A client recently asked if there's a programmatic way to reduce memory requirements of a CAS table. In this post, you'll learn how to accomplish that when your SASWORK data set has lengthy character data.
Note: for the coding techniques in this blog to work the CAS controller must have access to the path SASWORK is using.
What is SASWORK?
The SASWORK library is the temporary library automatically defined by SAS at the start of each SAS session or job. The SASWORK library stores temporary SAS files that you create, such as data sets, catalogs, formats, etc., as well as files created internally by SAS. To access files in the SASWORK library, specify a one-level name for the file or by using a two-level name, i.e. the WORK libref.
How to programmatically create a CASLIB to SASWORK
It is a common practice for SAS programmers to read a source table and then store that source table in SASWORK. When the SASWORK data set has long character data, you can significantly reduce memory requirements by creating a path-based CASLIB to SASWORK and leveraging PROC CASUTIL with the CASDATA= option and use the IMPORTOPTIONS VARCHARCONVERSION=16 statement. The VARCHARCONVERSION=16 statement automatically converts all character data types with length of 16 or greater to a VARCHAR data type.
Code in Figure 1 below creates a macro variable called WORKPATH which we will use in our CASLIB statement:
/* The macro variable WORKPATH contains the path to SASWORK */ %let workpath = %sysfunc(quote(%sysfunc(pathname(work)))); %put &workpath; |
(Figure 1: Creating the Macro Variable WORKPATH)
Figure 2 below is the resulting SAS log:

(Figure 2: SAS log of creating the Macro Variable WORKPATH)
Code in Figure 3 below creates our SASWORK data set that we will lift into CAS:
