One day, I received a question from the SAS community on how to exclude variables with missing values up to a certain percentage in data analysis. Before I dive into details, another question about how to remove variables with repeated values up to a certain percentage was raised. In fact, this user demands focus on the value characteristics for a single variable, and it determines if the user should include a specific variable in the following data analysis. It reflects the demand of variable selection for wide datasets with noise; it enhances data filtering by enabling variables(cols) selection, in addition to the normal observation(rows) filtering.
DATA Step implementation
If the variable filtering is based on the percentage of the missing values, the most intuitive thought is to use DATA step to calculate the percentage of missing values for each column of the input dataset, and then collect the variable names that meet the threshold conditions before passing them to a global macro variable for subsequent analysis. Since SAS DATA step includes both character and numeric data types, we cannot define one single array to map all columns of the dataset. Instead, we need to define two arrays to map all numeric variables and all character variables respectively.
In order to build a universal reusable SAS macro, we also need to detect the number of numeric and character variables in advance and pass them to the array definition in the next DATA step. In that DATA step, we use two arrays to access dataset variables and count the number of missing values respectively. When the loop reaches the last observation, it collects variable names through the vname() function which meet the threshold condition, and finally place them into a SAS global macro variable &VARLIST. The SAS macro below demonstrates this logic:
%macro FilterCols(data=, th=0, varlist=); data _null_; /*get numeric and character variables count */ set &data (obs=1); array _ncols_n _numeric_; array _ccols_n $ _character_; call symput ('_ncols_n',put(dim(_ncols_n),best.)); call symput ('_ccols_n',put(dim(_ccols_n),best.)); run; data _null_; set &data end=last; /*Process numeric types*/ array _ncols_ _numeric_; array _ncols_count {&_ncols_n}; retain _ncols_count (&_ncols_n*0); do i=1 to dim(_ncols_); if _ncols_[i]= . then _ncols_count[i]=_ncols_count[i] + 1; end; /*Process character types*/ array _ccols_ $ _character_; array _ccols_count {&_ccols_n}; retain _ccols_count (&_ccols_n*0); do i=1 to dim(_ccols_); if _ccols_[i]=" " then _ccols_count[i]=_ccols_count[i]+1; end; /*Filter out the variables meet the conditions and place them in the &VARLIST global macro variable*/ if last then do; length _varlist_ $ 32767; retain _varlist_ " "; do i=1 to &_ncols_n; if (_ncols_count[i]/_N_) >= &th then do; _varlist_=trim(_varlist_) || " " || trim( vname(_ncols_[i]) ); end; end; do i=1 to &_ccols_n; if (_ccols_count[i]/_N_) >= &th then do; _varlist_=trim(_varlist_) || " " || trim( vname(_ccols_[i]) ); end; end; call symput ("&VARLIST",trim(_varlist_)); end; run; %mend; /*Exclude variables if missing value pct GE. threshold &th*/ %macro FilterData(data=, th=, out=); %global myvars; %FilterCols(data=&data, th=&th, varlist=myvars); data &out; set &data; %if %str(&myvars)^=%str() %then %do; drop &myvars; %end; run; %mend; |
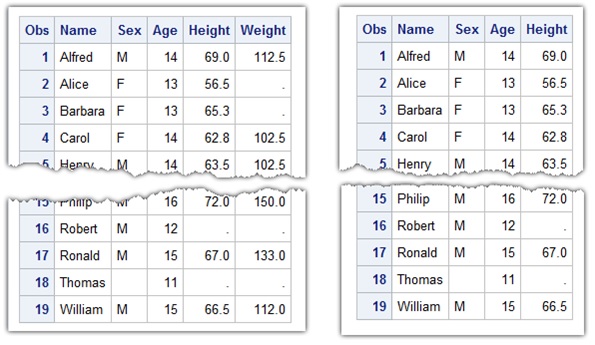
To verify the programing logic, let’s generate a demo dataset WORK.CLASS based on SASHELP.CLASS, the output dataset has different missing value percentage (10.53%, 36.84%, 52.63%) in Sex, Height and Weight columns.
data class; /*To generate demo dataset*/ set sashelp.class; if age < = 11 then sex=" "; if age <= 12 then height=.; if age <= 13 then weight=.; run; proc print data=class; run; /*See Figure 1 for output */ |
Now we can use the following code to filter columns by percentage of missing values, which is greater than 40%; the Weight column will not appear in the output CLASS2 dataset.
