If you've ever wanted to apply modern machine learning techniques for text analysis, but didn't have enough labeled training data, you're not alone. This is a common scenario in domains that use specialized terminology, or for use cases where customized entities of interest won't be well detected by standard, off-the-shelf entity models.
For example, manufacturers often analyze engineer, technician, or consumer comments to identify the name of specific components which have failed, along with the associated cause of failure or symptoms exhibited. These specialized terms and contextual phrases are highly unlikely to be tagged in a useful way by a pre-trained, all-purpose entity model. The same is true for any types of texts which contain diverse mentions of chemical compounds, medical conditions, regulatory statutes, lab results, suspicious groups, legal jargon…the list goes on.
For many real-world applications, users find themselves at an impasse, it being incredibly impractical for experts to manually label hundreds of thousands of documents. This post will discuss an analytical approach for Named Entity Recognition (NER) which uses rules-based text models to efficiently generate large amounts of training data suitable for supervised learning methods.
Putting NER to work
In this example, we used documents produced by the United States Department of State (DOS) on the subject of assessing and preventing human trafficking. Each year, the DOS releases publicly-facing Trafficking in Persons (TIP) reports for more than 200 countries, each containing a wealth of information expressed through freeform text. The simple question we pursued for this project was: who are the vulnerable groups most likely to be victimized by trafficking?
Sample answers include "Argentine women and girls," "Ghanaian children," "Dominican citizens," "Afghan and Pakistani men," "Chinese migrant workers," and so forth. Although these entities follow a predictable pattern (nationality + group), note that the context must also be that of a victimized population. For example, “French citizens” in a sentence such as "French citizens are working to combat the threats of human trafficking" are not a valid match to our "Targeted Groups" entity.
For more contextually-complex entities, or fluid entities such as People or Organizations where every possible instance is unknown, the value that machine learning provides is that the algorithm can learn the pattern of a valid match without the programmer having to anticipate and explicitly state every possible variation. In short, we expect the machine to increase our recall, while maintaining a reasonable level of precision.
For this case study, here is the method we used:
1. Using SAS Visual Text Analytics, create a rules-based, contextual extraction model on a sample of data to detect and extract the "Targeted Groups" custom entity. Next, apply this rules-based model to a much larger number of observations, which will form our training corpus for a machine learning algorithm. In this case, we used Conditional Random Fields (CRF), a sequence modeling algorithm also included with SAS Visual Text Analytics.
2. Re-format the training data to reflect the json input structure needed for CRF, where each token in the sentence is assigned a corresponding target label and part of speech.
3. Train the CRF model to detect our custom entity and predict the correct boundaries for each match.
4. Manually annotate a set of documents to use as a holdout sample for validation purposes. For each document, our manual label captures the matched text of the Targeted Groups entity as well as the start and end offsets where that string occurs within the larger body of text.
5. Score the validation “gold” dataset, assess recall and precision metrics, and inspect differences between the results of the linguistic vs machine learning model.
Let's explore each of these steps in more detail.
1. Create a rules-based, contextual extraction model
In SAS Visual Text Analytics, we created a simple model consisting of a few intermediate, "helper" concepts and the main Targeted Groups concept, which combines these entities to generate our final output.
The Nationalities List and Affected Parties concepts are simple CLASSIFIER lists of nationalities and vulnerable groups that are known a priori. The Targeted Group is a predicate rule which only returns a match if the aforementioned two entities are found in that order, separated by no more than 7 tokens, AND if there is not a verb intervening between the two entities (the verb "trafficking" being the only exception). This verb exclusion clause was added to the rule to prevent false matches such as "Turkish Cypriots lacked shelters for victims" and "Bahraini government officials stated that they encouraged victims to participate in the investigation and prosecution of traffickers." We then applied this linguistic model to all the TIP reports leading up to 2017, which would form the basis for our CRF training data.
Nationalities List Helper Concept:
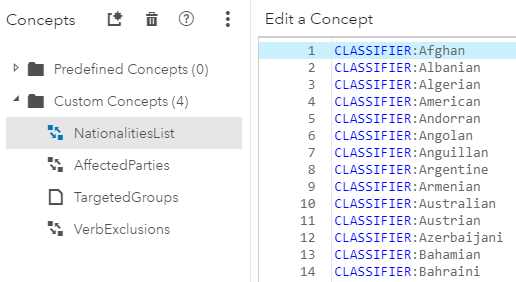
Affected Parties Helper Concept:
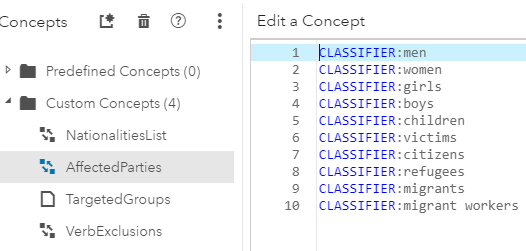
Verb Exclusions Helper Concept:

Targeted Group Concept (Final Fact Rule):

2. Re-format the training data
The SAS Visual Text Analytics score code produces a transactional-style output for predicate rules, where each fact argument and the full match are captured in a separate row. Note that a single document may have more than one match, which are then listed according to _result_id_.
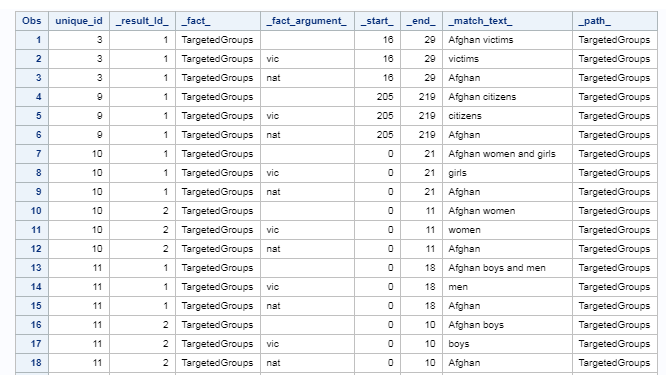
Using code, we joined these results back to the original table and the underlying parsing tables to transform the native output you see above to this, the json format required to train a CRF model:

Notice how every single token in each sentence is broken out separately and has both a corresponding label and part of speech. For all the tokens which are not part of our Targeted Groups entity of interest, the label is simple "O", for "Other". But, for matches such as "Afghan women and girls," the first token in the match has a label of "B-vic" for "Beginning of the Victim entity" and subsequent tokens in that match are labeled "I-vic" for "Inside the Victim entity."
Note that part of speech tags are not required for CRF, but we have found that including them as an input improves the accuracy of this model type. These three fields are all we will use to train our CRF model.
3. Train the CRF model
Because the Conditional Random Fields algorithm predicts a label for every single token, it is often used for base-level Natural Language Processing tasks such as Part of Speech detection. However, we already have part of speech tags, so the task we are giving it in this case is signal detection. Most of the words are "Other," meaning not of interest, and therefore noise. Can the CRF model detect our Targeted Groups entity and assign the correct boundaries for the match using the B-vic and I-vic labels?
After loading the training data to CAS using SAS Studio, we applied the crfTrain action set as follows:

After it runs successfully, we have a number of underlying tables which will be used in the scoring step.
4. Manually annotate a set of documents
For ease of annotation and interpretability, we tokenized the saved the original data by sentence. Using a purpose-built web application which enables a user to highlight entities and save the relevant text string and its offsets to a file, we then hand-scored approximately 2,200 sentences from 2017 TIP documents. Remember, these documents have not yet been "seen" by either the linguistic model or the CRF model. This hand-scored data will serve as our validation dataset.
5. Score the validation “gold” dataset by both models and assess results
Finally, we scored the validation set in SAS Studio with the CRF model, so we could compare human versus machine outcomes.

In a perfect world, we would hope that all the matches found by humans are also found by the model and moreover, the model detected even more valid matches than the humans. For example, perhaps we did not include "Rohingyan" or "Tajik" (versus Tajikistani) as nationalities in our CLASSIFIER list in our rules-based model, but the machine learning model detected victims from these groups them as a valid pattern nonetheless. This would be a big success, and one of the compelling reasons to use machine learning for NER use cases.
In a future blog, I'll detail the results of the outcomes, including modeling considerations such as:
o The format of the CRF training template
o The relative impact of including inputs such as part of speech tags
o Precision and recall metrics
o Performance and train times by volumes of training documents
Machine markup provides scale and agility
In summary, although human experts might produce the highest-quality annotations for NER, machine markup can be produced much more cheaply and efficiently -- and even more importantly, scale to far greater data volumes in a fraction of the time. Generating a rules-based model to generate large amounts of "good enough" labeled data is an excellent way to take advantage of these economies of scale, reduce the cost-barrier to exploring new use cases, and improve your ability to quickly adapt to evolving business objectives.
