This blog shows how the automatically generated concepts and categories in Visual Text Analytics (VTA) can be refined using LITI and Boolean rules. Because of these capabilities highly customized models can be developed in VTA. The rules used in this blog are basic. Developing linguistic rules and accurately categorizing documents requires subject matter expertise and understanding the grammatical structure of the language(s) used.
I will use a data set that contains information on 1527 randomly selected movies: their titles, reviews, MPAA Ratings, Main Genre classifications and Viewer Ratings. Two customized categories will be developed one for Children and the other for Sport movies. Because we are familiar with movies classification and MPAA ratings, it will be relatively easy to understand the rules used in this blog. The overall blog’s objective is to show how to formulate basic rules, thus their use can be extended to other fields.
SAS Visual Text Analytics (VTA) is the SAS offering designed to effectively extract insights from unstructured data in large scale. Offered on the SAS Viya architecture, VTA combines the power of Natural Language Processing (NLP), Machine Learning (ML) and Linguistic Rules. Currently, VTA supports 33 languages and it has an open architecture supporting 3rd-party programming interfaces.
As in all analytical projects, the discovery process in Text Analytics projects requires several iterations where the insights found in one iteration are used in the next iterations. In relationship to the linguistic rules, one must determine if the new rules are an improvement over the ones used in previous iterations, and find how many true positives and false positives are matched by the new rules. This process should be repeated until one obtains the precision required.
Initial Text Analysis Using Visual Analytics
Because Visual Analytics (VA) and VTA are highly integrated, the initial Text Analysis can be done in VA.
Every Text Analytics dataset must have a unique identifier associated to each document. In my blog, Discover Main Topics on #MLKDayofService Tweets Using SAS Visual Text Analytics, I showed how to set a “Unique Row Identifier”, and how to work with the nodes in the Pipeline.
In Visual Analytics (VA) one can do the initial analysis of text data, see the Word Cloud, and a list of topics. In the Options menu, I indicated I wanted a Maximum of Topics to Generate=7.

The photo above shows that there are 364 movies with the term “kid” in the Topic “+show,+kid, +rate,+movie”. We could build a category that groups appropriate movies for kids.
There are 203 documents with the Topic related to science fiction. Therefore, if I wanted to have a category for Sport movies, I would have to build it myself because sports terms appear in fewer documents.
Create a Visual Text Analytics Project
In VTA, a pipeline is a process flow diagram whose nodes represent tasks in the Text Analysis Process, I described in detail how to work with the nodes in my MLKDayofService blog mentioned above. Briefly, from the SAS Home menu select the action Build Models that will take you to SAS Model Studio, where you select and create a New Project.
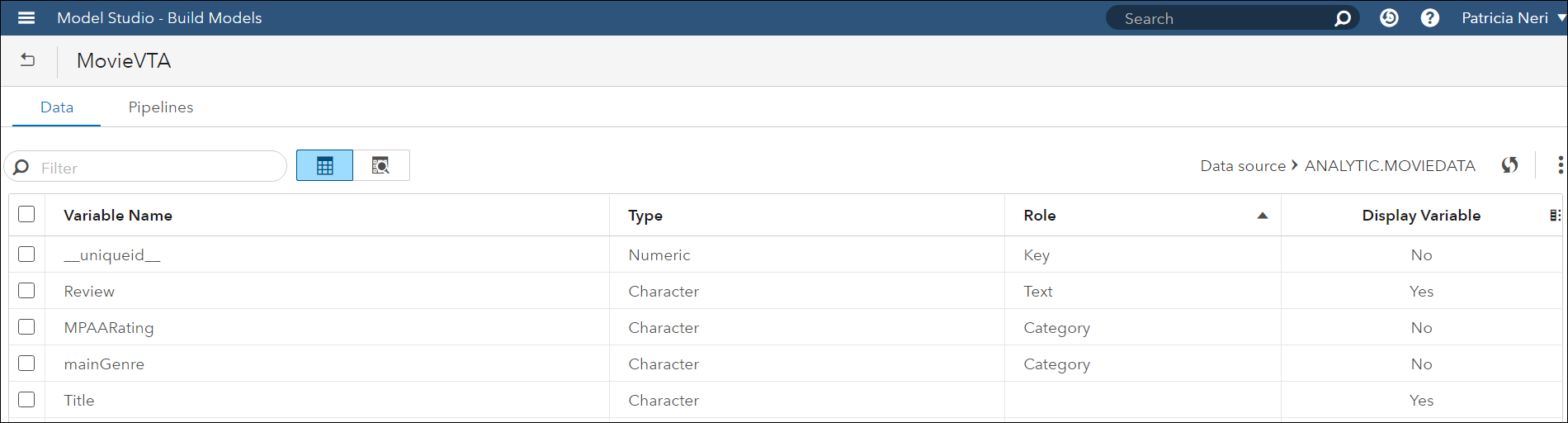
The photo above shows the data role assignments done in the Data tab.
