This blog post is part three of a series on model validation. The series is co-authored with my colleague Tamara Fischer.
So far, we've been discussing how the base characteristics of the DevOps approach can be applied to the area of analytical work, and we talked about different test categories and how to chain them together. Let's now move from theory to process. Using an analytical platform we recently set up for a SAS customer as our example, this post will describe a fully automated validation pipeline for analytical models.
To get started, here’s a simplified overview of the main components of this platform:
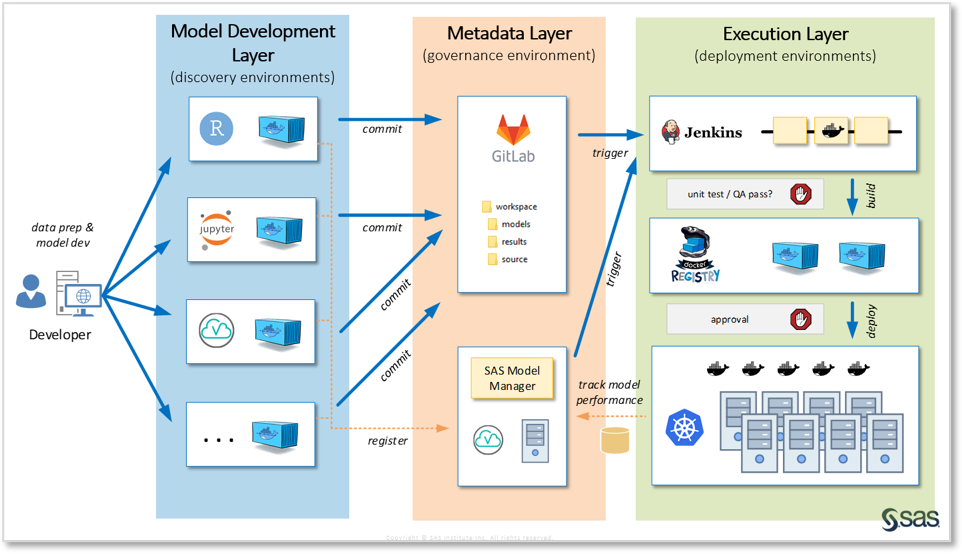
Let's briefly discuss the different components.
Model development (blue)
Data scientists working in this environment decide which modeling tools they want to use, such as R, Python or SAS. Container technology is used to provide individual work spaces for them. SAS Studio, Jupyter Notebook and R Studio are the web-based code editors used by the data scientists. Note that this approach usually requires an “umbrella workbench” application, which is the primary interaction endpoint for users and provides ways to handle the container life cycle. In other words, the work bench offers a GUI with an easy way for users to launch and stop their workspaces, etc.). These workbenches could be developed in-house, but there are also commercial products available which provide a seamless integration with SAS container technology.
Metadata (orange)
As containers are ephemeral in nature, all project artifacts, such as program files, documentation or even small amounts of training data, are kept in a Git source code management system. However, in addition to that, analytical models (e.g., pkl files, SAS ASTORE files) are registered in SAS Model Manager, which is used as a centralized model repository.
Unlike Git, SAS Model Manager is a domain specific tool which was specifically designed to manage analytical models. It provides additional functionality on top of just storing the file artifacts, such as workflow management, model performance monitoring and reporting (shown in the screenshots below).
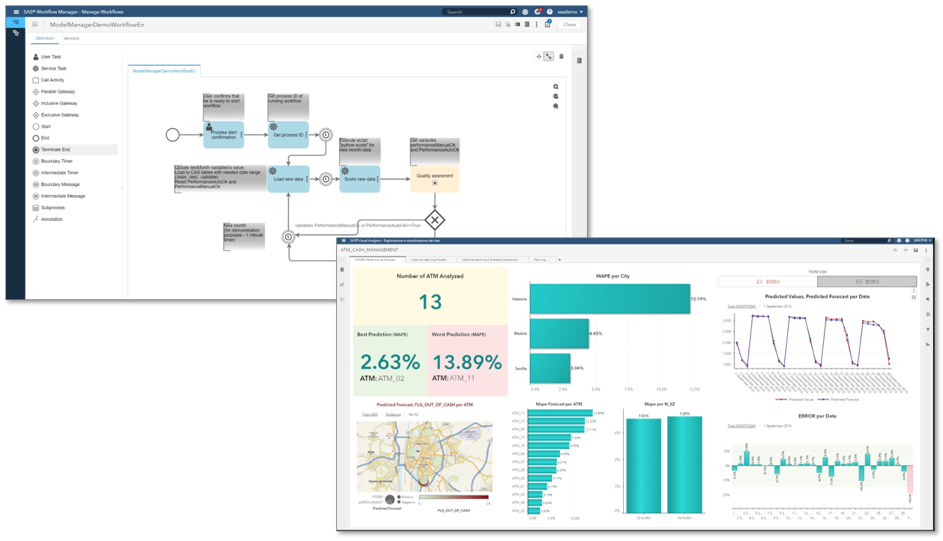
In the real-world example we're using for this blog, SAS Model Manager is an endpoint as the pipeline feeds the validated models into it. However, when taking the wider perspective of looking at the full life cycle of analytical models, SAS Model Manager is also a starting point. From within SAS Model Manager, you can publish a model to its production environment (be it a database, a Hadoop system, a web service or a container orchestration platform), and it can also be used to collect feedback about your model’s performance – allowing you to decide whether it’s necessary to retrain (or replace) the model.
Execution (green)
The execution layer consists of a Kubernetes cluster providing an environment for model runtime containers, as well as for the interactive individual workspace containers. Next to Kubernetes, a Jenkins CI server is configured to run multiple pipelines. These pipelines can be triggered interactively (by pushing a button in SAS Model Manager) or by changes (commits) to the Git projects. Validation pipelines will launch model containers on the Kubernetes cluster and run preconfigured test cases on these models.
These components are connected to each other to create an automated validation pipeline for analytics models. The basic idea is shown in the following workflow diagram:
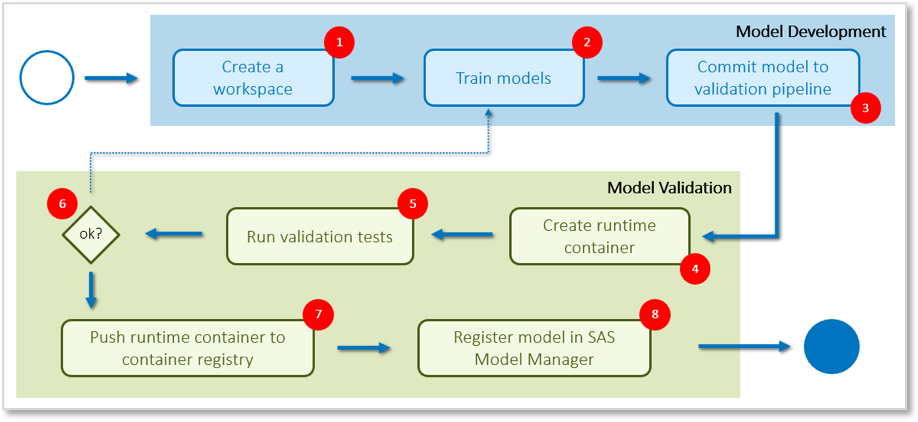
(1) Data scientists begin by requesting the individual workspace they need. For example, they could launch a SAS Viya development environment:
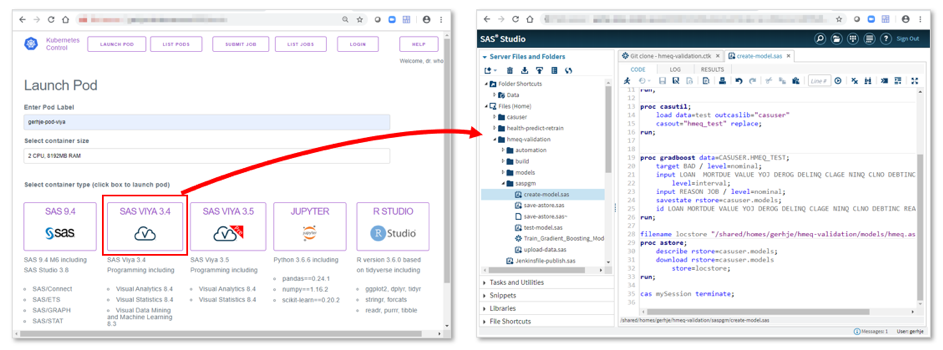
(2) While working on their tasks, the data scientists interact with a Git SCM system, which is the central source repository for all project files (for example, source codes, training data or documentation). A milestone is reached once the user has completed his work up to a point where he or she thinks that the analytical model is ready to be committed to the validation pipeline (3).
At this point an automated process kicks in. The pipeline acts like a quality gateway to make sure that the outcome of the developer’s work is eligible to be registered to the model repository (in this case SAS Model Manager). From there, it can then be published to a production environment. To make sure that the model meets all the requirements, the pipeline runs a collection of unit, integration and API tests against it. Usually these tests are written in the same language that was used for model development (refer to the previous blog post for a simple example of a unit test written in the SAS language).
As we mentioned in post two, ModelOps testing should be automated and non-obstructive. From a technical perspective this is achieved by integrating an automation server with the SCM system. In our case, we’re using Jenkins and Git, but there are certainly alternatives to both tools. Jenkins listens to changes in the Git projects and will trigger the pipeline execution once a user checks in his work to a certain Git branch of his or her project -- speaking technically: We’ve defined a webhook:
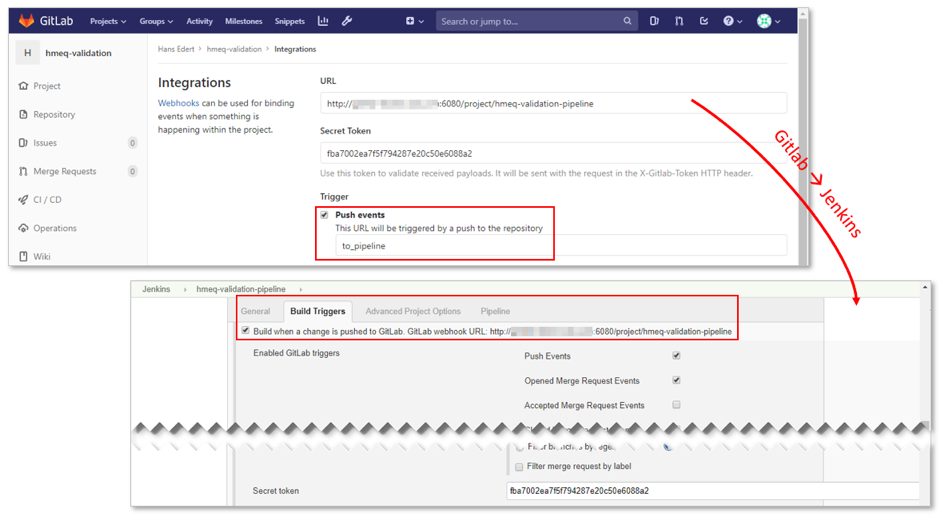
In the previous post we’ve also mentioned end-to-end or API tests. What makes these tests valuable is that they usually run in environments which are close to production. And again, container technology provides a big advantage at this point; the model runtime container image is our deployable unit which can be tested in semi-production and pushed to a production environment without being re-built or re-deployed. So, at the beginning of the validation pipeline, a runtime container image will be set up (4). It consists of the suitable language kernel (e.g. SAS, R, Python – check here for more details) and the specific model which has been committed to the pipeline. All checks will be run against this container image (5) and if successful (6), this image will be pushed to a container registry (7). Refer to our previous blog post for a more detailed discussion on the sequential steps of the Jenkins pipeline.
As a final step, the model will also be registered in SAS Model Manager (8) using the collection of Model Management macros which are supplied out-of-the-box with SAS Model Manager. Here’s a screenshot showing the Jenkins CI server executing a validation pipeline after the user has submitted the analytical model to Git:
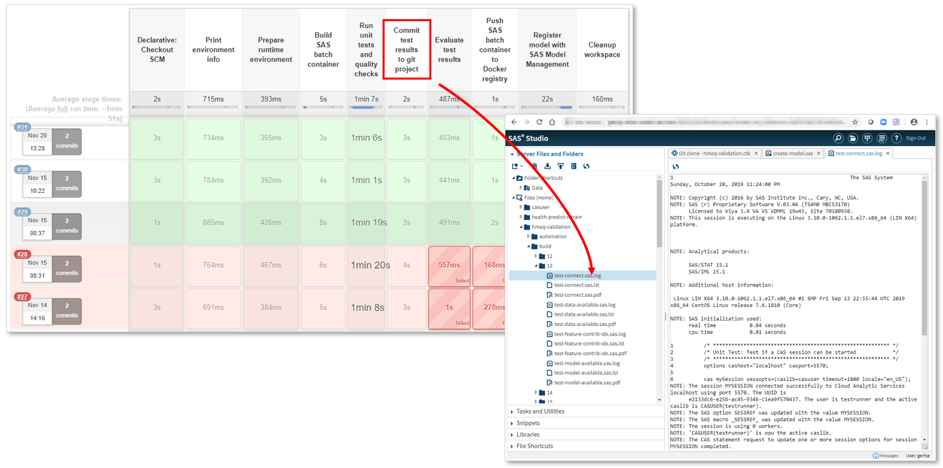
This picture shows successful and failed pipeline executions. The pipelines highlighted in red did fail for at least one test, and as a consequence neither the container image was pushed to the registry nor was the model registered in SAS Model Manager. Follow the column headings to get an idea of the various stages of the validation pipeline. It’s worth mentioning that the pipeline is set up so that developers receive timely feedback when commits are being rejected – which is another core requirement for CI workflows. For example, error logs, listings or even PDF documents generated by the unit tests are pushed to the model’s Git project by the automation server, so they're available for developers in their working environment.
Conclusion
We've tried to cover a lot in this blog series, but there is still so much more we could say. For example, you might wonder: What happens to the analytical models that passed the acid test of the model validation pipeline and made it into the image repository? After all, they’re just at the beginning of their life cycle at this point! We do have good answers to these questions (hint: SAS Model Manager is a good start), but this is a story for another blog post.
In this and the previous two blog posts, we’ve described a way to validate analytical models adhering to continuous itnegration best practices up to the point where they become ready for the “go-live”. Automation (avoiding human intervention), test first and API first have been the guidelines for this process. And while we all probably do agree on the importance of the CI approach as such, it’s also clear that every implementation will be different. So hopefully these blogs have given you some inspiration, and we’d be happy to learn about your approach to operationalizing analytics, a.k.a. completing “the last mile”.
See the next post in this series: Introducing the feature contribution index for model assessment.
Join the virtual SAS Data Science Day to learn more about this method and other advanced data science topics.





