Mirror, mirror on the wall, whose conference presentations are the best of all?
Ok, well it doesn’t quite go that way in the fairy tale, but remakes and reimagining of classic tales have been plentiful in books (see The Shadow Queen), on the big screen (see Maleficent, which is about to get a sequel), on the little screen (see the seven seasons of Once upon a Time) and even on stage and screen (see Into the Woods). So, why not take some liberties in the service of analytics?
For this blog post, I have turned our analytics mirror inward and gazed at the social media messages from four SAS conferences: SAS Global Forum 2018 in Denver, Analytics Experience 2018 in San Diego, Analytics Experience 2018 in Milan, and the 2019 Analyst Conference in Naples. While simply counting retweets could provide insight into what was popular, I wanted to look deeper to answer the question: What SAS conference presenters were most praised in social media and how? Information extraction, specifically fact extraction, could help with answering those questions.
Data preparation
Once upon a time, in a land far far away, there was a collection of social media messages, mostly Tweets, that the SAS social media department was kind enough to provide. I didn’t do much in terms of data preparation. I was only interested in unique messages, so I used Excel to remove duplicates based on the “Message” column.
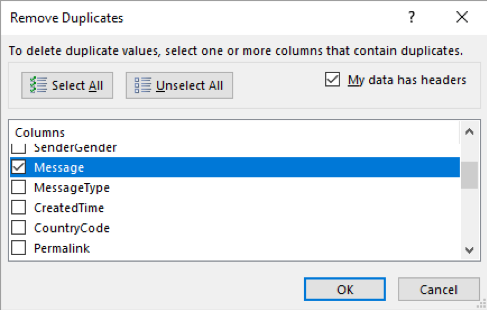
Additionally, I kept only messages for which the language was listed as English, using the “language” column that was already provided in the data. SAS Text Analytics products support 33 languages, but for the purposes of this investigation I chose to focus on English only because the presentations were in English. Then, I imported this data, which was about 4,400 messages, into SAS Visual Text Analytics to explore it and create an information extraction model.
While exploring the data, I noticed that most of the tweets were in fact positive. Additionally, negation, such as “not great” for example, was generally absent. I took this finding into consideration while building my information extraction model: the rules did not have to account for negation, which made for a simpler model. No conniving sorcerer to battle in this tale!
Information extraction model
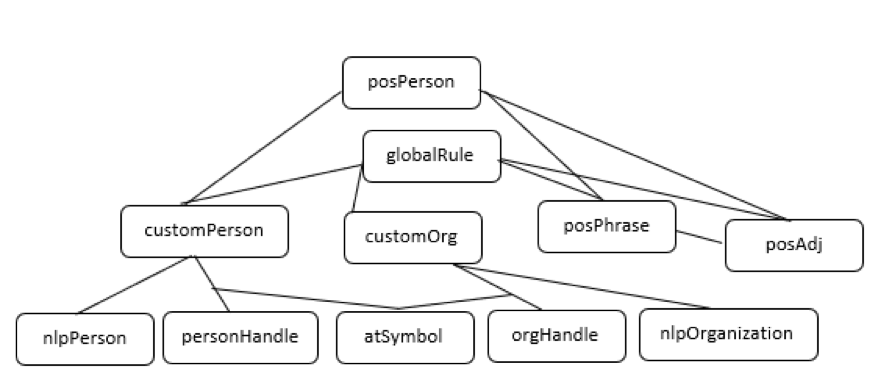
The magic wand here was SAS Visual Text Analytics. I created a rather simple concepts model with a top-level concept named posPerson, which was extracting pairs of mentions of presenters and positive words occurring within two sentences of the mentions of presenters. The model included several supporting concepts, as shown in this screenshot from SAS Visual Text Analytics concepts node.

Before I explain a little bit about each of the concepts, it is useful to understand how they are related together in the hierarchy represented in the following diagram. The lower-level concepts in the diagram are referenced in the rules of the higher-level ones.