Notice that there is a Unique Row Identifier for each document, the Text Variable to analyze is Review, and two variables are used as Category: MPAARating and mainGenre. Later on, VTA will use these two variables to automatically create categories and their Boolean rules. Title doesn’t have a role but I want it to be displayed to facilitate the analysis.
Movies are already classified according to their main category (mainGenre), I want to see the Boolean rules that VTA automatically generates for each category, and if I can create new concepts and categories that improve on the initial categorization. For example, I would like:
- to find children movies that don’t contain violence,
- to find movies that are related to Sports,
- to read the reviews of my favorite old movies, and
- find movies whose reviews mention some of my favorite movie directors.
Method
I ran two pipelines. The first one had the default pipeline settings and also the option Include predefined concepts enabled for the Concepts node. The objective was to see the rules associated with the genres “Sports”, “Animated” and “Family”, the movies matched by these rules, as well as, the ones that shouldn’t have been matched. In the second pipeline, I developed LITI and Boolean rules with the objective of improving the default categorizations automatically produced in the first pipeline.
In the next sections I will describe how the new categories were built. In real business situations, sometimes we will have pre-defined categories available to us, and other times we will come up with categories that satisfy the business objectives after analyzing many documents.
Customized Concepts built in the Concept Node
In the second pipeline, I developed three customized concepts, I will use one of them “MySports” to build a new category later on.
Basic Boolean operators are used to define new concepts and categories. AND/NOT operators are applied to the whole document. There other operators that search within the same sentence (SENT), the same paragraph (PARA) or a number of terms (DIST).
# Any line that starts with “#” is a comment
# Use CLASSIFIER to match a literal sequence
# Use CONCEPT_RULE to use Boolean and proximity operators. The term extracted should use _c{ }
MySports Concept
I wrote this rule which matches 98 documents, most of them related to Sport movies and with few false positives. This rule will match a document if any of the terms sport, baseball, tennis, football, basketball, racetrack appear anywhere in the document (movie review) but the terms gambling, buddy or sporting do not appear anywhere in the document.