%FilterData(data=class, th=0.4, out=class2); proc print data=class2; run; /*See Figure 1 for output */ |
The calculation here for the percentage of missing values is implemented by the user programming in the DATA step. The missing value count is computed separately in two arrays according to the character type and the numerical type. If you want to do it in a single array, you must use HASH object to store the variable name and its corresponding index in that array. Whenever a missing value is detected, we need to check whether the variable is already in the HASH object; if not, then add it directly. Otherwise, look up the table to find the appropriate array index, and then increase the counter to the corresponding element in that array. The advantage of this approach is we only need one array in later variable names collecting phase. The disadvantage is the use of HASH object increases the programming complexity. The complete implementation based on this logic is as follows, it can completely replace the first version of %FilterCols implementation.
%macro FilterCols(data=, th=0, varlist=); data _null_; /*Detect variable numbers of dataset*/ dsid=open("&data.",'i'); if dsid>0 then do; nvars= attrn(dsid, 'NVARS'); call symput("NVARS", nvars); end; run; data _null_; set &data. end=last; /*Define 2 arrays map to numeric/character vars respectively*/ array _ncols_ _numeric_; array _ccols_ _character_; if _N_=1 then do; /*HASH Object definition and initialize*/ length key $ 32; declare hash h(); rc=h.definekey("key"); rc=h.definedata("data", "key"); rc=h.definedone(); call missing(key, data); end; /*Define one array for counting of missing value*/ array _cols_count[&NVARS] _temporary_; retain _cols_count ( &NVARS * 0); retain _col_id_ 1; do i=1 to dim(_ncols_); if missing( _ncols_[i] ) then do; /*Find mapped array index and modify counter value*/ key=vname( _ncols_[i] ); if h.find()^=0 then do; data=_col_id_; h.add(); _col_id_=_col_id_+1; end; _cols_count[ data ] = _cols_count[ data ] +1; end; end; do i=1 to dim(_ccols_); if missing( _ccols_[i] ) then do; /*Find mapped array index and modify counter value*/ key=vname( _ccols_[i] ); if h.find()^=0 then do; data=_col_id_; h.add(); _col_id_=_col_id_+1; end; _cols_count[ data ] = _cols_count[ data ] +1; end; end; /*Filter out the variables meet the conditions and place them in the &VARLIST global macro variable*/ if last then do; declare hiter iter('h'); rc = iter.first(); do while (rc = 0); pct=_cols_count[data]/ _N_; if pct >= &th. then do; length _varlist_ $ 32767; retain _varlist_ " "; _varlist_=trim(_varlist_) || " "|| trim(key); end; rc = iter.next(); end; call symput( "&VARLIST", trim( left(_varlist_))); end; run; %mend; |
PROC FREQ Implementation
In the two macros above, the counting of missing values for each column are implemented by user programming in DATA step, but SAS provides a more powerful frequency statistic step called PROC FREQ. Can we directly use its output for variable filtering? The answer is YES. For example, the following SAS code can list the Frequency, Percent, Cumulative Frequency, and Cumulative Percent of each variable values (including missing values) in the data set.
