
At SAS, we believe that more data typically means better insights and outcomes for our customers. However, managing it all is not without challenges. As organizations gather unprecedented amounts of information, they face significant data quality issues like scattered sources, inconsistencies, missing information, and errors. Addressing data quality is essential to unlock the full potential of their data. We developed a proof-of-concept country classification prototype by using the SAS Viya Deep Learning action set to enhance data quality workflows. The prototype uses a transformer-based architecture to predict the country associated with an input address string. This empowers users to preprocess their data with locale-specific cleansing steps.
How does it work?
Figure 1 shows how country classification could be used in a data quality workflow. An address is provided to the prototype, which predicts the country or locale. The classified record is fed into a cleansing process tailored specifically for its predicted locale so that the addresses or other record components are cleansed and standardized for downstream data management or analytical tasks.
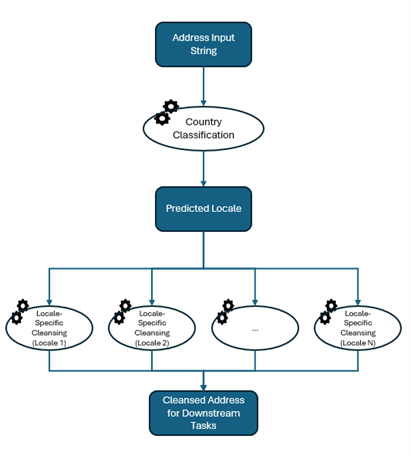
Organizations working with multinational data, such as banks, healthcare providers, and international businesses, should rely on locale-specific data cleansing. This ensures the information is accurate and standardized before downstream data management or analytical tasks. However, country or locale details are often missing or inconsistent, creating significant challenges. This prototype addresses these gaps by accurately classifying data by country, enabling more effective downstream cleansing and analysis.
As a proof of concept, we implemented a transformer on address data for the United States, Mexico, and Canada by using the SAS Viya Deep Learning action set. The transformer architecture, introduced in the landmark paper Attention is All You Need, relies solely on attention mechanisms. This architecture is parallelizable and, therefore, more efficient than RNNs or LSTMs.
Why not use open source, pre-trained models? By implementing the transformer architecture within SAS, we can design compact models that minimize memory consumption and inference time while maintaining robust performance. This approach also offers greater flexibility in choosing the tokenization method and tailoring the model to specific needs.
Prototype architecture
Figure 2 illustrates an encoder-decoder architecture. This architecture is often used for tasks like machine translation, where the output text sequence is a translation of the input text. In this implementation, we use an encoder-only transformer. This corresponds to the left side of the diagram. This architecture is adept at learning general language patterns that can be fine-tuned for specific tasks, such as classification. The attention mechanism simultaneously attends to all parts of the input sequence, enabling it to identify key contextual information more effectively than traditional methods like bag-of-words or sequential approaches while avoiding their limitations in handling long-range dependencies.
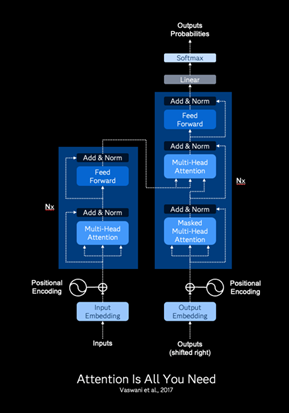
The input consists of two layers: token embedding vectors (shown as the input embedding box in the diagram) and positional embedding vectors. Because transformers do not capture the sequence of the input vectors, the additional positional embedding vector is used to encode the sequential nature of the input tokens.
The two input layers are summed, normalized, and passed into the multi-head attention layer. The outputs of the normalized embeddings and the attention layer are then sent to the feed-forward (fully connected) layer. Finally, the outputs from the normalized attention and feed-forward layers are summed, normalized, and passed to the output softmax layer. The output provides probabilities for each of the three countries and selects the country with the highest probability as the classification.
Because the SAS Viya Deep Learning action set requires an RNN architecture to handle text input, we incorporated a dummy RNN layer immediately before the output layer to meet its requirements without altering the transformer’s functionality. This innovative integration enables us to harness the power of transformers within SAS Viya’s deep learning framework.
