 Until recently, I used UNIX/Linux shell scripts in a very limited capacity, mostly as vehicle of submitting SAS batch jobs. All heavy lifting (conditional processing logic, looping, macro processing, etc.) was done in SAS and by SAS. If there was a need for parallel processing and synchronization, it was also implemented in SAS. I even wrote a blog post Running SAS programs in parallel using SAS/CONNECT®, which I proudly shared with my customers.
Until recently, I used UNIX/Linux shell scripts in a very limited capacity, mostly as vehicle of submitting SAS batch jobs. All heavy lifting (conditional processing logic, looping, macro processing, etc.) was done in SAS and by SAS. If there was a need for parallel processing and synchronization, it was also implemented in SAS. I even wrote a blog post Running SAS programs in parallel using SAS/CONNECT®, which I proudly shared with my customers.
The post caught their attention and I was asked if I could implement the same approach to speed up processes that were taking too long to run.
However, it turned out that SAS/CONNECT was not licensed at their site and procuring the license wasn’t going to happen any time soon. Bummer!
Or boon? You should never be discouraged by obstacles. In fact, encountering an obstacle might be a stroke of luck. Just add a mixture of curiosity, creativity, and tenacity – and you get a recipe for new opportunity and success. That’s exactly what happened when I turned to exploring shell scripting as an alternative way of implementing parallel processing.
Running several batch jobs in parallel
UNIX/Linux OS allows running several scripts in parallel. Let’s say we have three SAS batch jobs controlled by their own scripts script1.sh, script2.sh, and script3.sh. We can run them concurrently (in parallel) by submitting these shell scripts one after another in background mode using & at the end. Just put them in a wrapper “parent” script allthree.sh and run it in background mode as:
$ nohup allthree.sh &
Here what is inside the allthree.sh:
#!/bin/sh script1.sh & script2.sh & script3.sh & wait |
With such an arrangement, allthree.sh “parent” script starts all three background tasks (and corresponding SAS programs) that will run by the server concurrently (as far as resources would allow.) Depending on the server capacity (mainly, the number of CPU’s) these jobs will run in parallel, or quasi parallel competing for the server shared resources with the Operating System taking charge for orchestrating their co-existence and load balancing.
The wait command at the end is responsible for the “parent” script’s synchronization. Since no process id or job id is specified with wait command, it will wait for all current “child” processes to complete. Once all three tasks completed, the parent script allthree.sh will continue past the wait command.
Get the UNIX/Linux server information
To evaluate server capabilities as it relates to the parallel processing, we would like to know the number of CPU’s.
To get this information we can ran the the lscpu command as it provides an overview of the CPU architectural characteristics such as number of CPU’s, number of CPU cores, vendor ID, model, model name, speed of each core, and lots more. Here is what I got:
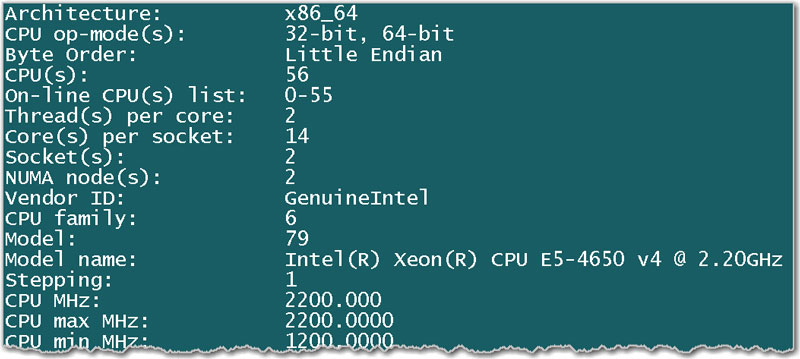
Ha! 56 CPUs! This is not bad, not bad at all! I don’t even have to usurp the whole server after all. I can just grab about 50% of its capacity and be a nice guy leaving the remaining 50% to all other users.
Problem: monthly data ingestion use case
Here is a simplified description of the problem I was facing.
Each month, shortly after the end of the previous month we needed to ingest a number of CSV files pertinent to transactions during the previous month and produce daily SAS data tables for each day of the previous month. The existing process sequentially looped through all the CSV files, which (given the data volume) took about an hour to run.
This task was a perfect candidate for parallel processing since data ingestions of individual days were fully independent of each other.
