
The advent of Model Context Protocol (MCP) and Agent-to-Agent Protocol (A2A) underlines a crucial point: AI systems are moving fast and agentic AI is the future.
Security professionals must catch up quickly. One security space that will have to get up to speed is threat modeling. The recent introduction of the MAESTRO threat modeling framework provides us with a new starting point from which to build modern threat models to protect and evaluate the security of agentic AI systems. Let's examine some approaches that will help us better secure agentic systems for years to come.
Model Context Protocol
MCP is a standard recently released by Anthropic, revolving around using client-server interactions common in today's API and web-based systems. It provides a standardized approach for LLMs or similar AI agents to call tools, allowing them to be more effective at real-world tasks, not just content generation. An LLM, acting as the brain of operations, can call an MCP tool to simply email someone or run an entire marketing campaign. The scope is endless, as are the complexities. While advertised as deterministic peripherals for agentic systems to wield, these MCP tools can relay instructions or nuances of their functionality back to a core logic agent. Effectively, we have entered a world where even the simplest operations can have sub-context and nuanced exchanges, introducing risk where confidence and safety were nearly a given before.
Agent-to-Agent Protocol
Agentic AI systems don't just need to talk to tools; they also need to talk to each other. Enter Google’s Agent-to-Agent standard, which allows agents to securely interact with each other, sharing goals, instructions and data. This is the logical next step in the agentic paradigm. Humans no longer need to manually transfer the data between two tools or establish complex connections between agentic systems. They can discover and maintain these interactions themselves. It's convenient – until security issues come knocking! Below, I offer two examples of practical additions to any security professional’s threat model to evaluate and identify risks in agent goal alignment and agent tool instructions.
Goal alignment
Goal alignment is the stuff of science fiction movies. For a long time, artificial intelligence systems have been theorized to possess the intrinsic capability to exceed their creators' expectations, intentions, or safeguards. Therefore, ensuring that an agent's goals fully align with the developer's is absolutely critical. There has been a significant amount of research in this space, so it's not something I will discuss much here. However, every developer needs to understand how the system they are creating may or may not align with their established goals. They need to threat model the concern that the agentic system they're developing might not perfectly reflect their values or approaches to solving problems.
Now, introduce A2A, where not only does your agentic system have a goal that may not be perfectly aligned, but it also talks to its agentic friend, who might also need alignment. This goal sharing and negotiation open the door for less-than-respectable actors to skew an AI system. Security professionals must understand these additional risks and work to mitigate them.
Instrumental goals
As a subset of the goal alignment problem, instrumental goals represent a hidden additional complexity of developing AI systems with goals that align with the developer's values. Instrumental goals are the sub-goals an entity takes on to complete the main goal. You can think of it like deciding whether to ride a bike or drive a car down to a local restaurant when the goal is to get some food. Both driving and biking have trade-offs to achieve the final goal. However, in a hypothetical scenario where the goal is to get to a local restaurant, if the sub-goal is to run down the street screaming at the top of your lungs, this sub-goal would seem misaligned with the main goal, even if it could still result in the same outcome – you still got to the restaurant.
Understanding and aligning an agent’s instrumental goals runs headfirst into Model Context Protocol, because MCP’s tools are where the goals translate into actions. If an agentic system uses an incorrect tool to achieve its aligned goal or uses a correct tool incorrectly, the outcomes could have far-reaching impacts. Security professionals should be able to identify points in an agentic architecture where tooling, goals, and instructions clash. This is where supply chain security, guardrails and other common security controls will all be required to ensure safe and reliable tool usage.
Threat modeling A2A and MCP
Every agentic AI threat model should reference goals and instructions similarly to how they represent trust boundaries or data flows. If two systems have been given goals and can exchange said goals, one must plan for a hypothetical anomalous scenario where one agent has misaligned goals and influences another (via A2A) to have misaligned goals. This is referred to in the MAESTRO threat modeling framework as a goal misalignment cascade. This type of goal misalignment requires trust between agents and might be considered a subset of the concern “Cascading Trust Failure,” as seen in the recent OWASP Agentic Threat Modeling Guide.
Goal alignment example
Suppose we have an LLM to support a user's productivity use cases, like checking e-mail and helping with calendar management. Next to it is a second LLM whose goal is to assist with code generation and review. These two agents use A2A to interact with each other and share goal information, opening the possibility that one gets misaligned and begins to share that misalignment. This could lead to a cascading issue, ultimately making both agents less effective or causing damaging outcomes.
For example, if the code generation agent gets misaligned from a user's goals, such that it wants to only generate code for video games, it might attempt to propagate this goal to the productivity agent, persuading it to schedule video game-related activities for the user. Notice that this goal is not inherently malicious, nor are either of the agents doing something totally unrelated to their initial use case (potentially bypassing guardrails). Instead, one LLM’s goal was slightly off, and it was able to propagate that misaligned goal to another LLM, making both less effective at their tasks (goal misalignment cascade).
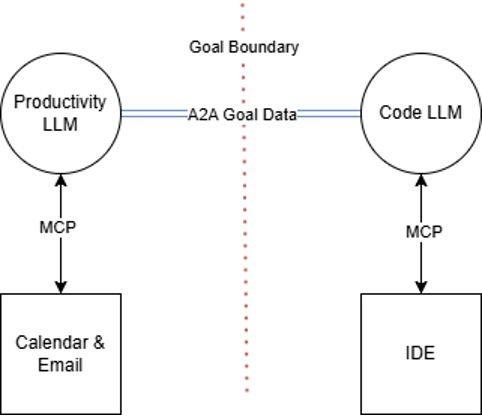
To model this, we would display the LLMs with connections to their specific tools. The productivity agent could connect to a calendar and e-mail service. The code generation LLM would connect to an IDE and perhaps a GitHub repository. However, we need to call out the goal exchange across these connections to properly threat model this. This represents the possibility that these two systems could align their goals with each other, diverging from one or both of their original tasks. This is not to say that it will happen, and certainly, security controls could be put in place to mitigate the concerns or effects of this. However, threat modeling aims to identify threats and risks, which would certainly be one of them. A developer creating this set of agentic systems might decide that these systems should not be able to exchange goal information and might find ways to separate them such that they only interact with the user.