I will use this MySports CONCEPT_RULE to build the new Sports category:
CONCEPT_RULE: (AND, (OR, “_c{sport@}”,”_c{baseball}”,”_c{tennis}”,”_c{football}”,”_c{basketball}”, “_c{racetrack}”),(NOT,”sporting”),(NOT, “gambling”),(NOT,”buddy”))
filmmakersInReview Concept
I built this concept just to illustrate how to use a pre-defined concept, in this case nlpPerson:
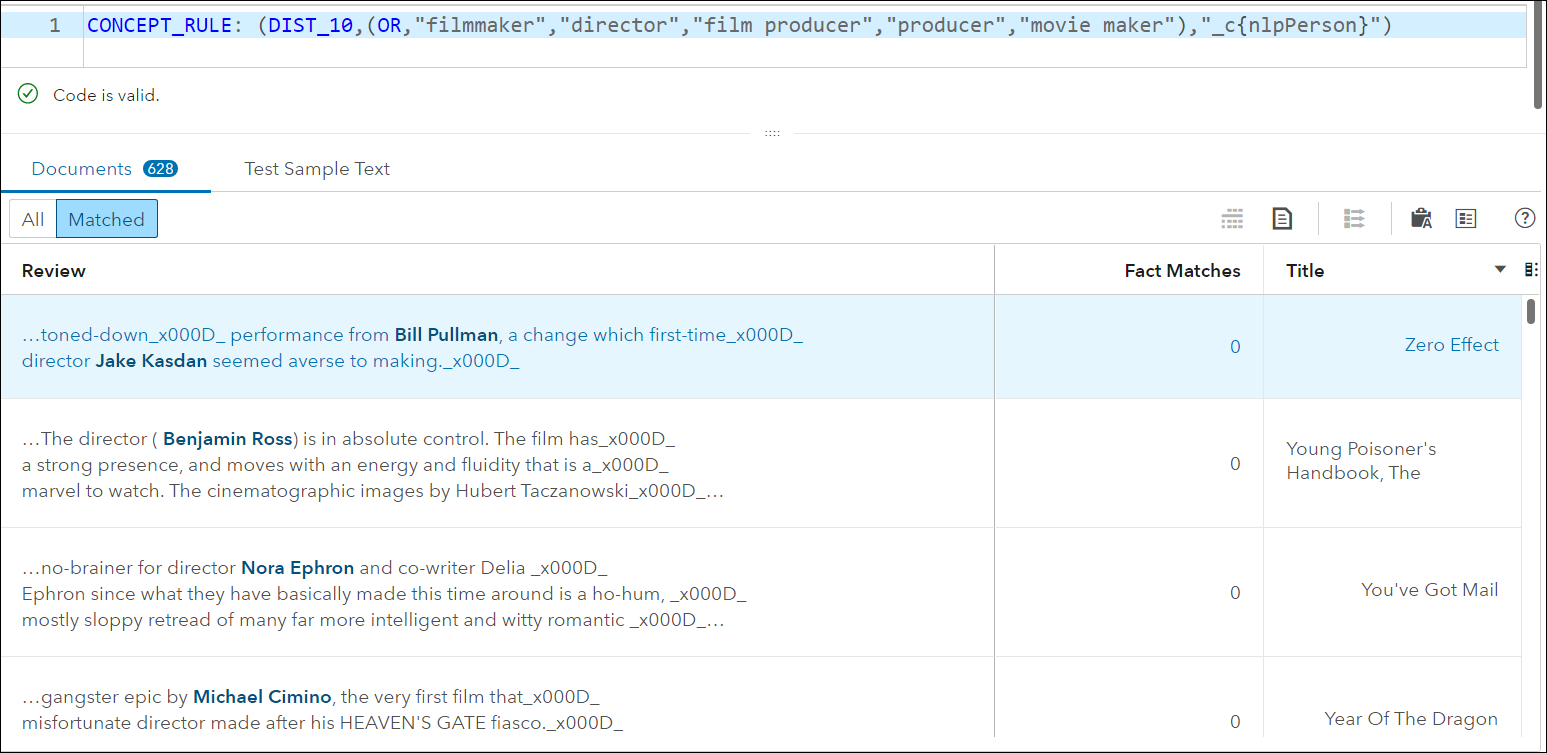
CONCEPT_RULE: (DIST_10,(OR,”filmmaker”,”director”,”film producer”,”producer”,”movie maker”),”_c{nlpPerson}”)
favoriteMovies Concept
I built this concept to match my favorite old movies and one of my favorite directors. The first CONCEPT_RULE will match documents that contain in the same sentence the terms Stanley Kubrick and 2001. The second CONCEPT_RULE will match documents that contain the two terms anywhere in the document. Both CONCEPT_RULEs will only extract the first term "Stanley Kubrick":