Solution: massively parallel process
The solution is comprised of the two parts:
- Single thread SAS program responsible for a single day data ingestion.
- Shell script running multiple instances of this SAS program concurrently.
Single thread SAS process
The first thing I did was re-writing the SAS program from looping through all of the days to ingesting just a single day of a month-year. Here is a bare-bones version of the SAS program:
/* capture parameter &sysparm passed from OS command */ %let YYYYMMDD = &sysparm; /* create varlist macro variable to list all input variable names */ proc sql noprint; select name into :varlist separated by ' ' from SASHELP.VCOLUMN where libname='PARMSDL' and memname='DATA_TEMPLATE'; quit; /* create fileref inf for the source file */ filename inf "/cvspath/rawdata&YYYYMMDD..cvs"; /* create daily output data set */ data SASDL.DATA&YYYYMMDD; if 0 then set PARMSDL.DATA_TEMPLATE; infile inf missover dsd encoding='UTF-8' firstobs=2 obs=max; input &varlist; run; |
This SAS program (let’s call it oneday.sas) can be run in batch using the following OS command:
sas oneday.sas -log oneday.log -sysparm 20210304
Note, that we pass a parameter (e.g. 20210304 means year 2021, month 03, day 04) defining the requested year, month and day YYYYMMDD as -sysparm value.
That value becomes available in the SAS program as a macro variable reference &sysparm.
We also use a pre-created data template PARMSDL.DATA_TEMPLATE - a zero-observations data set that contains descriptions of all the variables and their attributes (see Simplify data preparation using SAS data templates).
Shell script running the whole process in parallel
Below shell script month_parallel_driver.sh puts everything together. It spawns and runs concurrently as many daily processes as there are days in a specified month-of-year and synchronizes all single day processes (threads) at the end by waiting them all to complete. It logs all its treads and calculates (and prints) the total processing duration. As you can see, shell script as a programming language is a quite versatile and powerful. Here it is:
#!/bin/sh # HOW TO RUN: # cd /projpath/scripts # nohup sh month_parallel_driver.sh YYYYMM & # Project path proj=/projpath # Program file name prgm=oneday pgmname=$proj/programs/$prgm.sas # Current date/time stamp now=$(date +%Y.%m.%d_%H.%M.%S) echo 'Start time:'$now # Reset timer SECONDS=0 # Get YYYYMM as the script parameter par=$1 # Extract year and month from $par y=${par:0:4} m=${par:4:2} # Get number of days in month $m of year $y days=$(cal $m $y | awk 'NF {DAYS = $NF}; END {print DAYS}') # Create log directory logdir=$proj/saslogs/${prgm}_${y}${m}_${now}_logs mkdir $logdir # Loop through all days of month $m of year $y for i in $(seq -f "%02g" 1 $days) do # Assign log name for a single day thread logname=$logdir/${prgm}_${y}${m}_thread${i}_$now.log # Run single day thread /SASHome/SASFoundation/9.4/sas $pgmname -log $logname -sysparm $par$i & done # Wait until all threads are finished wait # Calculate and print duration end=$(date +%Y.%m.%d_%H.%M.%S) echo 'End time:'$end hh=$(($SECONDS/3600)) mm=$(( $(($SECONDS - $hh * 3600)) / 60 )) ss=$(($SECONDS - $hh * 3600 - $mm * 60)) printf " Total Duration: %02d:%02d:%02d\n" $hh $mm $ss echo '------- End of job -------' |
This script is self-described by detail comments and can be run as:
cd /projpath/scripts
nohup sh month_parallel_driver.sh YYYYMM &
Here we pass a single parameter YYYYMM indicating year-month of our request.
When run, this script will create a separate date-time stamped SAS log file for each thread, i.e. there will be as many log files created as there are days in the month-year for which data is ingested.
Results
The results were as expected as they were stunning. The overall duration was cut roughly by a factor of 25, so now this whole task completes in about two minutes vs. one hour before. Actually, now it is even fun to watch how SAS logs and output data sets are being updated in real time.
What is more, this script-centric approach can be used for running not just SAS processes, but non-SAS, open source and/or hybrid processes as well. This makes it a powerful amplifier and integrator for heterogeneous software applications development.
SAS Consulting Services
The solution presented in this post is a stripped-down version of the original production quality solution. This better serves our educational objective of communicating the key concepts and coding techniques. If you believe your organization’s computational powers are underutilized and may benefit from a SAS Consulting Services engagement, please reach out to us through your SAS representative, and we will be happy to help.
