SAS Viya provides a robust, scalable, cloud-ready, distributed runtime engine. This engine is driven by CAS (Cloud Analytic Services), providing fast processing for many data management techniques that run distributive, i.e. using all threads on all defined compute nodes.
Note:
SAS Viya 3.5+ now supports the data set option APPEND=YES. The code displayed in figure 4 can be re-written as:
data casuser.append_target_table (append=yes);
set casuser.table_two;
run;
Why
PROC APPEND is a common technique used in SAS processes. This technique will concatenate two data sets together. However, PROC APPEND will produce an ERROR if the target CAS table exists prior to the PROC APPEND.
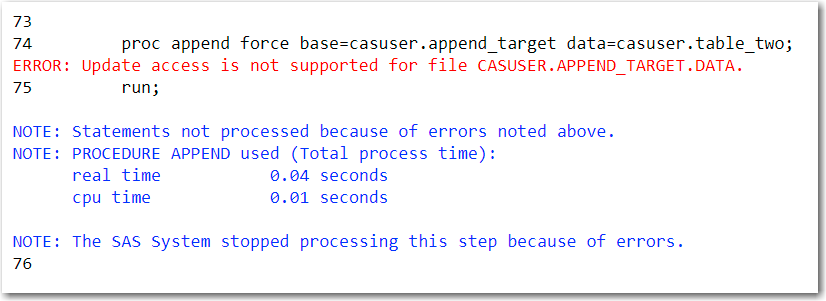
Now what?
How
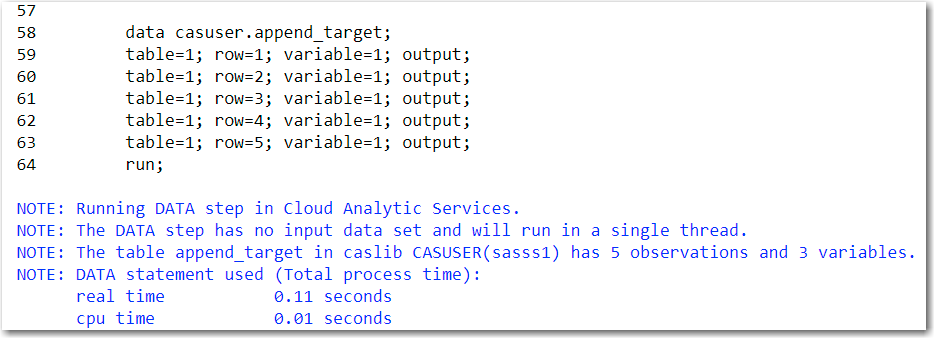
To explain how to emulate PROC APPEND we first need to create two CAS tables. The first CAS table is named CASUSER.APPEND_TARGET. Notice the variables table, row and variable in figure 2.
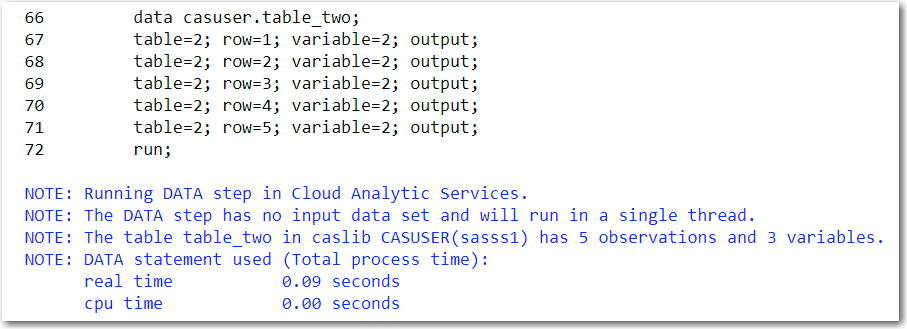
The second CAS table is called CASUSER.TABLE_TWO and in figure 3 we can review the variables table, row, and variable.
To emulate PROC APPEND we will use a DATA Step. Notice on line 77 in figure 4 we will overwrite an existing CAS table, i.e. CASUSER.APEND_TARGET. On Line 78, we see the first table on the SET statement is CASUSER.APPEND_TARGET, followed by CASUSER.TABLE_TWO. When this DATA Step runs, all of the rows in CASUSER.APPEND_TARGET will be processed first, followed by the rows in CASUSER.TABLE_TWO. Also, note we are not limited to two tables on the SET statement with DATA Step; we can use as many as we need to solve our business problems.