CLASSIFIER:A Space Odyssey
CLASSIFIER:The Sound of Music
CLASSIFIER:Il Postino
CONCEPT_RULE:(SENT,”_c{Stanley Kubrick}”,”2001″)
CONCEPT_RULE:(AND,”_c{Stanley Kubrick}”,”A Space Odyssey”)
New Concepts in Parsing Text Node
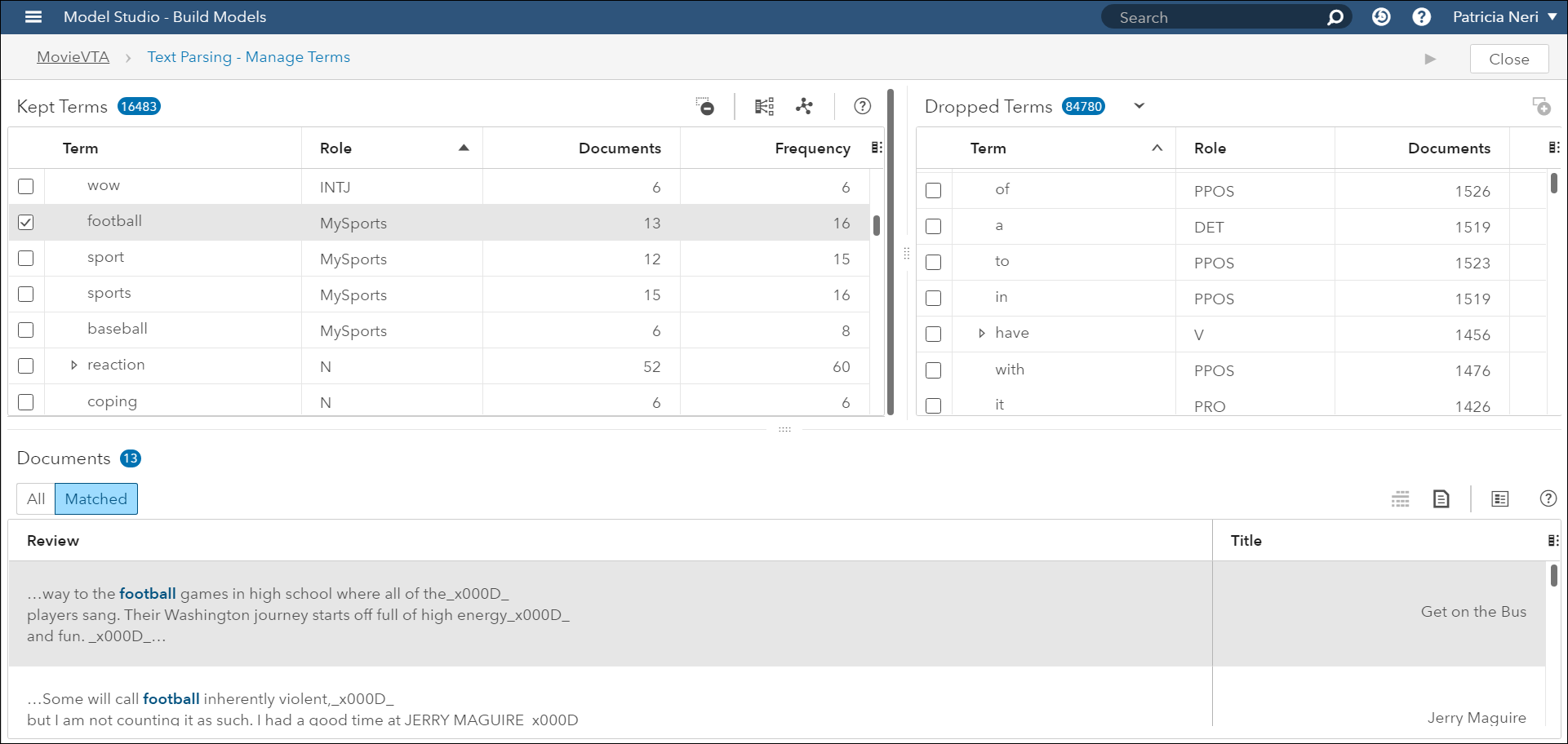
The customized concepts developed in the Concepts node are passed to the Text Parsing Node. Notice the Terms football, sport, sports, baseball and the new Role MySports in the Kept Terms window, as well as the matched documents to the term "football":
Customized Categories in the Category Mode
In the second pipeline I developed new categories using as starting point the rules associated with the genres “Sports”, “Animated” and “Family”.
