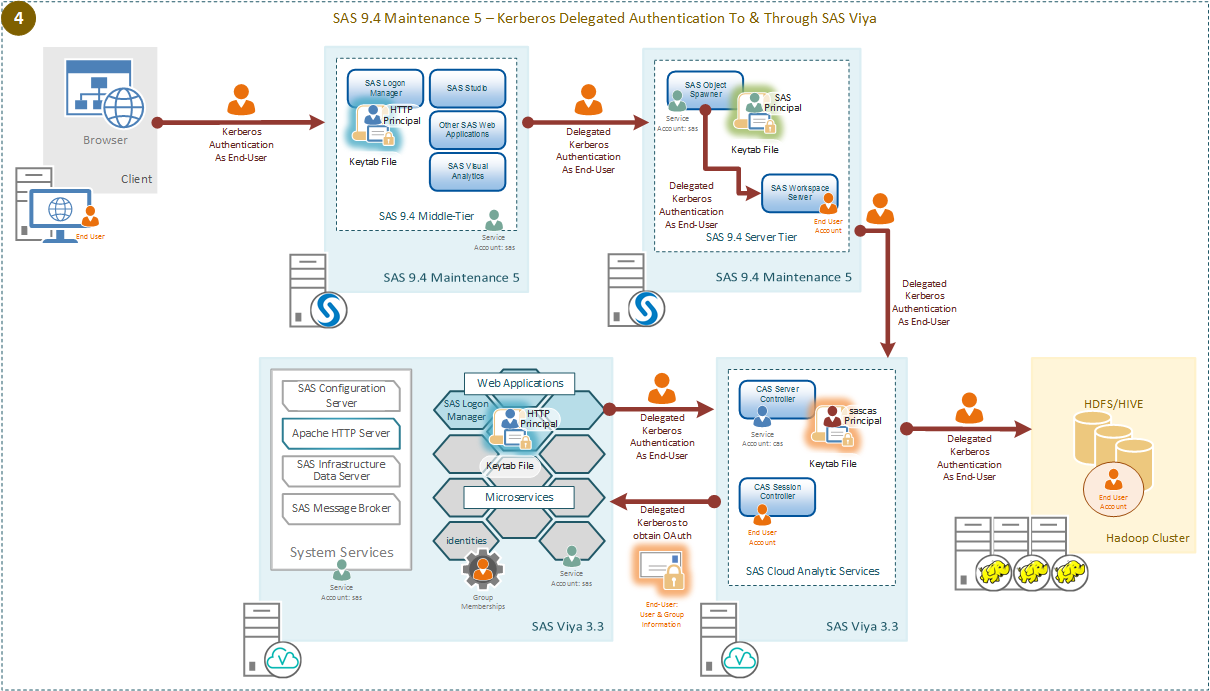
SAS Viya 3.3 Kerberos Delegation from SAS 9.4M5

You can now enable Kerberos delegation across the SAS Platform, using a single strong authentication mechanism across that single platform. As always with configuring Kerberos authentication the prerequisites, in terms of Service Principal Names, service accounts, delegation settings, and keytabs are important for success.