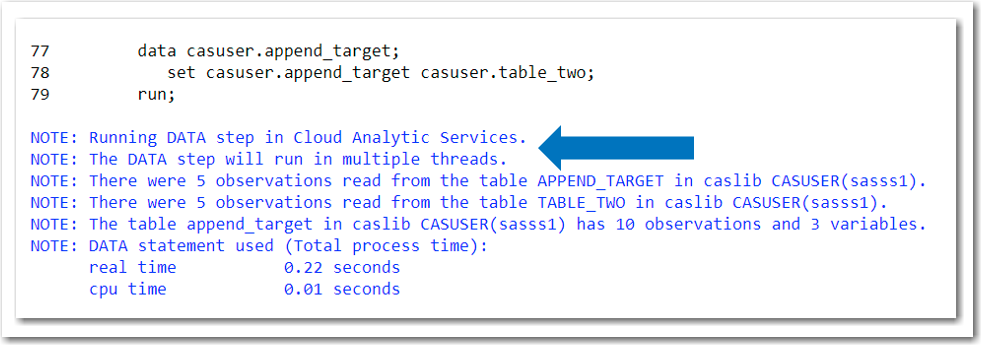
The result table created by the DATA Step is shown in figure 5.

Conclusion
SAS Viya’s CAS processing allows us to stage data for downstream consumption by leveraging robust SAS programming techniques that run distributed, i.e. fast. PROC APPEND is a common procedure used in SAS processes. To emulate PROC APPEND when using CAS tables as source and target tables to the procedure, use DATA Step.

15 Comments
The target does not exist. Table 2 is in hive. I want to create the target in hive by appending Table 2. Then I will continue to append other hive tables to the target.
Hi ljc,
Researching this I found this link which explains your options using HIVEQL to append 2 Hive tables using the INSERT INTO statement https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML#LanguageManualDML-Syntax.1
To test if PROC SQL INSERT INTO will push down submit these OPTION statements prior to your PROC SQL code:
/*-------------------------------------------------------------------------------
**1.0 SAS system option to push PROC SQL, FREQ, MEANS, RANK, REPORT, SUMMARY and
** TABULATE down in their SQL
*/
options SQLGENERATION=(NONE DBMS='TERADATA DB2 ORACLE NETEZZA ASTER GREENPLM HADOOP SAPHANA IMPALA HAWQ POSTGRES REDSHIFT SQLSVR VERTICA');
/*------------------------------------------------------
**2.0 SAS system option to prove where SQL was processed
*/
OPTIONS sastrace=',,,ds' sastraceloc=saslog nostsuffix;
OPTIONS MSGLEVEL=I;
Best regards,
Steve
Hi ljc,
I was able to validate using PROC SQL and or PROC FEDSQL one can append Hive tables:
/* Full pushdown */
proc FedSQL iptrace libs=hivelib;
insert into hivelib.trash2
select * from hivelib.trash;
quit;
/* Full pushdown */
proc sql;
insert into hivelib.trash2
select * from hivelib.trash;
quit;
148 /* Full pushdown */
149 proc FedSQL iptrace libs=hivelib;
NOTE: FEDSQL: Using libname HIVELIB (engine HADOOP).
NOTE: FEDSQL: Ignoring libname SASHELP (engine V9); not in LIBS= option.
NOTE: FEDSQL: Ignoring libname MAPS (engine V9); not in LIBS= option.
NOTE: FEDSQL: Ignoring libname MAPSSAS (engine V9); not in LIBS= option.
NOTE: FEDSQL: Ignoring libname MAPSGFK (engine V9); not in LIBS= option.
NOTE: FEDSQL: Ignoring libname SASUSER (engine V9); not in LIBS= option.
NOTE: FEDSQL: Using libname WORK (engine V9).
NOTE: Connection string:
NOTE: DRIVER=FEDSQL;CONOPTS= (
(DRIVER=HIVE;SERVER=controller.gtpdm.sashq-d.openstack.sas.com;BULK_LOAD=YES;DBMAX_TEXT=256;PORT=10000;SCHEMA=default;CATALOG=
HIVELIB); (DRIVER=BASE;CATALOG=WORK;SCHEMA=
(NAME=WORK;PRIMARYPATH={/opt/sas/viya/config/var/tmp/compsrv/default/c282f4fd-510a-4f8d-8c35-4e12ac4de221/SAS_work39C700000778
_gtpviya.gtpdm.sashq-d.openstack.sas.com})))
150 insert into hivelib.trash2
151 select * from hivelib.trash;
IPTRACE: Query:
insert into hivelib.trash2 select * from hivelib.trash
IPTRACE: FULL (DDL) pushdown to HIVE SUCCESS!
IPTRACE: Retextualized child query:
insert into table `default`.`TRASH2`select `TRASH`.`make`, `TRASH`.`model`, `TRASH`.`type`, `TRASH`.`origin`, `TRASH`.`drivetrain`,
`TRASH`.`msrp`, `TRASH`.`invoice`, `TRASH`.`enginesize`, `TRASH`.`cylinders`, `TRASH`.`horsepower`, `TRASH`.`mpg_city`,
`TRASH`.`mpg_highway`, `TRASH`.`weight`, `TRASH`.`wheelbase`, `TRASH`.`length` from `default`.`TRASH`
IPTRACE: END
NOTE: Execution succeeded. No rows affected.
