 As in many other programming languages, there is a very useful SAS function that removes leading blanks in character strings. It is the ubiquitous LEFT function.
As in many other programming languages, there is a very useful SAS function that removes leading blanks in character strings. It is the ubiquitous LEFT function.
The LEFT(x) function left-aligns a character string x, which effectively removes leading blanks.
See also: Removing trailing characters from SAS strings
However, in many SAS applications we need a similar but more versatile data cleansing functionality allowing for removal of other leading characters, not just blanks. For example, consider some bank account numbers that are stored as the following character strings:
123456789
0123456789
000123456789
These strings represent the same account number recorded with either no, one, or several leading zeros. One way of standardizing this data is by removing the leading 0's. And while we're at it, why don’t we address the leading character removal functionality for any leading characters, not just zeros.
How to remove any leading characters
For example, let’s remove all occurrences of the arbitrary leading character '*'. The following diagram illustrates what we are going to achieve and how:
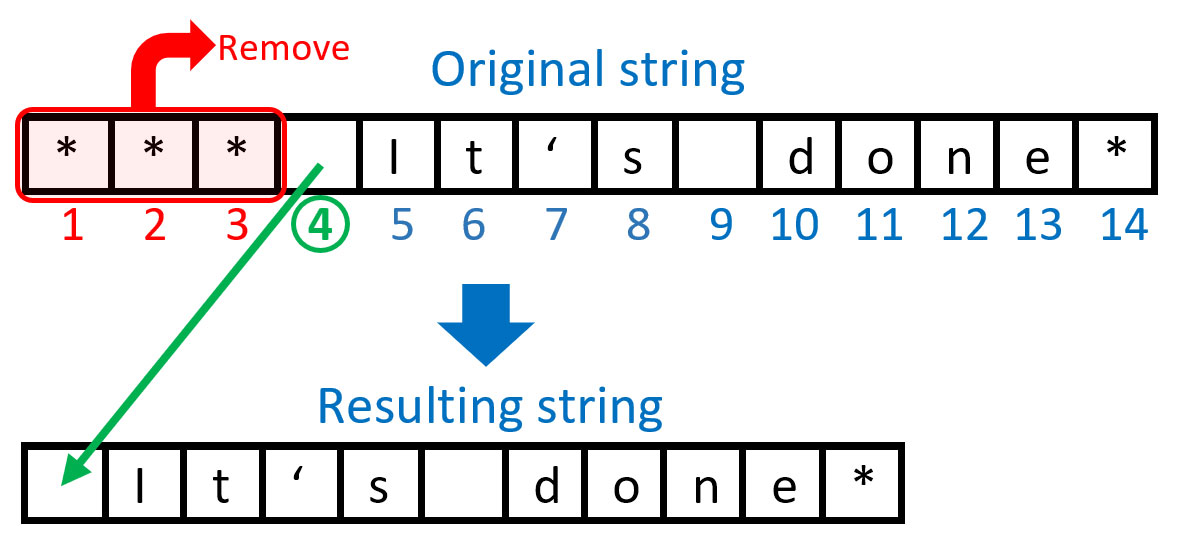
In order to remove a specified character (in this example '*') from all leading positions in a string, we need to search our string from left to right and find the position of the first character in that string that is not equal to the specified character. In this case, it’s a blank character in position 4. Then we can extract a substring starting from that position till the end of the string.
I can see two possible solutions.
Solution 1: Using VERIFY() function
Then we can apply the SUBSTR(X,P) function that extracts a substring of X starting from position P till the end of the string X.
Solution 2: Using FINDC() function
The FINDC(X, C, ‘K’) function also searches string X from left to right and returns the position P of the first character that does not appear in C. (The modifier ‘K’ switches the default behavior of searching for any character that appears in C to searching for any character that does not appear in C.)
Then, as with the VERIFY() function, we can apply the SUBSTR(X,P) function that extracts a substring of X starting from position P till the end of the string X.
Special considerations
So far so good, and everything will be just hunky-dory, right? Not really - unless we cover our bases by handling edge cases.
Have we thought of what would happen if our string X consisted of all '*' characters and nothing else? In this special case, both the verify() function and findc() function will find no position of the character that is not equal to '*' and thus return 0.
However, 0 is not a valid second argument value for the SUBSTR(X,P) function. Valid values are 1 . . . through vlength(X) - the length attribute of variable X. Having a 0 value for the second argument will trigger the automatic data step variable _ERROR_=1 and the following note generated in the SAS log:
NOTE: Invalid second argument to function SUBSTR at line ## column #.
Therefore, we need to handle this special case separately, conditionally using SUBSTR(X,P) for P>0 and assigning blank ('') otherwise.
Code implementation for removing leading characters
Let’s put everything together. First, we'll create a test data table:
data TEST; input X $ 1-20; datalines; *** It's done* ********* **01234*ABC** No leading *'s ; |
Then we apply the logic described above. The following DATA step illustrates our two implemented coding solutions for removing leading characters:
data CLEAN (keep=X Y Z); set TEST; C = '*'; *<- leading character(s) to be removed; P1 = verify(X,C); *<- Solution 1; if P1 then Y = substr(X, P1); else Y = ''; P2 = findc(X,C,'K'); *<- Solution 2; if P2 then Z = substr(X, P2); else Z = ''; put _n_= / X= / P1= / Y= / P2= / Z= /; run; |
The SAS log will show interim and final results by the DATA step iterations:
_N_=1 X=*** It's done* P1=4 Y=It's done* P2=4 Z=It's done* _N_=2 X=********* P1=10 Y= P2=10 Z= _N_=3 X=**01234*ABC** P1=3 Y=01234*ABC** P2=3 Z=01234*ABC** _N_=4 X=No leading *'s P1=1 Y=No leading *'s P2=1 Z=No leading *'s |
Here is the output data table CLEAN showing the original string X, and resulting strings Y (solution 1) and Z (solution 2) side by side:

As you can see, both solutions (1 & 2) produce identical results.
Conclusion
Compared to the LEFT() function, the solution presented in this blog post not only expands leading character removal/cleansing functionality beyond the blank character exclusively. Using this coding technique we can simultaneously remove a variety of leading characters (including but not limited to blank). For example, if we have a string X=' 0.000 12345' and specify C = ' 0.' (the order of characters listed within the value of C does not matter), then all three characters ' ', '0', and '.' will be removed from all leading positions of X. The resulting string will be Y='12345'.
Additional resources
- Deleting a substring from a SAS string
- Inserting a substring into a SAS string
- Removing repeated characters in SAS strings
- Finding n-th instance of a substring within a string
Questions? Thoughts? Comments?
Do you find this post useful? Do you have questions, concerns, comments? Please share with us below.

17 Comments
Thanks a lot, I will definitely going to this logic.
Thanks for sharing.
You are welcome, Sunny. Thank you for your feedback.
Very helpful blog again! Clear explanation and graphics. Using the function Findc to remove leading characters is going into my SAS took kit. I viewed the blog on using function Findc to remove trailing characters first and then this one. Both blogs are winners.
I always like reading the comments on the your blogs, very informative.
Thank you Leonid,
Deb
You are welcome, Deborah! I also like reading (and replying to) the comments, especially such nice and inspiring comments as yours 🙂
It is all neat but it does not scale that nicely if there are a number of possible leading characters. It looks like a good use case for regular expressions to me.
Hi Anton,
I am not quite sure I understand what you mean by "but it does not scale that nicely if there are a number of possible leading characters". Did you miss the Conclusion section where I mentioned that this technique "can simultaneously remove a variety of leading characters"? In addition, using various modifiers for the FINDC() function allows for specifying many characters in bulk, without listing them one by one. For example, we may augment a list of characters being removed by adding 'D' modifier: P = findc(X,C,'KD') which will remove all DIGITS in addition to those characters specified in C. Or 'L' modifier which adds all lowercase letters to the list of characters, and so on.
As for regular expressions, see my reply to a similar comment by Tom Sabo (2nd from the bottom). Yes, you can use regex in SAS by means of the PRX functions (there are always multiple ways of solving a problem), however be ready to pay a price of performance degradation compared to using native SAS functions (such as FINDC). This may not be an issue when processing small amounts of data, but it becomes a substantial factor when processing large data volumes.
its informative
Informative and well explained. So helpful for new learners like me!
Thank you !
You are welcome, Mona. I am really happy to be helpful. Thank you for your feedback!
I think IFC() is my new favorite function! Maybe not as understandable as if...then...else but certainly much cleaner looking code. Thanks for sharing these tips, Leonid.
I am glad to hear it Kevin. Actually, after you use IFC() for a couple of times it'll feel more intuitive and powerful than if...then...else. Since you "bought one" (IFC function), you get another one (IFN function) for FREE! 🙂
Also, I had to withdraw this one-liner IFC solution, as it turned out that all three arguments to the IFC and IFN functions are evaluated BEFORE these functions are called, and the results of the evaluation are then passed to the function. In case of P=0, this will still result in NOTE: Invalid second argument to function SUBSTR, see this blog post by Rick Wicklin.
Thanks, I saw IFN when I dug deeper into IFC. IFC worked well for setting a true/false condition based on finding certain characters in a string, a SQL query in this case.
is_select_distinct = ifc(index(upcase(compress(sql_qry, " "), "SELECTDISTINCT")) > 0, "T", "F");
Yes, there are many cases where IFC (and IFN) function is quite useful. The problem, however, arises when we replace IF-THEN-ELSE in this post solution with Y=ifc(P,substr(X,P),' '). If the first argument P=0 (FALSE), then even though the second argument substr(X,P) is irrelevant, it's still going to be evaluated. This will result in generating "NOTE: Invalid second argument to function SUBSTR..." in the SAS log. It won't affect the final result, but to my taste this NOTE disqualifies IFC from being an acceptable solution. Besides, it reveals inefficiency of the IFC compared to IF-THEN-ELSE (why spend time on evaluating character expression which is going to be discarded anyway!)
Very cool! I see that SAS also enables regular expressions.... https://support.sas.com/resources/papers/proceedings/proceedings/sugi29/265-29.pdf. Would you leverage those for multiple characters or other matching conditions?
Thank you, Tom, for your comment. Yes, the same can be achieved by using PRX functions (PRXMATCH, PRXCHANGE, PRXPARSE, etc.) that enable Perl regular expressions (regex) in SAS. However, from my experience using native SAS functions provides considerably faster performance than using regex which is essential when processing large data; see Using Perl regular expression section in my earlier post.
This is very useful. Thanks a lot!
You are very welcome, Marina!