The term "fuzzy matching" describes a method of comparing two strings that might have slight differences, such as misspelling or a middle initial in a name included or not included. One of my favorite functions to compare the "closeness" of two strings is the SPEDIS (spelling distance) function.
Have you ever misspelled a word in Microsoft Word? If so, the word is underlined in red (so they tell me, because I have never misspelled anything) and if you right-click on the word, you see a list of possible alternatives. The algorithm used is similar to the SPEDIS function.
Here is how the SPEDIS function works. It takes two arguments, representing the two strings being compared. If the two strings are exactly the same, the function returns a zero. For each spelling mistake, the function assigns penalty points. Some errors are assigned more penalty points than others. For example, getting the first letter wrong in a word earns high points—interchanging two letters (for example 'ie' for 'ei') earns only a few points. Other errors such as adding a letter or omitting a letter, result an intermediate number of penalty points.
After the two strings are compared, all the penalty points are added up. However, it is not finished yet. The SPEDIS functions returns the number of penalty points as a percentage of the length of the function's first argument. Why does this make sense? Making a spelling mistake in a three-letter word is quite a severe error. Making a spelling mistake in a 10-letter word is considered a minor mistake.
The following table shows a few examples.
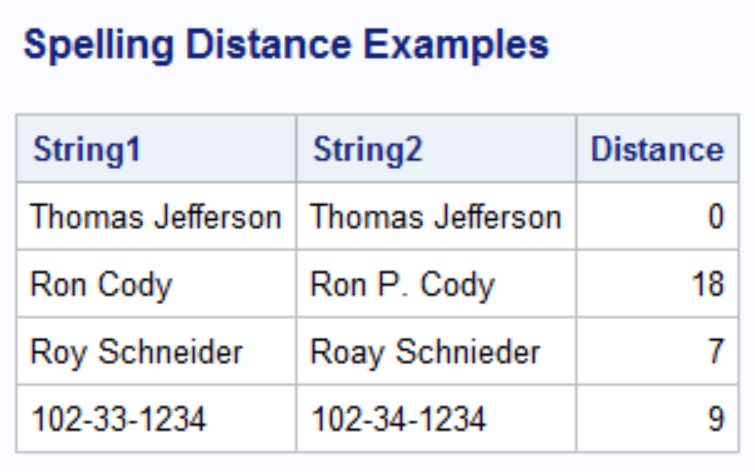
Notice that the SPEDIS function is also useful in comparing digits, such as Social Security numbers.
The next program demonstrates how to use the SPEDIS function to perform a fuzzy match:
*Demonstrating "Fuzzy" Matching; data Compare1; input Subj $3. Name1 $25.; Name1 = compbl(propcase(Name1)); ❶ datalines; 001 Ronald P. Cody 002 Alfred Smith 003 Fred Mastermind 004 Mixed cAse 005 Two SPACES ; Data Compare2; input Name2 $25.; Name2 = compbl(propcase(Name2)); ❷ datalines; Ronald Cody Alfred Smith Fred Dummy MIXEd CAse Too Spaces ; |
❶ To be on the safe side, two functions, COMBL and PROPCASE, are used to convert multiple spaces to a single space (COMPBL) and to convert all names to proper case (PROPCASE).
❷ You use COMPBL and PROPCASE on the second data set.
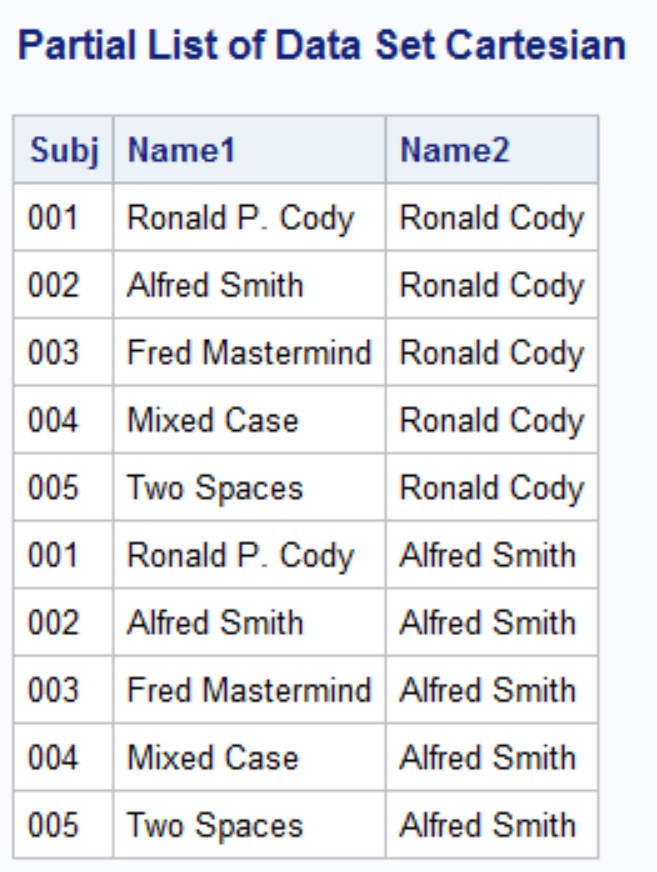
The SAS code that selects exact and near matches uses PROC SQL to create a Cartesian Product. If you have not seen this before, here is a brief explanation. A Cartesian Product contains every combination of observations from one data set to every observation in a second data set. In "real life," you would always include a WHERE clause in the SQL code because the number of observations in a Cartesian Product is the number of observations in the first data set times the number of observations in the second data set. This would, most likely, be huge.
The table below is a partial listing of the Cartesian Product of the two data sets Compare1 and Compare2 (without a WHERE clause).
Next is the remaining code that produces two data sets—one with exact matches and one with possible matches:
proc sql; ❸ create table Exact as select * from Compare1,Compare2 where spedis(Name1,Name2) eq 0; ❹ quit; proc sql; ❺ create table Close as select * from Compare1,Compare2 where 0 lt spedis(Name1,Name2) le 25; ❻ quit; |
❸ This is the PROC SQL code that create the Cartesian Product. You can get more information on this from SAS Help.
❹ If the SPEDIS function returns a 0, you have an exact match.
❺ You repeat the SQL code to create the data set for close, but not exact matches.
❻ You are looking for spelling distances greater than 0 and less than or equal to 25.
Here are the two listings.
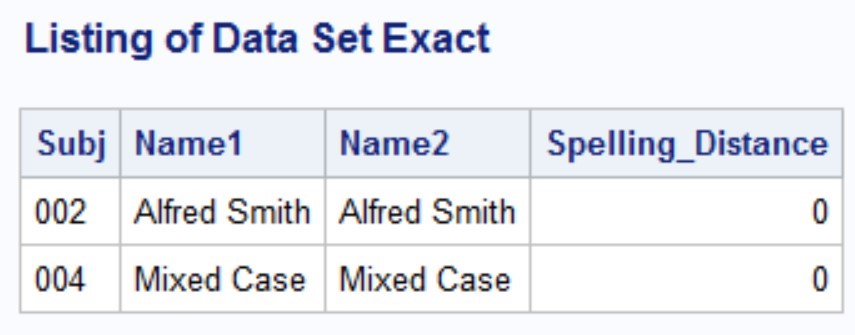
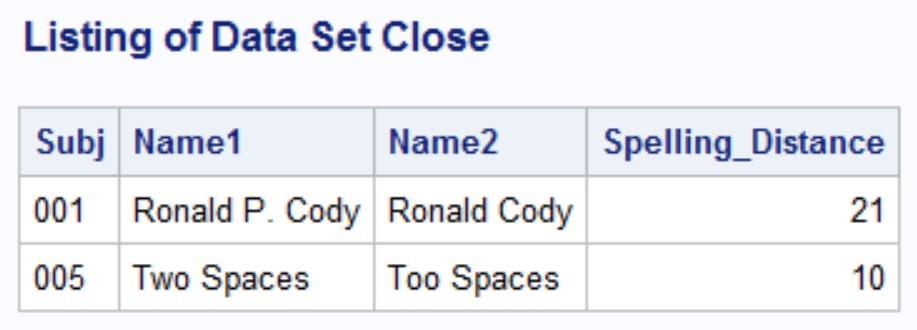
You will need to experiment with the value you choose for considering two strings to be a possible match. I chose 25 in the sample program. If you want to be more certain that the names are possible matches, use a smaller number for creating the data set Exact. If you want to see even remote possible matches, choose a larger value. You also need to consider the length of the two strings. If they are quite long, you might choose a smaller value to be considered a match because the percentage for a single spelling error will result in a relatively small value for the spelling distance.

5 Comments
Could you explain the distance calculation using the penalty points?
How does SPEDIS compare to COMPGED? Is one more advanced or accurate?
I believe SPEDIS is more efficient and easier to use then COMPGED. However, I haven't compared the two. If you give them both a try, please let me know your results. Thanks for taking the time to comment. Ron
Could you also use the SOUNDEX function to find similar strings?
I am not a fan of SOUNDEX. It tends to match strings that are quite different. In my book, SAS Functions by Example, 2nd edition, I demonstrate the SOUNDEX function to perform a fuzzy match. (page 90, if you have a copy). If you don't have access to the Functions book, let me know by email and I will send you the program. Also, there is a macro called NYSIIS that perform matches similar to SOUNDEX but it tightens up the matching rules a bit (insists that the first letters are the same and does not delete vowels.) If you download Example Code from my Functions book (support.sas.com/Cody) you can get all the programs in the book for free and a copy of the NYSIIS macro as well.