152 quit;
NOTE: PROCEDURE FEDSQL used (Total process time):
real time 25.54 seconds
cpu time 0.14 seconds
153
154 /* Full pushdown */
155 proc sql;
156 insert into hivelib.trash2
157 select * from hivelib.trash;
60 1591806039 no_name 0 SQL
HADOOP_16: Prepared: on connection 0 61 1591806039 no_name 0 SQL
DESCRIBE FORMATTED `default`.`TRASH2` 62 1591806039 no_name 0 SQL
63 1591806039 no_name 0 SQL
64 1591806039 no_name 0 SQL
HADOOP_17: Prepared: on connection 0 65 1591806039 no_name 0 SQL
DESCRIBE FORMATTED `default`.`TRASH` 66 1591806039 no_name 0 SQL
67 1591806039 no_name 0 SQL
68 1591806039 no_name 0 SQL
HADOOP_18: Executed: on connection 1 69 1591806039 no_name 0 SQL
insert into table `default`.`TRASH2` (`make`, `model`, `type`, `origin`, `drivetrain`, `msrp`, `invoice`, `enginesize`,
`cylinders`, `horsepower`, `mpg_city`, `mpg_highway`, `weight`, `wheelbase`, `length`) select TXT_2.`make`, TXT_2.`model`,
TXT_2.`type`, TXT_2.`origin`, TXT_2.`drivetrain`, TXT_2.`msrp`, TXT_2.`invoice`, TXT_2.`enginesize`, TXT_2.`cylinders`,
TXT_2.`horsepower`, TXT_2.`mpg_city`, TXT_2.`mpg_highway`, TXT_2.`weight`, TXT_2.`wheelbase`, TXT_2.`length` from `default`.`TRASH`
TXT_2 70 1591806039 no_name 0 SQL
71 1591806039 no_name 0 SQL
158 quit;
NOTE: PROCEDURE SQL used (Total process time):
real time 25.02 seconds
cpu time 0.27 seconds
Best regards,
Steve
How would you append in Hive/Hadoop (first dataset does not exist)?
Hi ljc,
I need clarification on your question, what do you mean by first dataset does not exist? Also, the source data you want to use to append, is that an existing Hive table or a CAS table?
Best regards,
Steve
Can we append to a in memory partitioned table?
Hi Ramprakash,
Great question but no one cannot. If you try you will get an error in the SAS Log:
ERROR: Appending to a table that is both ordered and partitioned is not supported.
Best regards,
Steve
In 9.4 Proc Append, the procedure would create the base dataset if it did not exist whereas the data step complains if you try to set a dataset that does not exist. Anyway around this?
Thank you for your question but there is no way around this when using DATA Step to append data.
Thank you for your comment Fernando. You are correct, with Viya 3.4 support was added for the DATA Step option APPEND=YES.
Proc & Roll,
Steven
Hi
Do you tryed:
data casuser.append_target (append=yes);
set casuser.table_two;
run;
This data step is executed in CAS
Regards
Hi Steven, when our source data is Oracle there is a mismatch column type issue when we append to CAS.
The process goes like this - we do initial bulk load from Oracle to CAS (so varchar type is read and imported). The incremental load is based on the max date from the initial load, and use it as a filter for the source data Oracle. The delta rows are then loaded as a SAS work dataset. Then when we append to the initial bulk CAS data, there will be a mismatch of type since in the SAS work the varchar was converted to character.
An alternative is for us to load the delta rows directly into a CAS data. But, how do we append CAS data directly to the initial CAS data? When we test this, the output is a session-only data, then we need to promote. Using the promote option shows error - "ERROR: The target table intialCAS of the promotion already exists. Please specify a different name.
ERROR: The action stopped due to errors."
Thank you for your question Mark. I need to research to ensure I provide a working solution. To facilitate the research please email me directly at steven.sober@sas.com so I can ask you additional questions as I research.
Proc & Roll,
Steven
Hi Bart,
Great comment; I should of mentioned in my blog that I like using DATA Step for APPENDs when I must apply transformations to the data being processed by the DATA Step i.e.
/*PROC APPEND BASE=&SOURCE OUT=⌖*//*RUN;*/ DATA ⌖
SET &TARGET(IN=S1) &SOURCE2(IN=S2) &SOURCE3(IN=S3);
IF S1 THEN…;
IF S3 THEN…;
RUN;
In the case where there are no transformations to be made to the data and you only want to append a few rows to an existing CAS table consider these two alternatives:
1. PROC CASUTIL http://go.documentation.sas.com/?cdcId=pgmsascdc&cdcVersion=9.4_3.2&docsetId=casref&docsetTarget=n1lmowayn4qghtn18lj7kupsdzi7.htm&locale=en
2. PROC CAS addTable Action http://go.documentation.sas.com/?cdcId=pgmsascdc&cdcVersion=9.4_3.2&docsetId=caspg&docsetTarget=cas-table-addtable.htm&locale=en
Proc & Roll,
Steven
Hi Steven,
If APPEND_TARGET were existing and big and i would have only a few rows in TABLE_TWO that I need to append to APPEND_TARGET, this does not look very efficient since APPEND_TARGET is first copied onto itself before the few rows in TABLE_TWO are appended.
Or does this work more efficient behind the covers?
Regards,
Bart