To further illustrate the point, consider if the productivity and code agents have substantially different goals but still need to share information about their goals with each other. We can explicitly model where a goal boundary occurs in an agentic system, identifying points where we need to validate goal data exchanged between agents, while recognizing the potential for friction or misuse.
Tool instruction example
Now let's consider a simplified architecture. If we only have one agent running our system, by definition, we can't have a goal misalignment cascade. However, this doesn't completely clear up the security concern, and we need to threat model for an additional vulnerability type. This tool's poisoning vulnerability notification shows that the tool documentation can send errant instructions or misdirect an LLM towards an alternate goal or malicious action.
This type of vulnerability falls short of goal misalignment because the LLM is using what is provided to try to execute its aligned goal. The true cause of the vulnerability is the tool or attacker injecting instructions into a flow reserved for data. Therefore, we need an additional tool in our threat modeling toolbox to address this concern. We should distinguish between tool calls that only provide data for the tool's intended purpose and tool calls that allow for transferring LLM instruction material.
This gets rather theoretical, as the current Model Context Protocol standard allows comments on a tool to act as LLM instructions. This seems to give an individual too much capability. If we consider a very simplified tool that only performs basic arithmetic, like the “add” function commonly found in MCP boilerplate code, we don't need to instruct the LLM on how to do this. Simply providing a function name and parameters should be sufficient for the LLM to understand the add method. I believe this is true for many basic tool usages, where instructions to the LLM can be simplified or removed altogether, favoring benign tool calls without instructing LLM behavior. This approach opens the door for an additional decision point, where tools can be called without additional instruction, or more complex tools can be called with an instruction set, while taking on additional risk.
To address this, I’ll categorize MCP tool calls into two types. “Parameter-only” tools do not need to exchange instruction data with the LLM. If the LLM knows the tool exists, it can call it using its base training, a parameter set (assumed safe), and “intuition” about the tool’s functionality. On the other hand, “instruction-enabled” tools require additional explanation about inputs or specific instructions to guide an LLM in crafting a proper payload to interact with the tool. By their very nature, these instruction-enabled tools introduce additional risks and opportunities for error or abuse.
Now, for example. Let’s revisit the productivity LLM mentioned earlier, and consider two tool functions: a “list emails” tool and a “schedule recurring meeting” tool. It is straightforward to see that, as long as the LLM has access to a specific user’s email (a separate security topic), listing emails should be as simple as calling the tool. Optional parameters like folder name or date filtering could be used without additional instruction data. In contrast, the scheduling tool requires a significant number of inputs. When, where, and with whom is the meeting? How long will it recur? These are just a few inputs required to properly use this tool.
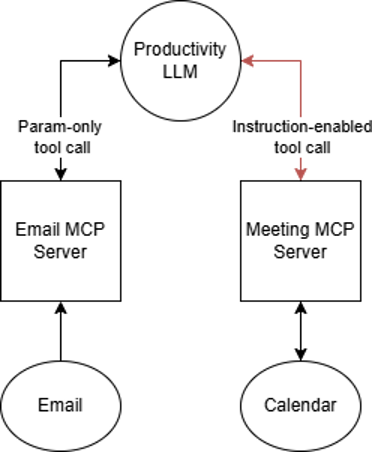
Therefore, our threat model shows one parameter-only tool call to an MCP server and one instruction-enabled call, with the appropriate red arrow callout. While a red line for an MCP tool call may not seem very innovative (and it isn’t), it is a crucial indicator of the capability enabled in this exchange. The LLM is now open to being instructed by or aligned with the tool, rather than the user. As security professionals, we now recognize an additional risk in our agentic architecture. We can begin to apply mitigations to prevent the MCP server from acting maliciously or unwantedly.
Controls and mitigations
This space is still evolving rapidly, so mitigations can be difficult. However, there are some concepts worth exploring to secure these systems:
- This paper from AWS researchers provides an excellent framework for enterprise-grade MCP security. This provides a holistic set of controls to support secure MCP development.
- Guardrails, previously used to prevent external actors from injecting malicious instructions or inducing controversial outputs from LLMs, can be employed between agents to prevent malicious goal negotiation.
- Additional boundary controls, like WAFs and authentication layers, could ensure that agents communicate only with the right agents.
- Data validation on data exchanged during agent negotiations and MCP tool calls. If the action must utilize specific data types or protocols, MCP resource information and A2A artifacts can be sanitized or validated, improving quality and preventing injection.
- Google's CaMeL, or similar brand-new controls, can separate instructions and data flows to prevent untrusted data (like that coming from an instruction-enabled tool call) from influencing the agent's goal.
A2A and MCP protocols will streamline and accelerate the development of agentic systems, but they won’t solve their most fundamental problems. Security professionals cannot wait for established tooling to mitigate security risks; they must identify and develop controls for these new paradigms. I hope this helps; happy threat modeling!

3 Comments
Well done Josh!! This is a great read. Way to highlight the shifting ground beneath agents and how securing agents create additional nuance to think about as these systems become more prevalent.
Great read, and well written indeed - thanks a lot Josh!
Thumbs up! Thoughtful content and a great read.