With the release of SAS Viya 3.3, you now have the ability to pass implicit SQL queries to a variety of SQL data sources, including Hive. Under an implicit pass-through, users can write SAS compliant SQL code, and SAS will:
- Convert as much code as possible into database native SQL.
- Execute the resulting query in-database.
- Bring the result back into SAS Viya.
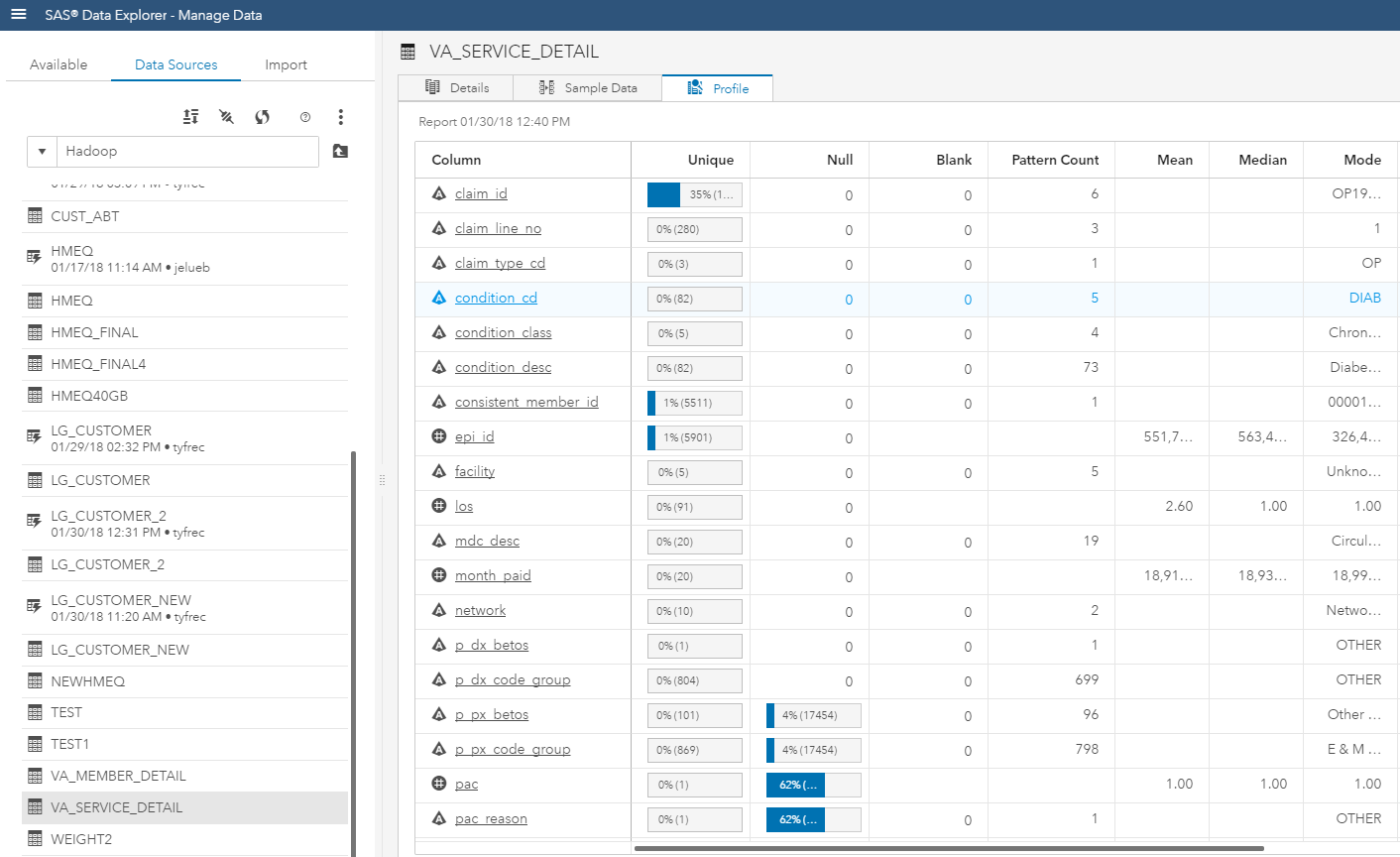
My SAS Viya is co-located within a Hortonworks Hadoop environment. Within this environment, I have set up multiple tables within Hive, which provides structure and a query-like environment for Hadoop data. Using the SAS Data Explorer in SAS Viya, I can easily see the different tables in the Hive environment, and visually inspect them without having to load the data into SAS. The screenshot below shows the Hive table va_service_detail, which contains anonymous data related to recent hospital stays.