Extending predefined concepts
The magic wand already came with predefined concepts such as nlpPerson and nlpOrganization (thanks, fairy godmother, ahem, SAS linguists). These concepts are included with Visual Text Analytics out of the box and allow users to tap into the knowledge of the SAS linguists for identifying person and organization names. Because Twitter handles, such as @oschabenberger and @randyguard, are not included in these predefined concepts, I expanded the predefined concepts with custom ones. The custom concepts for persons and organizations, customPerson and customOrg, referenced matches from the predefined concepts in addition to rules for combining the symbol @ from the atSymbol concept and various Twitter handles known to belong to persons and organizations, respectively. Here is the simple rule in the atSymbol concept that helps to accomplish this task:
CLASSIFIER:@ |
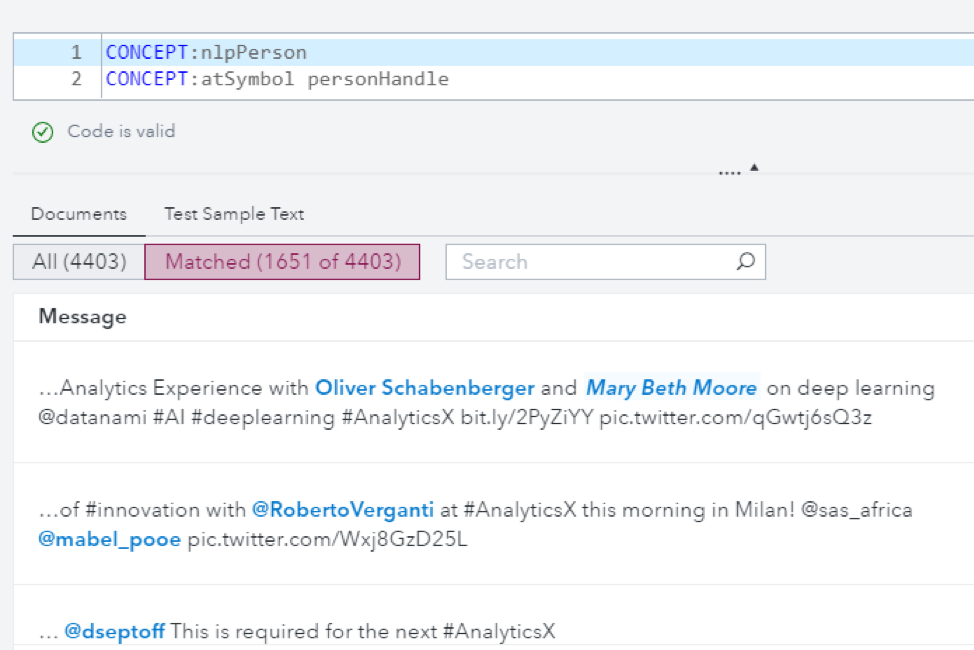
The screenshot below shows how the atSymbol concept and the personHandle concept are referenced together in the customPerson concept rule and produce matches, such as @RobertoVerganti and @mabel_pooe. Note also how the nlpPerson concept is referenced to produce matches, such as Oliver Schabenberger and Mary Beth Moore, in the same customPerson concept.
If you are interested to learn more about information extraction rules like the ones used in this blog, check out the book SAS Text Analytics for Business Applications: Concept Rules for Information Extraction Models, which my colleagues Teresa Jade and Michael Wallis co-authored with me. It’s a helpful guide for using your own magic wand for information extraction!
Exploratory use of the Sandbox
Visual Text Analytics also comes with its own crystal ball: the Sandbox feature. In the Sandbox, I refined the concept rules iteratively and was able to run the rules for each concept faster than running the entire model. Gazing into this crystal ball, I could quickly see how rule changes for one concept impacted matches.
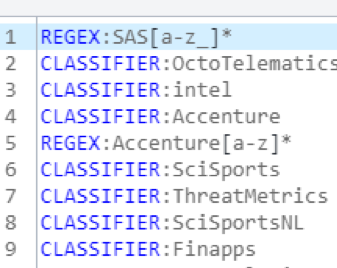
In an exploratory step, I made the rules in the personHandle concept as general as possible, using part of speech tags such as :N (noun) and :PN (proper noun) in the definitions. As I explored the matches to those rules, I was able to identify matches that were actually organization handles, which I then added as CLASSIFIER rules to the orgHandle concept by double-clicking on a word or phrase and right-clicking to add that string to a rule.

I noticed that some handles were very similar to each other and REGEX rules more efficiently captured the possible combinations. Consult the book referenced above if you’re interested in understanding more about different rule types and how to use them effectively. After moving the rules to the Edit Concept tab, the rules for orgHandle included some of the ones in the following screenshot.
Automatic concept rule generation
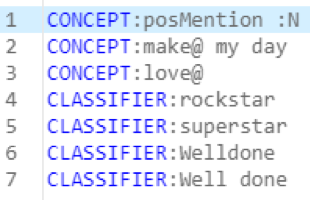
Turning now to the second part of the original question, which was what words and phrases people used to praise the presenters, the answers came from two custom concepts: posAdj and posPhrase. The posAdj concept had rules that captured adjectives with positive sentiment, such as the following:

Most of these were captured from the text of the messages in the same manner as the person and organization Twitter handles.
But, the first two were created automatically by way of black magic! When I selected a term from the Textual Elements, as you can see below for the term “great”, the system automatically created the first rule in the concept above, including also the comparative form, “greater,” and the superlative, “greatest.” This is black magic harnessing the power of stemming or lemmatization.