Sports Category
The input data has only 3 movies in the Sports category, it is difficult to generate a meaningful rule with such a small dataset. Once the first pipeline is ran, there are a total of 8 movies which include the 3 original ones, and 5 that are not related to sports. The automatically generated rule is:
(OR,(AND,”crowd-pleaser”),(AND,”conor”),(AND,”_x000d_stupid”))
For the second pipeline, I developed the MySports rule in the Concepts node as mentioned above, and write this Boolean rule in the Categories node:
(OR,(AND,”crowd-pleaser”),(AND,”conor”),(AND,”_x000d_stupid”),”[MySports]”)
The new rule matches 90 movies, most of them related to Sports. For the next iteration, one would need to look at the movies that don’t relate to Sports, the ones that relate to Sports and were not matched, and improve in the rule above.
ChildrenMovies Category
In the second pipeline, I combined the rules for the Family and Animation categories which were automatically produced in the first pipeline.
For the Family category, there were 6 movies matched by this rule
(OR,(AND,(OR,”adults”,”adult”),”oz”))
It matched “People vs Larry Flynt” which prompted me to use the terms “murder” and “obscenity” in the Concept rule.
The Animation category had 66 matched movies and the automatically generated rule was:
(OR,(AND,”pixar”),(AND,(OR,”animator”,”animators”)),(AND,(OR,”voiced”,”voices”,”voicing”,”voice”),(OR,”cartoon”,”cartoons”)),(AND,(OR,”cartoon characters”,”cartoon character”)),(AND,(OR,”lesson”,”lessons”),”animated”),(AND,”live action”),(AND,”jeffrey”,(OR,”features”,”feature”)),(AND,”3-d”))
I decided to modify these two rules. In the second pipeline, I used this new rule
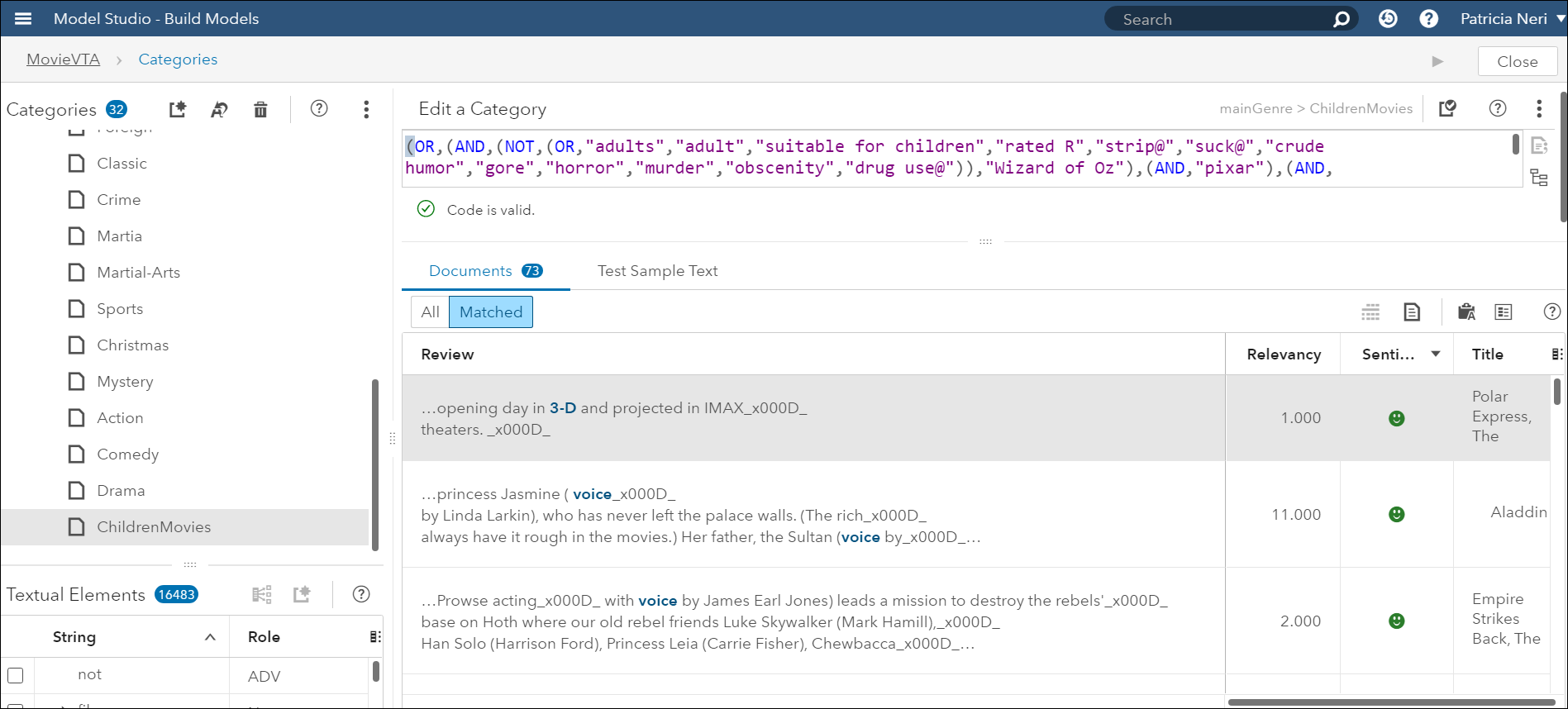