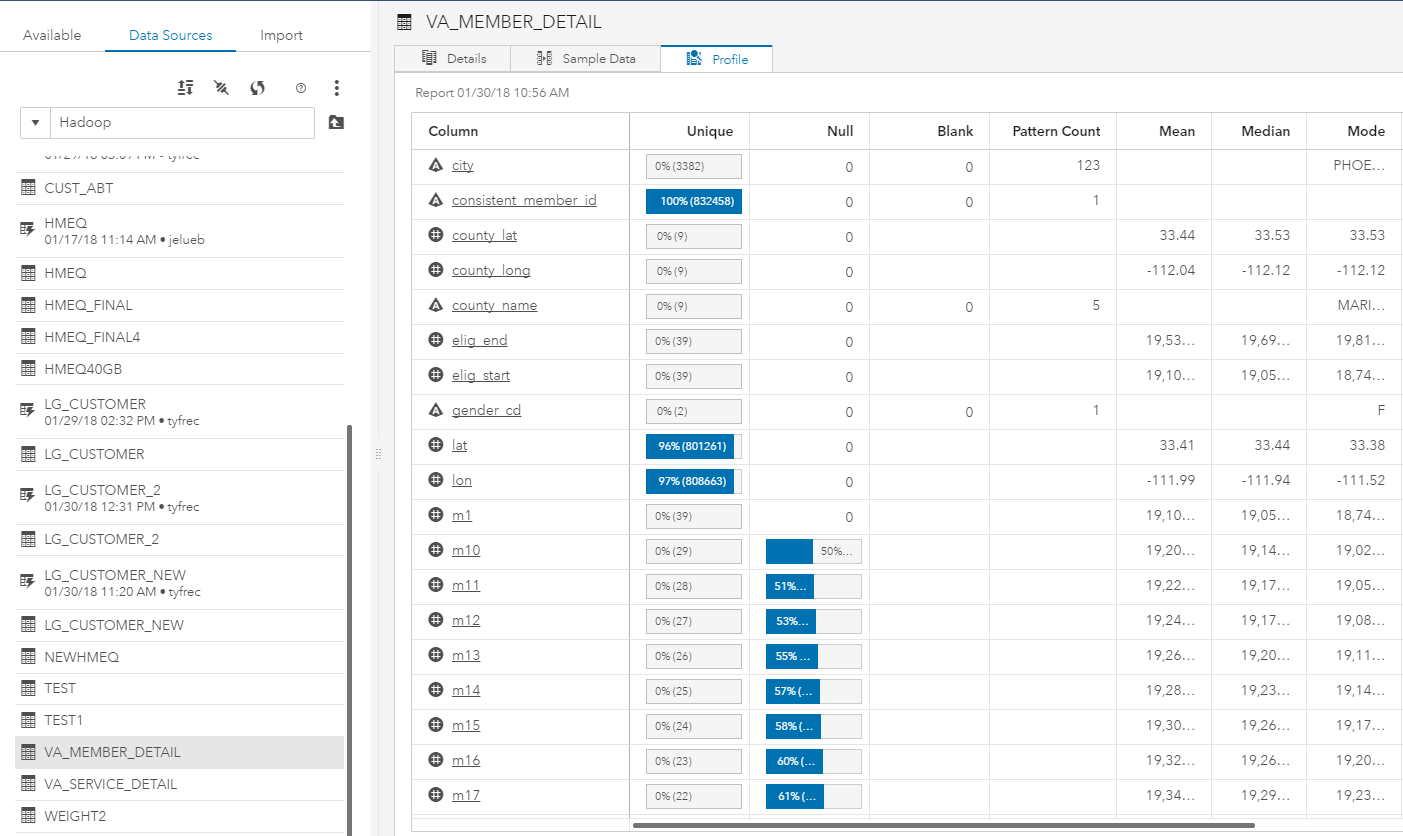
In my Hive environment, I have a second table called va_member_detail, which contains information about the individuals who were hospitalized in the above table, va_service_detail. A summary of this Hive table can be found in the screenshot below.