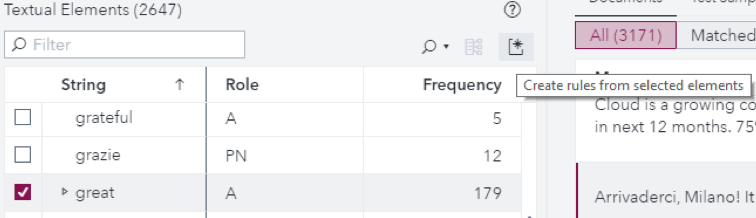
The concept posPhrase built onto the posAdj concept by capturing the nouns that typically follow the adjectives in the first concept as well as a few other strings that have a positive connotation.
Filtering with global rules
Because the rules created overlapping matches, I took advantage of a globalRule concept, which allowed me to distinguish between the poisoned apples and the edible ones. Global rules served the following purposes:
- to remove matches from the more generally defined customPerson concept that were also matched for the customOrg concept
- to remove matches from the posAdj concept (such as “good”) that were also matched in the posPhrase concept (such as “good talk”)
- to remove false positives
As an example of a false positive, consider the following rule:
REMOVE_ITEM:(ALIGNED, "Data for _c{posAdj}", "Data for Good") |
Because the phrase “Data for Good” is a name of a program, the word “good” should not be taken into consideration in evaluating the positive mention. Therefore, the REMOVE_ITEM rule stated that when the posAdj concept match “good” is part of the phrase “Data for Good,” it should be removed from the posAdj concept matches.
Automatic fact rule generation
The top-most concept in the model, posPerson, took advantage of a magic potion called automatic fact rule building, which is another new feature added to the Visual Text Analytics product in the spring of 2019. This feature was used to put together matches from the posAdj and posPhrase concepts with matches from the customPerson concept without constructing the rule myself. It is a very useful feature for newer rule writers who want to explore the use of fact rules.
As input into the cauldron to make this magic potion, I selected the posAdj and customPerson concepts. These are the concepts I wanted the system to relate as facts.

I ran the node and inspected the autogenerated magic potion, i.e. the fact rule.
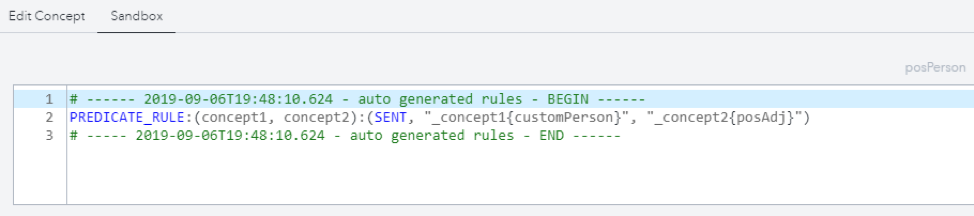
Then I did the same thing with the posPhrase and customPerson concepts. Each of the two rules that were created by Visual Text Analytics contained the SENT operator.
But I wanted to expand the context of the related concepts and tweaked the recipe a bit by replacing SENT with SENT_2 in order to look for matches within two sentences instead of one. I also replaced the names of the arguments, which the rule generation algorithm called concept1 and concept2, with ones that were more relevant to the task at hand, person and pos. Thus, the following rules were created:
PREDICATE_RULE:(person, pos):(SENT_2, "_person{customPerson}", "_pos{posAdj}") PREDICATE_RULE:(person, pos):(SENT_2, "_person{customPerson}", "_pos{posPhrase}") |
Results
So, what did the magic mirror show? Out of the 4,400 messages, I detected a reference to a person in about 1,650 (37%). In nearly 600 of the messages (14%) I extracted a positive phrase and in over 300 (7%) at least one positive adjective. Finally, only 7% (321) of the messages contained both a reference to a person and a positive comment within two sentences of each other.
I changed all but the posPerson and globalRule concepts to “supporting” so they don’t produce results and I can focus only on the relevant results. This step was akin to adjusting the mirror to focus only on the most important things and tuning out the background. You can learn more about this and other SAS Visual Text Analytics features in the User Guide.
Switching from the interactive view to the results view of the concepts node, I viewed the transactional output table.
