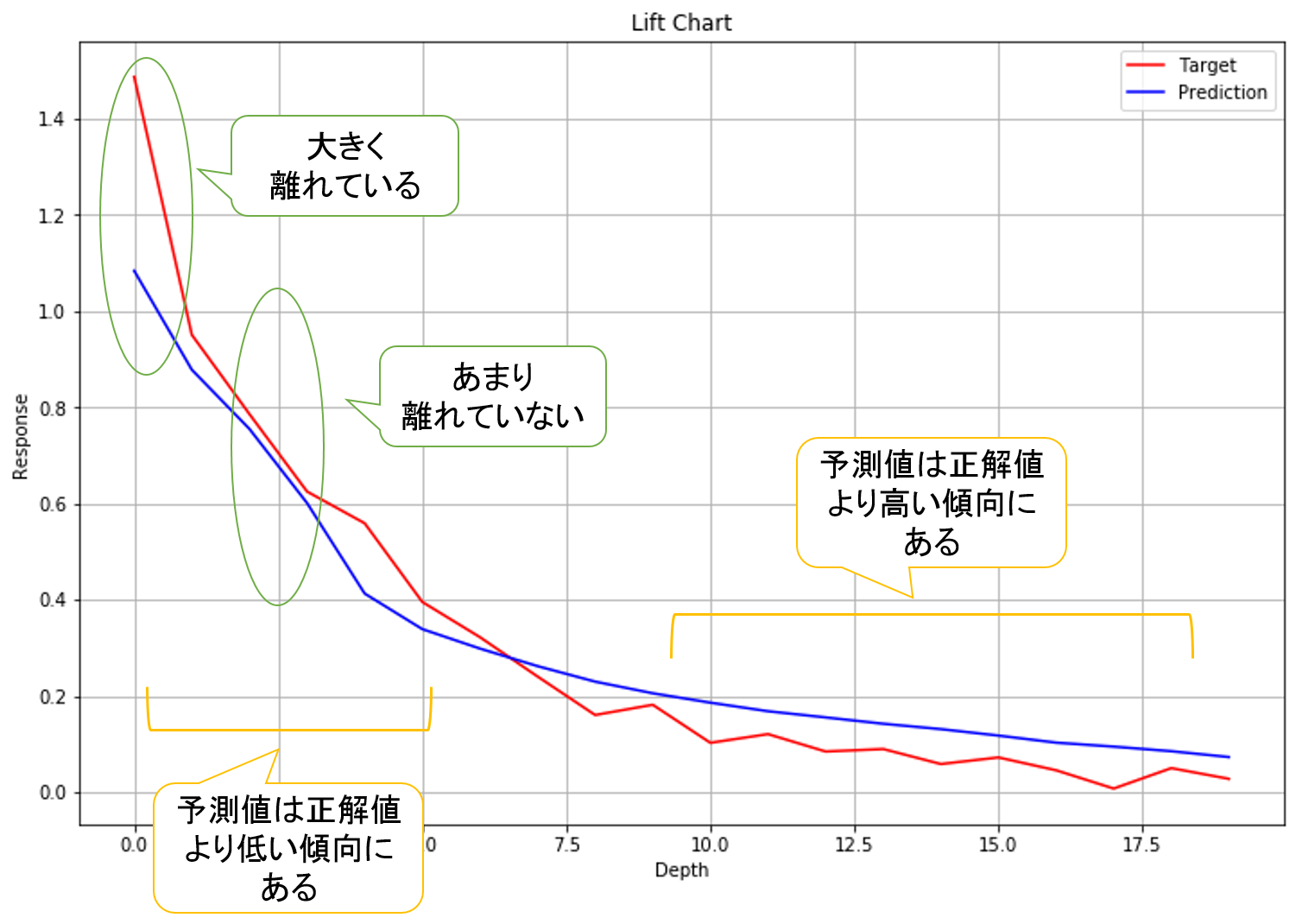

先日投稿した「機械学習のパラメータをオートチューニングしよう(分類編)!」の続きです。 今回は回帰分析をオートチューニングします。 あらまし 機械学習の課題はパラメータチューニングで、手動で最高のパラメータを探そうとすると、とても時間がかかり効率的ではありません。 SAS Viyaではパラメータチューニングを自動化するオートチューニング機能を提供しています。 オートチューニング機能を使うことで、限られた時間内、条件下で最高のパラメータを探索し、予測モデルを生成することができます。 今回やること 今回はオートチューニングを使って数値予測モデルを生成します。 使うデータは架空の銀行の金融商品販売データです。顧客の取引履歴と営業履歴から構成されており、新たな金融商品の販売数を予測するデータとなっています。 内容は以下のようになっており、約5万行、22列の構成です。 1行1お客様データとなっていて、顧客の口座情報や取引履歴、営業履歴が1行に収納されています。 ターゲット変数はcount_tgtで、これは各顧客が購入した金融商品数を表しています。 ほとんどが0(=未購入)ですが、購入されている顧客の購入数を予測するモデルを生成します。 今回はランダムフォレストを使って予測したいと思います。 ランダムフォレストは別々の決定木を複数作り、各決定木の予測値をアンサンブルして最終的な予測値とする機械学習の一種です。 まずは手動で予測 SAS Viyaでランダムフォレストを使って予測モデルを生成するにあたり、まずはCASセッションを作ってトレーニングデータとテストデータをインメモリにロードします。 # PythonからCASを操作するためのSWATライブラリをインポート import swat # 接続先ホスト名、ポート番号、ユーザー名、パスワードを指定 host = "localhost" port = 5570 user = "cas" password = "p@ssw0rd" # mysessionという名称のCASセッションを作成 mysession = swat.CAS(host, port, user, password)