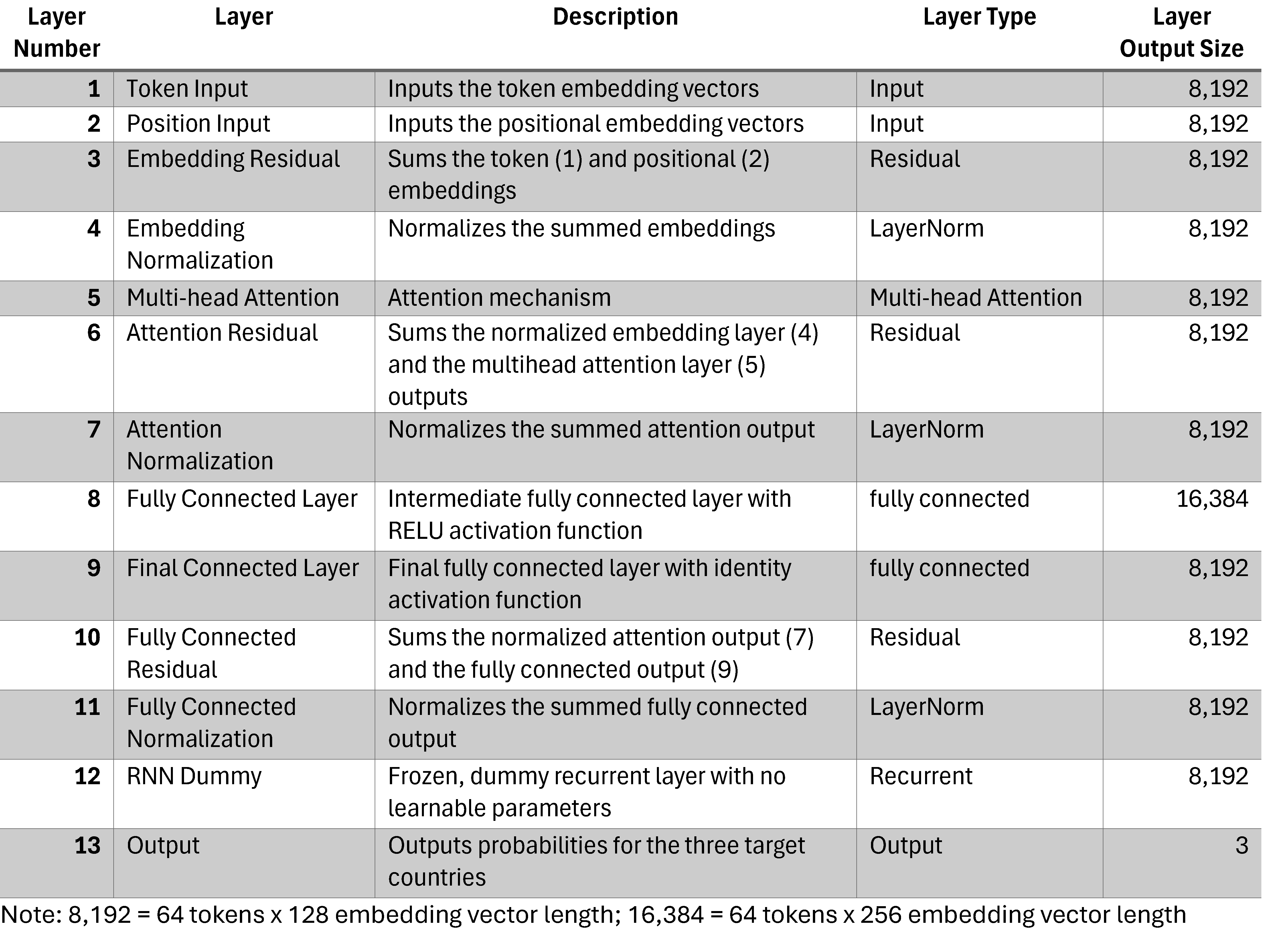
Table 1 describes each layer in the country classification transformer prototype. The layer output size column reflects an input string of 64 tokens and embedding vectors of size 128. The total number of trainable parameters is 166,019.
Prototype performance
We correctly predicted the country for 99.84% of test records. Table 2 shows the classification by country for our testing set.

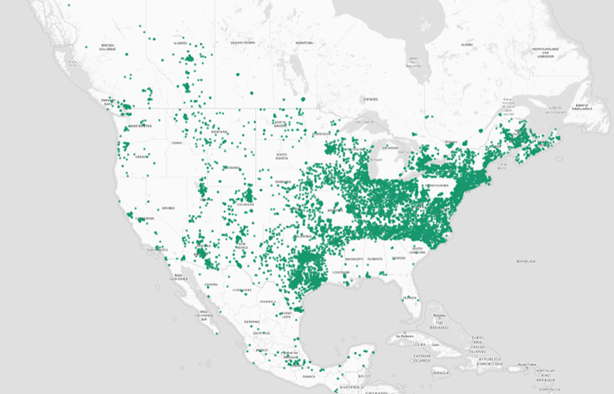
Most misclassified addresses included only a street number and name. This makes it challenging to determine the country without additional context like city, state, or postal code. Figures 3 and 4 illustrate that misclassifications are evenly distributed across the address data. You might expect more misclassifications near borders. For example, Spanish street names could be misclassified as Mexican addresses near the southern U.S. border. However, the results show that the prototype performs consistently well, regardless of proximity to the borders.