proc freq data=class; table Sex Height Weight /missing; /*See Figure 2 for output */ run; |

To get the result of PROC FREQ into a dataset, we just need to add ODS Table statement before running PROC FREQ:
ods table onewayfreqs=class_freqdata; |
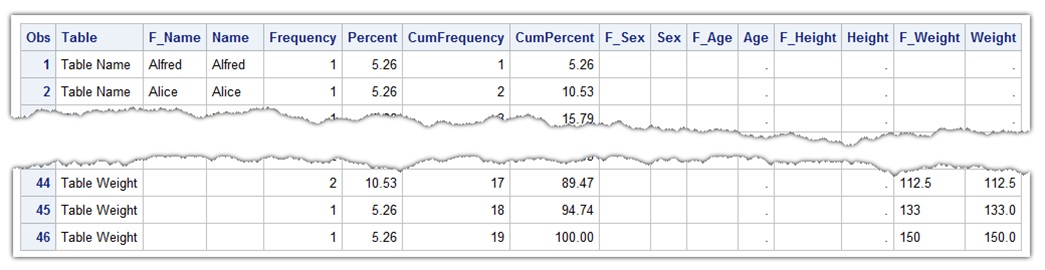
So, the frequency statistics result of PROC FREQ is stored in the class_freqdata dataset. We only need to check the value of variable “percent” for each column. If it is greater than the threshold specified, the variable name is added to the buffer variable _varilist_, otherwise it is ignored; the final value of _varilist_ is placed to the SAS global macro variable &VARLIST for later use. Comparing to the DATA step implementation, the entire code here is much shorter and simpler.
%macro FilterCols(data=, th=0, varlist=); ods table onewayfreqs=&data._freqdata; /*FREQ out to temp dataset*/ proc freq data=&data; table _all_ /missing; run; data _null_; set &data._freqdata end=last; var=scan(Table, 2); if getoption("LOCALE")="ZH_CN" then var=scan(Table, 2, "“”"); value=vvaluex(var); /*Filter out the variables meet the conditions and place them in the &VARLIST global macro variable*/ if value=" " or compress(value)="." then do; if percent/100>= &th then do; length _varlist_ $ 32767; retain _varlist_ " "; _varlist_=trim(_varlist_) || " "|| trim(var); put var= _varlist_; end; end; if last then call symput( "&VARLIST", trim( left(_varlist_))); run; /*Delete the temp dataset in WORK library*/ proc datasets nolist; delete &data._freqdata; quit; %mend; |
Please note that PROC FREQ would generate output to ODS HTML destination by default. If you want to avoid generating ODS HTML output when generating the temporary dataset “class_freqdata”, you can use the ods html close; statement to temporarily close the ODS HTML output and then open it again anytime needed.
Since the output of PROC FREQ already has the frequency information of each variable, we can naturally filter columns based on the percentage of duplicate values. However, it should be noted that a single variable always contains multiple distinct values, and each distinct value (including missing values) has a frequency percentage. If percentage of duplicate value is too high in a specific column, the user may exclude that column from the following analysis. As there are multiple frequency percentages, we just choose the largest one as the duplicate value percentage of that variable. For example, the Sex column of demo dataset CLASS has a missing value of 10.53%, a female of 42.11% and a male of 47.37%, so the percentage of duplicate values in the Sex column should be 47.37%.
The following code filter variables by percentage of duplicate values with a specific threshold. The code logic is almost same as before, but it filters values with non-missing values. So, run the same test code against the demo dataset will remove the Age column by duplicate values percentage threshold, instead of the Weight column by missing values percentage threshold.