data saswork_table_with_char300; length a $ 300 b $ 15 c $ 16; a='a300'; b='b15' ; c='c16' ; output; a='a300300'; b='b151515'; c='c161616'; output; c='c161616161616161'; b='b15151515151515'; a="a300qzwsxedcrfvtgbyhnujmiklopqazwsxedcrfvtgbyhnujmikolp1234567890123456789012345678901234567890"; output; run; proc contents data=saswork_table_with_char300; title "Contents of WORK.SASWORK_TABLE_WITH_CHAR300"; run; |
(Figure 3: Code to create a SASWORK data set using a one-level name, i.e. saswork_table_with_char300)
Notice in Figure 4 below the lengths of the character variables a, b, and c:
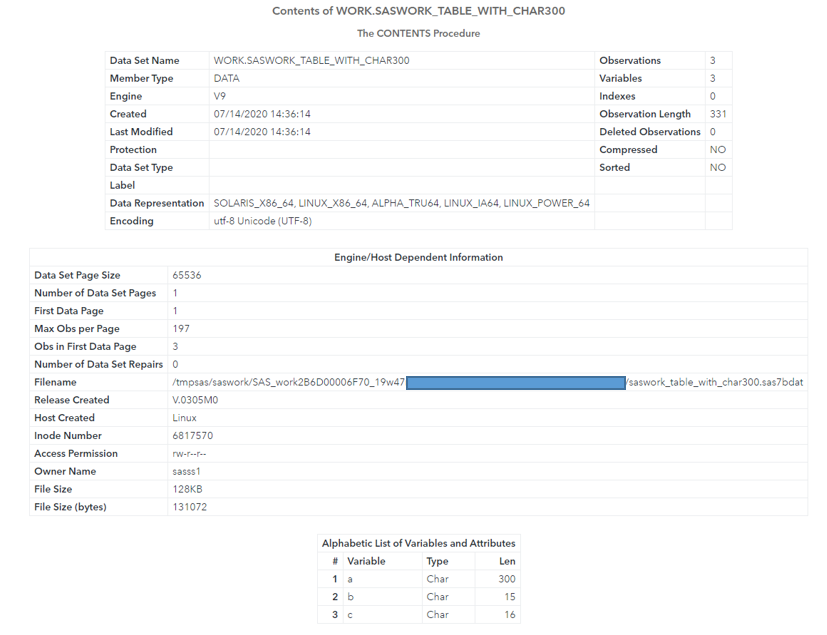
(Figure 4: Results from PROC CONTENTS)
Code in Figure 5 below creates a path-based CASLIB to SASWORK by using our macro variable WORKPATH:
proc cas; file log; table.dropCaslib / caslib='sas7bdat' quiet = true; run; addcaslib / datasource={srctype="path"} name="sas7bdat" path=&workpath ; run; |
(Figure 5: Path-based CASLIB to SASWORK)
Figure 6 below is resulting SAS log:
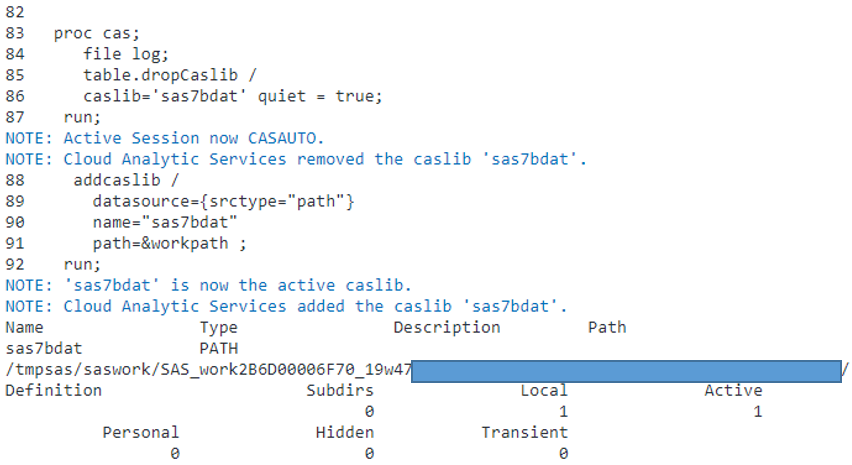
(Figure 6: SAS log of path-based CASLIB to SASWORK)
Code in Figure 7 below lifts the SASWORK data set into CAS and ensures the CAS table will contain VARCHAR data types for any character data with a length of 16 or greater:
proc casutil; load casdata="saswork_table_with_char300.sas7bdat" casout="cas_table_with_varchar" outcaslib="casuser" importoptions=(filetype="basesas", dtm="auto", debug="dmsglvli", varcharconversion=16) ; run; quit; |
(Figure 7: code that lifts the SASWORK data set into CAS)
Figure 8 below is the resulting SAS log:
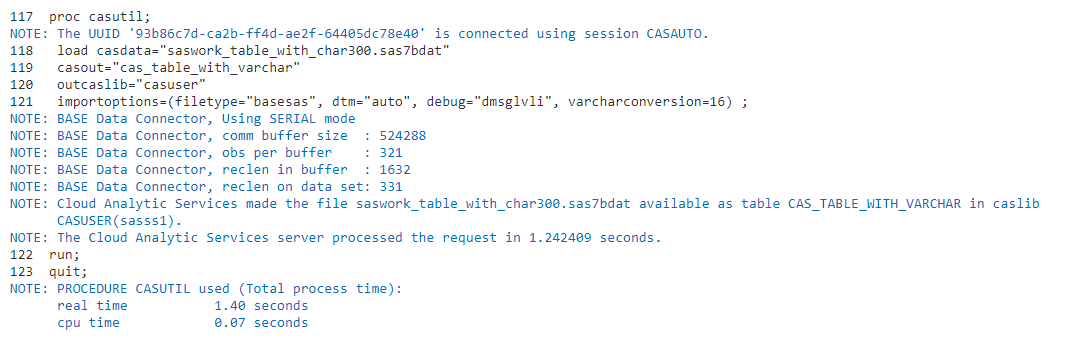
(Figure 8: SAS log of code to lift the SASWORK data set into CAS)
Code in Figure 9 below displays the characteristics of our CAS table “cas_table_with_varchar”: Notice in Figure 10 that our variables a and c have a data type of VARCHAR.