(OR,(AND,(NOT,(OR,”adults”,”adult”,”suitable for children”,”rated R”,”strip@”,”suck@”,”crude humor”,”gore”,”horror”,”murder”,”obscenity”,”drug use@”)),”Wizard of Oz”),(AND,”pixar”),(AND,(OR,”animator”,”animators”)),(AND,(OR,”voiced”,”voices”,”voicing”,”voice”),(OR,”cartoon”,”cartoons”)),(AND,(OR,”cartoon characters”,”cartoon character”)),(AND,(OR,”lesson”,”lessons”),”animated”),(AND,”live action”),(AND,”jeffrey”,(OR,”features”,”feature”)),(AND,”3-d”))
This produced 73 movies and only two rated “R”. Therefore, I removed both the Animation and the Family categories and created the new category childrenMovies.
Again, to determine if the new rules are an improvement over the previous ones, we must find out how many true positives and false positives are matched by the new rules, and repeat the process until we obtain the precision required.
Conclusion
Because the automatically generated concepts and categories in Visual Text Analytics (VTA) can be refined using LITI and Boolean rules, highly customized models can be developed in VTA.
As in all analytical projects, the discovery process in Text Analytics projects requires several iterations where the insights found in one iteration are used in the next iterations. In relationship to the linguistic rules, one must determine if the new rules are an improvement over the ones used in previous iterations, and find how many true positives and false positives are matched by the new rules. This process should be repeated until one obtains the precision required.
Many thanks to Teresa Jade and Biljana Belamaric Wilsey for reviewing the linguistic rules used in this blog. For more information about Visual Text Analytics, please check out:

3 Comments
This is very helpful. Can we compute sentiment at feature level. By this mean instead of sentiment at document level, sentiment at term level
VTA calculates sentiment at the document level using a SAS proprietary sentiment model where sentiment/opinions of terms and expressions are considered.
This is very helpful and informative! Thank you Patricia!