Using this data, I would like to perform an analysis to determine why patients are readmitted to the hospital, and understand how we can preventatively keep patients healthy. I will need to join these two tables to allow me to have visit-level and patient-level information in one table. Since medical data is large and messy, I would like to only import the needed information into SAS for my analysis. The simplest way to do this is through an implicit SQL pass-through to Hive, as shown below:
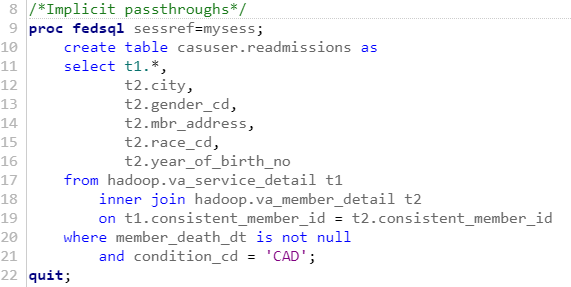
With an implicit pass-through, I write normal SAS FedSQL code on top of a SAS Library called “Hadoop” pointing to my Hive Server. Once the code is submitted, the SAS System performs the following steps:
- Translates the SAS FedSQL code into HiveQL.
- Executes the HiveQL script in Hive.
- Loads the resulting data in parallel into SAS.
Looking at the log, we can see that the SQL statement was “Fully offloaded to the underlying data source via fill pass-through”, meaning that SAS successfully executed the query, in its entirety, in Hive. With the SAS Embedded Process for Hadoop, the resulting table is then lifted in-parallel from Hive into SAS Viya, making it available for analysis.
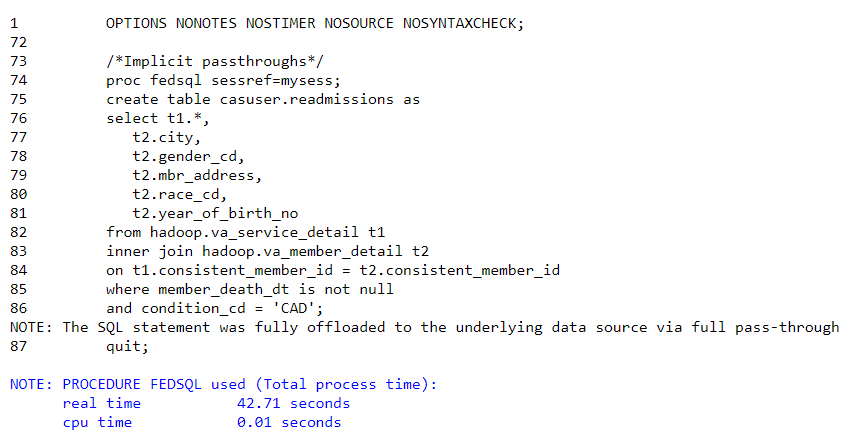
As we can see in the log, it took 42 seconds to execute the query in Hive, and bring the result into SAS. To compare efficiency, I redid the analysis, loading va_service_detail and va_member_detail into the memory of the SAS server and performed the join there. The execution took 58 seconds, but required three in-memory tables to do so, along with much more data passing through the network. The implicit pass-through has the benefits of increased speed and decreased latency in data transfer by pushing the query to its source, in this case Hive.
Conclusion
The Implicit SQL Pass-through to Hive in SAS Viya is a must have tool for any analyst working with Hadoop data. With normal SQL syntax in a familiar SAS interface, analysts can push down powerful queries into Hive, speeding up their analysis while limiting data transfer. Analysts can effectively work with large ever-growing data sizes, and speed up the time to value on solving key business challenges.