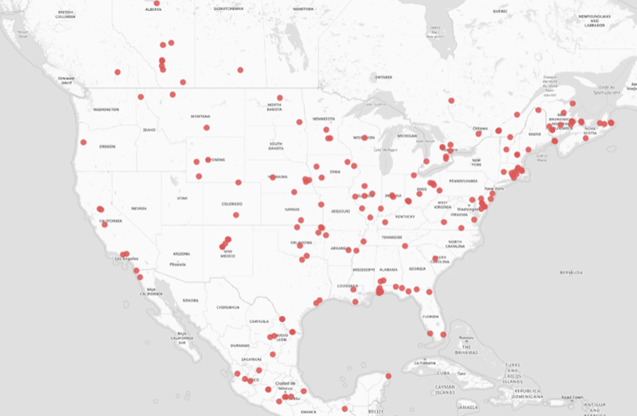
The specific use case would influence the acceptable tolerance for misclassifications. A user-defined threshold enables the users to specify the minimum probability the model must meet to output a country prediction. Records below this threshold are labeled “unknown” and can be otherwise reviewed to ensure accurate classifications.
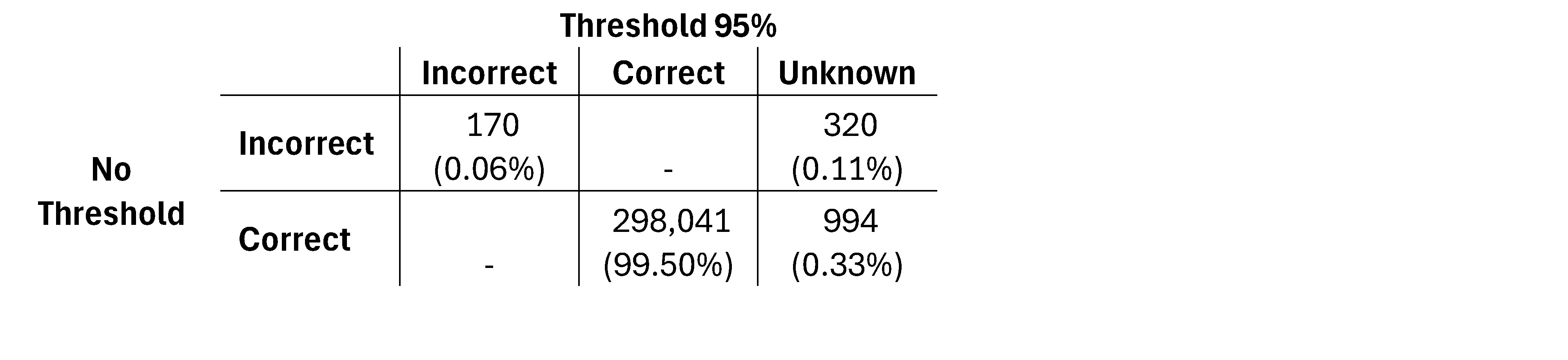
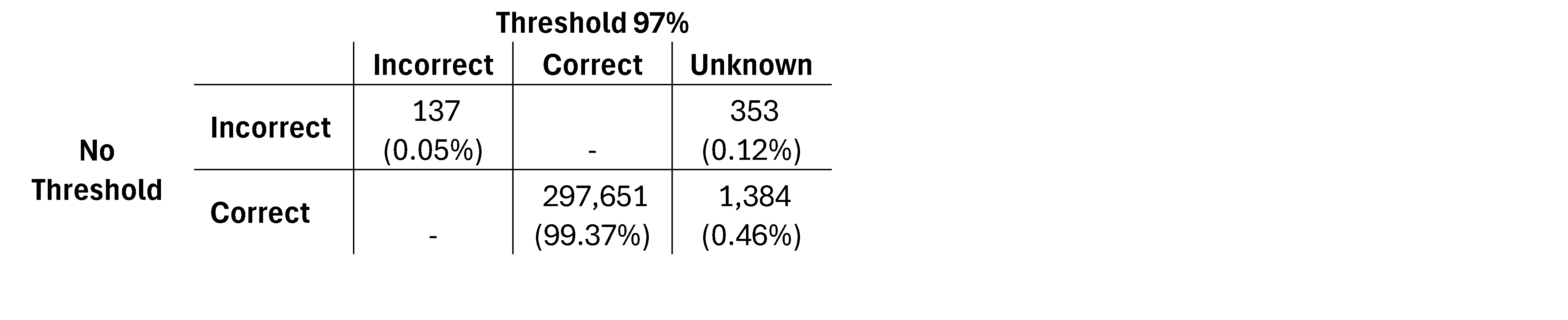
Tables 3 and 4 illustrate the correct, incorrect, and unknown classifications at the 0.95 and 0.97 thresholds. While higher thresholds reduce incorrect classifications by increasing unknowns (from 0.11% to 0.12%), they also shift more correct predictions into the unknown category (from 0.33% to 0.46%).
Looking Ahead
This proof of concept demonstrates the potential of integrating a country classification transformer into data cleansing workflows. This would enable precise address processing for downstream tasks like entity resolution. By building this architecture within the SAS Viya Deep Learning action set, we’ve created a compact, efficient, and flexible proof of concept tailored to SAS’s capabilities. With plans to expand beyond three countries, this approach sets the foundation for scalable, locale-aware data quality solutions.