proc cas; sessionProp.setSessOpt / caslib="casuser"; run; table.columninfo / table="cas_table_with_varchar"; quit; |
(Figure 9: SAS code to display information of a CAS table)
Figure 10 below reveals CAS table characteristics:
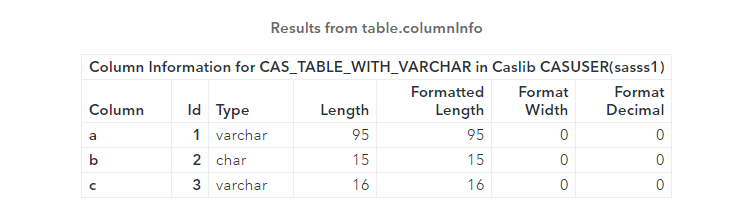
(Figure 10: CAS table characteristics)
Conclusion: Conserve memory with smaller CAS tables
By leveraging the coding techniques in this blog, we can lift into CAS any data sets we previously stored in SASWORK. In addition, we convert all character data types with a length of 16 or greater into the VARCHAR data type, which can significantly reduce the size of our CAS tables.
LEARN MORE | SAS® Cloud Analytic Services 3.5: User’s Guide
6 Comments
Thank you for the clarification, Steve. I am not sure it would be wise to install a SPRE Foundation with its own requirements (I/O, CPU) alongside a CAS Controller which would compete for the CAS (licensed) CPU, for instance but I am no specialist in this regard. Either , I think It wouln't be any wiser to expose the SASWORK filesystem over some NFS shared filesystem, surely, as R&D (Cf. Maragaret CREVAR team storage recommendations ) has repeatedly told us. This leaves us on Linux with few options left. Why would the loading through JSON/RestFUL be so inefficient, could you please elaborate - maybe in a future post ? I consulted this post (https://communities.sas.com/t5/SAS-Communities-Library/SAS-Viya-CAS-REST-API-How-to-fetch-a-table/ta-p/600023) which displays the capability to leverage the Viya RestFul API , and SAS 9.4 M4+ comes with a JSON translator (Cf. https://blogs.sas.com/content/sasdummy/2016/12/02/json-libname-engine-sas/ ) which looks very handy too.
All the best
Ronan
Thanks for sharing ! This works either with a single machine deployment , or if the SPRE session and CAS controller share the same machine. (?) In any other case - when SPRE and CAS are separate - I wonder if a sas 9 table converted to JSON couldn't be sent over http via Proc Http to CAS using RestFul API ?
Thank you for your comment Ronan. Yes, this technique works with a single-machine deployment as well as a deployment with multiple CAS worker nodes. For this coding technique to work the CAS controller must have access to the path used by SASWORK. Note, if the CAS controller and all CAS worker nodes have access to the path used by SASWORK then parallel data transfer mode to CAS will be used.
For your second comment I need to do a little research before commenting.
Thanks again for your comments,
Steve
Ronan, while it is possible to convert the SASWORK data set into JSON and then use a REST API to load it into CAS, that would be inefficient. It would be more efficient using the techniques I describe in this blog instead.
Thanks again for your comments,
Steve
This only works if the CAS controller has access to the _same_ directory, and using the same path, as your MVA SAS process (/tmpsas/saswork, in your example) though NFS mounts on one side or the other (or both). If your SASWORK is in /tmp, for example, you can create a caslib to /tmp, but it won't have your SASWORK In it. Likewise, if you're running on Windows, your SASWORK is likely in c:\temp or some such, which CAS won't understand (unless you're running SMP CAS on the same PC as SAS).
Now, if you can access a directory from your CAS and your MVA SAS, you can point both a libname and a caslib to it, and use the other techniques you mention.
Thank you for your comment Gordon. You are correct, for this technique to work the CAS controller must have access to the path that SASWORK is using. In the SAS Log, (figure 8), we can see that SERIAL data transfer mode was used in lifting the SASWORK table into CAS. That implies only the CAS controller has access to the path that SASWORK is using. To achieve parallel data transfer mode to CAS, all of the CAS worker nodes in addition to the CAS controller would need access to the path used by SASWORK. For SAS Viya running on Windows we only support a single-machine deployment which implies the CAS controller will have access to the path used by SASWORK.
Thanks again for your comments,
Steve