%macro FilterCols(data=, th=0, varlist=); ods table onewayfreqs=&data._freqdata; /*FREQ out to temp dataset*/ ods html close; proc freq data=&data; table _all_ / missing; run; ods html; data _null_; set &data._freqdata end=last; var=scan(Table, 2); if getoption("LOCALE")="ZH_CN" then var=scan(Table, 2, "“”"); value=vvaluex(var); /*Filter out the variables meet the conditions and place them in the &VARLIST global macro variable*/ if ^(value=" " or compress(value)=".") then do; if percent > maxpct then do; /*Search max percentage of duplicate values of a variable*/ retain maxpct 0; retain maxvar; maxpct=percent; maxvar=var; end; if (_N_>1 and var ^= lastvar) or last then do; if maxpct/100 >= &th. then do; length _varlist_ $ 32767; retain _varlist_ " "; _varlist_=trim(_varlist_) || " "|| trim(maxvar); end; maxpct=percent; maxvar=var; end; lastvar=var; retain lastvar; end; if last then call symput( "&VARLIST", trim( left(_varlist_))); run; /*Delete the temp dataset in WORK library*/ proc datasets nolist; delete &data._freqdata ; quit; %mend; |
In order to combine these two logics of by missing values and by duplicate values in one macro, we just introduce one flag parameter byduprate. The default value is 0 to filter variables by missing values, and value 1 to filter variables by duplicate values. The complete code is as below:
%macro FilterCols(data=, th=0, varlist=, byduprate=0); ods table onewayfreqs=&data._freqdata; /*FREQ out to temp dataset*/ ods html close; proc freq data=&data; table _all_ /missing; run; ods html; data _null_; set &data._freqdata end=last; var=scan(Table, 2); if getoption("LOCALE")="ZH_CN" then var=scan(Table, 2, "“”"); value=vvaluex(var); %if &byduprate=0 %then %do; /*Filter variables by missing value*/ if value=" " or compress(value)="." then do; if percent/100>= &th then do; length _varlist_ $ 32767; retain _varlist_ " "; _varlist_=trim(_varlist_) || " "|| trim(var); end; end; %end; %else %do; /*Filter variables by duplicate value percentage*/ if ^(value=" " or compress(value)=".") then do; if percent > maxpct then do; retain maxpct 0; retain maxvar; maxpct=percent; maxvar=var; end; if (_N_>1 and var ^= lastvar) or last then do; if maxpct/100 >= &th. then do; length _varlist_ $ 32767; retain _varlist_ " "; _varlist_=trim(_varlist_) || " "|| trim(maxvar); end; maxpct=percent; maxvar=var; end; lastvar=var; retain lastvar; end; %end; if last then call symput( "&VARLIST", trim( left(_varlist_))); run; /*Delete the temp dataset in WORK library*/ proc datasets nolist; delete &data._freqdata; quit; %mend; |
Accordingly, we also need to introduce the parameter byduprate with the same name and behavior in the %FilterData macro that's invoking the %FilterCols macro. The SAS macro %FilterData also has the same default value 0, but it needs to pass the byduprate argument specified by the user to the %FilterCols macro. The enhanced version is as below:
%macro FilterData(data=, th=, out=, byduprate=0); %global myvars; %FilterCols(data=&data, th=&th, varlist=myvars, byduprate=&byduprate); data &out; set &data; %if %str(&myvars)^=%str() %then %do; drop &myvars; %end; run; %mend; |
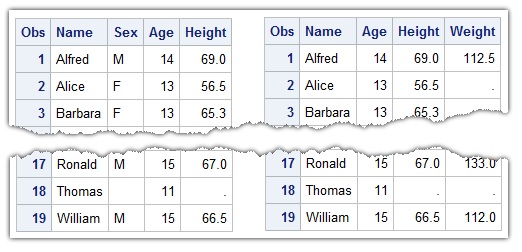
Now the final version of the macro %FilterData unified the two kinds of variable filtering logic, it just depends on the different value of the argument byduprate: If byduprate is not specified or the value is 0, it means filter variables by the percentage of missing values, otherwise it is by the percentage of duplicate values. For the following two code snippets, the former drops the Weight column, while the latter drops the Sex column.
/*Drop columns with missing value percentage >= 40% */ %FilterData(data=class, th=0.4, out=class2); proc print data=class2;run; /*Drop columns with duplicate value percentage >= 40% */ %FilterData(data=class, th=0.4, out=class3, byduprate=1); proc print data=class3;run; |
Summary
This article discusses how to use SAS to filter variables in a dataset based on the percentage of missing values or duplicate values. The missing value statistics can be implemented by either DATA step programming on your own or reusing the existing powerful PROC FREQ with statistics result for missing values and duplicate values. The five macros in this article also demonstrated how to wrap up the existing powerful SAS analytics as a reusable, general-purpose SAS macro for a big project. The final version of macro %FilterData also demonstrated how to unify filtering variables by the percentage of either missing values or duplicate values in one to make calling SAS macro functions convenient and easy to reuse. To learn more, please check out these resources:
