Ensemble methods are commonly used to boost predictive accuracy by combining the predictions of multiple machine learning models. The traditional wisdom has been to combine so-called “weak” learners. However, a more modern approach is to create an ensemble of a well-chosen collection of strong yet diverse models.
Building powerful ensemble models has many parallels with building successful human teams in business, science, politics, and sports. Each team member makes a significant contribution and individual weaknesses and biases are offset by the strengths of other members.
The simplest kind of ensemble is the unweighted average of the predictions of the models that form a model library. For example, if a model library includes three models for an interval target (as shown in the following figure), the unweighted average would entail dividing the sum of the predicted values of the three candidate models by three. In an unweighted average, each model takes the same weight when an ensemble model is built.
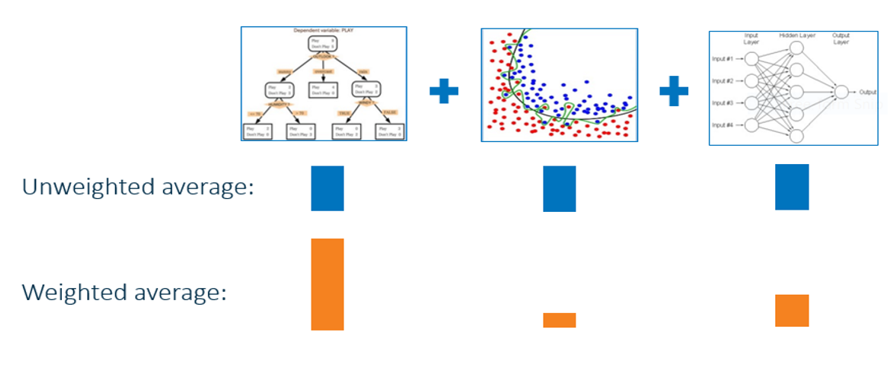
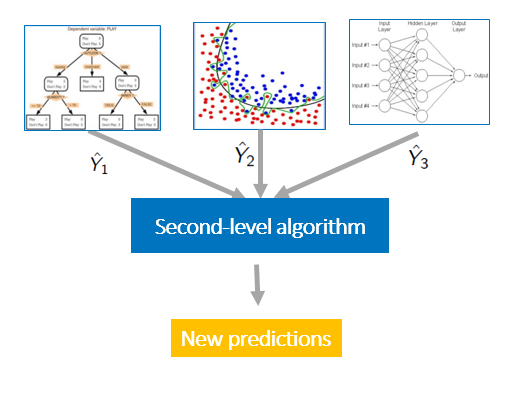
More generally, you can think about using weighted averages. For example, you might believe that some of the models are better or more accurate and you want to manually assign higher weights to them. But an even better approach might be to estimate these weights more intelligently by using another layer of learning algorithm. This approach is called model stacking.
Model stacking is an efficient ensemble method in which the predictions, generated by using various machine learning algorithms, are used as inputs in a second-layer learning algorithm. This second-layer algorithm is trained to optimally combine the model predictions to form a new set of predictions. For example, when linear regression is used as second-layer modeling, it estimates these weights by minimizing the least square errors. However, the second-layer modeling is not restricted to only linear models; the relationship between the predictors can be more complex, opening the door to employing other machine learning algorithms.
Winning data science competitions with ensemble modeling
Ensemble modeling and model stacking are especially popular in data science competitions, in which a sponsor posts a training set (which includes labels) and a test set (which does not include labels) and issues a global challenge to produce the best predictions of the test set for a specified performance criterion. The winning teams almost always use ensemble models instead of a single fine-tuned model. Often individual teams develop their own ensemble models in the early stages of the competition, and then join their forces in the later stages.
On the popular data science competition site Kaggle you can explore numerous winning solutions through its discussion forums to get a flavor of the state of the art. Another popular data science competition is the KDD Cup. The following figure shows the winning solution for the 2015 competition, which used a three-stage stacked modeling approach.
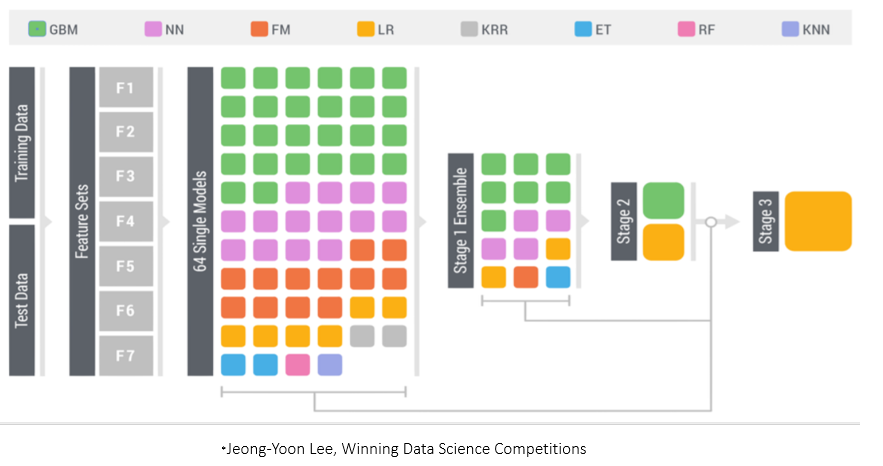
The figure shows that a diverse set of 64 single models were used to build the model library. These models are trained by using various machine learning algorithms. For example, the green boxes represent gradient boosting models (GBM), pink boxes represent neural network models (NN), and orange boxes represent factorization machines models (FM). You can see that there are multiple gradient boosting models in the model library; they probably vary in their use of different hyperparameter settings and/or feature sets.
At stage 1, the predictions from these 64 models are used as inputs to train 15 new models, again by using various machine learning algorithms. At stage 2 (ensemble stacking), the predictions from the 15 stage 1 models are used as inputs to train two models by using gradient boosting and linear regression. At stage 3 ensemble stacking (the final stage), the predictions of the two models from stage 2 are used as inputs in a logistic regression (LR) model to form the final ensemble.
In order to build a powerful predictive model like the one that was used to win the 2015 KDD Cup, building a diverse set of initial models plays an important role! There are various ways to enhance diversity such as using:
- Different training algorithms.
- Different hyperparameter settings.
- Different feature subsets.
- Different training sets.
A simple way to enhance diversity is to train models by using different machine learning algorithms. For example, adding a factorization model to a set of tree-based models (such as random forest and gradient boosting) provides a nice diversity because a factorization model is trained very differently than decision tree models are trained. For the same machine learning algorithm, you can enhance diversity by using different hyperparameter settings and subsets of variables. If you have many features, one efficient method is to choose subsets of the variables by simple random sampling. Choosing subsets of variables could be done in more principled fashion that is based on some computed measure of importance which introduces the large and difficult problem of feature selection.
In addition to using various machine learning training algorithms and hyperparameter settings, the KDD Cup solution shown above uses seven different feature sets (F1-F7) to further enhance the diversity. Another simple way to create diversity is to generate various versions of the training data. This can be done by bagging and cross validation.
How to avoid overfitting stacked ensemble models
Overfitting is an omnipresent concern in building predictive models, and every data scientist needs to be equipped with tools to deal with it. An overfitting model is complex enough to perfectly fit the training data, but it generalizes very poorly for a new data set. Overfitting is an especially big problem in model stacking, because so many predictors that all predict the same target are combined. Overfitting is partially caused by this collinearity between the predictors.
The most efficient techniques for training models (especially during the stacking stages) include using cross validation and some form of regularization. To learn how we used these techniques to build stacked ensemble models, see our recent SAS Global Forum paper, "Stacked Ensemble Models for Improved Prediction Accuracy." That paper also shows how you can generate a diverse set of models by various methods (such as forests, gradient boosted decision trees, factorization machines, and logistic regression) and then combine them with stacked ensemble techniques such regularized regression methods, gradient boosting, and hill climbing methods.
The following image provides a simple summary of our ensemble approach. The complete model building approach is explained in detail in the paper. A computationally intense process such as this benefits greatly by running in a distributed execution environment offered in the SAS® Viya platform by using SAS® Visual Data Mining and Machine Learning.
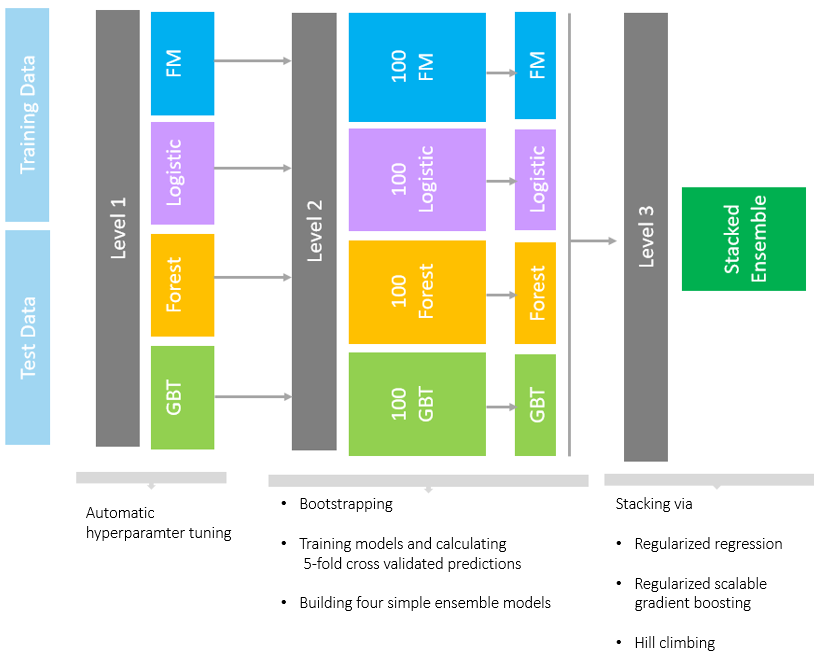
Applying stacked models to real-world big data problems can produce greater prediction accuracy and robustness than do individual models. The model stacking approach is powerful and compelling enough to alter your initial data mining mindset from finding the single best model to finding a collection of really good complementary models.
Of course, this method does involve additional cost both because you need to train a large number of models and because you need to use cross validation to avoid overfitting. However, SAS Viya provides a modern environment that enables you to efficiently handle this computational expense and manage an ensemble workflow by using parallel computation in a distributed framework.
To learn more, check out our paper, "Stacked Ensemble Models for Improved Prediction Accuracy," and read the SAS Visual Data Mining and Machine Learning documentation.