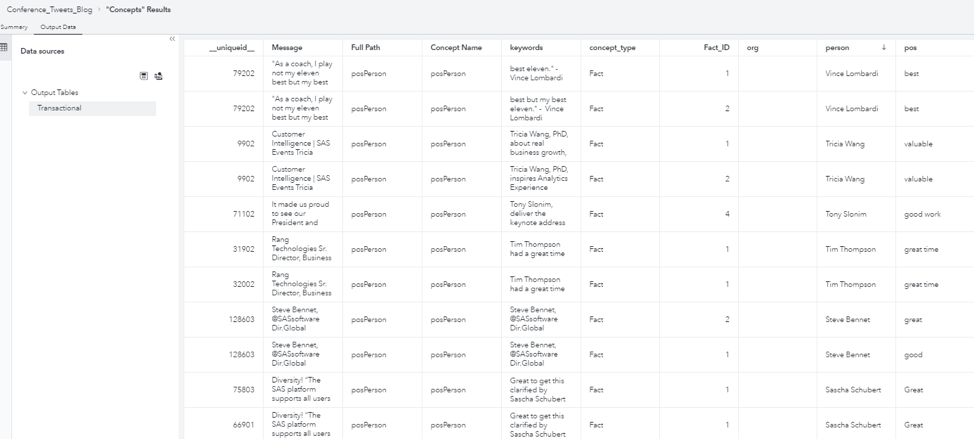
With one click, I exported and opened this table in Visual Analytics in order to answer the questions which presenters were mentioned most often and in the context of what words or phrases with positive sentiment.
Visualization
With all of the magic items and preparation out of the way, I was ready to build a sparkly palace for my findings; that is, a report in Visual analytics. On the left, I added a treemap of the most common matches for the person argument. On the right, I added a word cloud with the most common matches for the pos argument and connected it with the treemap on the left. In both cases I excluded missing values in order to focus on the extracted information. With my trees and clouds in place, I turned to the bottom of the report. I added and connected a list table with the message, which was the entire input text, and keywords, which included the span of text from the match for the first argument to the match for the last argument, for an easy reference to the context for the above visualizations.
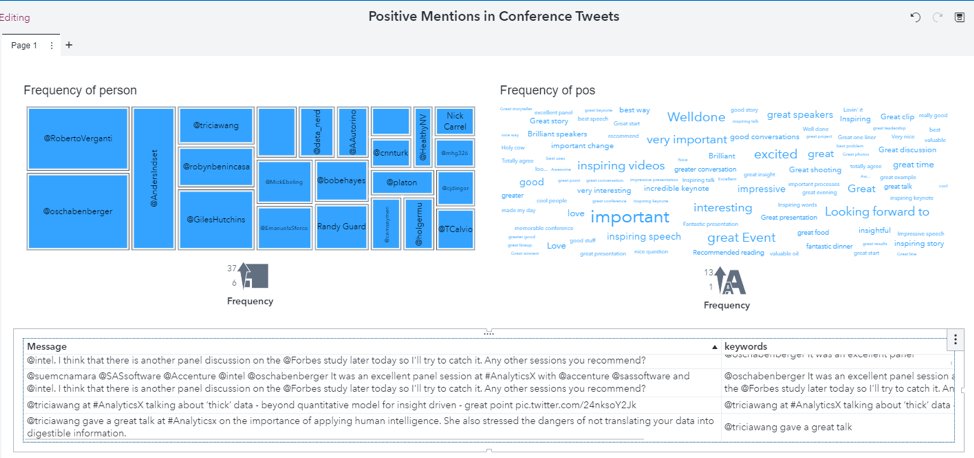
Based on the visualization on the left, the person with the most positive social media messages was SAS Chief Operating Officer (COO), Dr. Oliver Schabenberger, who accounted for 12% of the messages that contained both a person and a positive comment. His lead was followed by the featured presenters at the Milan conference, Roberto Verganti, Anders Indset and Giles Hutchins. Next most represented were the featured presenters at the San Diego conference, Robyn Benincasa and Dr. Tricia Wang.
Looking at the visualization on the right, some of the most common phrases expressing praise for all the presenters were “important,” “well done,” “great event,” and “exciting.” Quite a few phrases also contain the term “inspiring,” such as “inspiring videos,” “inspiring keynote,” “inspiring talk,” “inspiring speech,” etc.
Because of the connections that I set up in Visual Analytics between these visualizations, if I want to look at what positive phrases were most commonly associated with each presenter, I can click on their name in the treemap on the left; as a result, the word cloud on the right as well as the list table on the bottom will filter out data from other presenters. For example, the view for Oliver Schabenberger shows that the most common positive phrase associated with tweets about him was “great discussion.”

Conclusions
It is not surprising that the highest accolades in this experiment went to SAS’ COO since he participated in all four conferences and therefore had four times the opportunity to garner positive messages. Similarly, the featured presenters probably had larger audiences than breakout sessions, allowing these presenters more opportunities to be mentioned in social media messages. In this case, the reflection in the mirror is not too surprising. And they all lived happily ever after.
What tale does your social media data tell?