Additional resources
- How to conditionally terminate a SAS batch flow process in UNIX/Linux
- Running SAS programs in batch under Unix/Linux
- Let SAS write batch scripts for you
- Running SAS programs in parallel using SAS/CONNECT®
Thoughts? Comments?
Do you find this post useful? Do you have processes that may benefit from parallelization? Please share with us below.

18 Comments
This is very helpful.
Glad it hear it, John! Thank you for your feedback.
Great blog on shell scripts.
Thank you 😊
Thank you, Deborah, for your feedback!
Leonid,
Great article! One observation, if I may?
You can run parallel processing in Base SAS (no Connect) by using SYSTASK too. As long as the XCMD in turned-on on your machine (local or server).
I did some small tutorial about it some time ago, it is all available at:
https://pages.mini.pw.edu.pl/~jablonskib/SASpublic/Parallel-processing-in-BASE-SAS.sas
and discussed it at communities.sas.com post too:
https://communities.sas.com/t5/SAS-Programming/SAS-Parrallel-Processing/m-p/699295#M213925
All the best
Bart
Thank you, Bart, for your comment and sharing your implementation. Sure, there are many ways to run it in parallel, and using SYSTASK is one of them, and it is well justified for many scenarios. The main feature there is that SAS is in the driver seat and is responsible for spawning secondary parallel sessions.
In this post, however, I offer an alternative, non-SAS-centric approach, with an emphasis on scripting language which is also capable of spawning the treads, with SAS taking care of each single thread only. I believe such a variety will empower SAS (and non-SAS) developers by providing yet another implementation tool.
100% agree! Shell scripting helps a lot. I was using such approach many times under Linux or UNIX. If you combine it with scheduler like Crontab you will get a super-combo.
B-)
👍
Leonid,
Nice blog post! Thanks for the cogent use case and explanation. As a slight alternative to your approach, for those that might want to constrain resource usage on a shared machine, your shell script can be modified to use the xargs command to implement a process pool (akin to a thread pool) and limit the number of concurrent processes running SAS jobs.
Your approach will run as many processes as there are days in the month, yes? It sounds like that is producing good parallelism. The approach , however, might overwhelm the machine if the number of SAS jobs and processes is larger. To restrict the number of processes, you can replace the for loop and wait command with a call to xargs, for which the number of concurrent processes can be set. Specifically, replace the code from "for i in" through "wait" with something like this:
and then create a new script "month_parallel_worker.sh" like this:
Here, the number of processes is limited to 5 but this can be easily varied.
Thank you, Scott, for your truly constructive feedback. Indeed, I used the simplest, unrestricted parallelization which was quite suitable for the described use case. Plus, it is very fitting for explaining and illustrating the idea of using scripting language for running multiple processes in parallel. However, I can envision other scenarios where setting a limit on the number of parallel processes might be warranted. Your proposed solution gives more flexibility and control to developers. It perfectly expands and complements the one described in this post and brings it to the whole new level. Very nice and educational addition which, I am sure, our readers will appreciate.
Hi Leonid. Super interesting topic, which will probably help a lot of customers. I wonder if this would be equally possible on a windows server, say windows server 2016, where you can run PowerShell jobs pretty much like the & jobs you mention in Linux, and background jobs are possible with PS. Seeing this blog on Microsoft.com makes me hopeful it might; then your customers on both platforms could benefit from the tremendous reduction in runtime. https://devblogs.microsoft.com/scripting/parallel-processing-with-jobs-in-powershell/
Thanks for your great work!
Asger
Thank you, Asger, for bringing this up. I have not tested it in Windows, but I expect this can be done there as well.
Excellent one. Thanks for explaining in a very clear and concise manner.
Thank you, Kiran. I am glad it came across as "clear and concise".
Leonid, elegant use case and illustration of offloading heavy-lifting to the OS!
Thank you, Tom! As long as we embrace OS as our friend and not just an "environment" we are much better off.
Leonid,
Leonid,
This is another very clever blog post that I am going to pass along to my colleagues.
This is another very clever blog post that I am going to pass along to my colleagues.
I am sure that they will be able to use it.
I am sure that they will be able to use it.
data _null_;
set SASHELP.AIR (keep=);
put 'Thank you, Michael!';
run;