The purpose of this blog post is to demonstrate a SAS coding technique that allows for calculations with multiple variables and multiple observations across a SAS dataset. This technique can be useful for working with time series, clinical trials, - in any data step calculations involving values from different observations.
What do we want?
As illustrated in the picture on the right, we want to be able to hop, or jump, back and forth, up and down across observations of a data table in order to implement calculations not just on different variables, but with their values from different observations of a data table.
In essence, we want to access SAS dataset variable values similar to accessing elements of a matrix (aij), where rows represent dataset observations, and columns represent dataset variables.
Combine and Conquer
In the spirit of my earlier post Combine and Conquer with SAS, this technique combines the functionality of the LAG function, which allows us to retrieve the variable value of a previous observation from a queue, with an imaginary, non-existent in SAS, LEAD function that reads a subsequent observation in a data set while processing the current observation during the same iteration of the DATA step.
LAG function
LAG<n> function in SAS is not your usual, ordinary function. While it provides a mechanism of retrieving previous observations in a data table, it does not work “on demand” to arbitrarily read a variable value from a previous observation n steps back. If you want to use it conditionally in some observations of a data step, you still need to call it in every iteration of that data step. That is because it retrieves values from a queue that is built sequentially for each invocation of the LAG<n> function. In essence, in order to use the LAG function even just once in a data step, you need to call it every time in each data step iteration until that single use.
Moreover, if you need to use each of the LAG1, LAG2, . . . LAGn functions just once, in order to build these queues, you have to call each of them in every data step iteration even if you are going to use them in some subsequent iterations.
LEAD function
The LEAD function is implemented in Oracle SQL and it returns data from the next or subsequent row of a data table. It allows you to query more than one row in a table at a time without having to join the table to itself.
There is no such function in SAS. However, the POINT= option of the SET statement in a SAS data step allows retrieving any observation by its number from a data set using random (direct) access to a SAS data set. This will allow us to simulate a LEAD function in SAS.
HOP function
But why do we need two separate functions like LAG and LEAD in order to retrieve non-current observations. In essence, these two functions do the same thing, just in opposite directions. Why can’t we get by with just one function that does both backwards and forwards “hopping?”
Let’s combine and conquer.
Ideally, we would like to construct a new single function - let’s call it HOP(x, j) - that combines the best qualities of both LAG and LEAD functions. The two arguments of the HOP function would be as follows:
x – SAS variable name (numeric or character) the value of which we are retrieving;
j – hop distance (numeric) – an offset from the current observation; negative values being lagging (hopping back), positive values being leading (hopping forward), and a zero-value meaning staying within the current observation. This argument can be either an integer constant or a numeric variable with an integer value.
The sign of the second argument defines whether we lag (minus) or lead (plus). The absolute value of this second argument defines how far from the current observation we hop.
Alternatively, we could have the first argument as a column number, and the second argument as a row/observation number, if we wanted this function to deal with the data table more like with a matrix. But relatively speaking, the method doesn’t really matter as long as we can unambiguously identify a data element or a cell. To stay within the data step paradigm, we will stick with the variable name and offset from the current observation (_n_) as arguments.
Let’s say we have a data table SAMPLE, where for each event FAIL_FLAG=1 we want to calculate DELTA as the difference between DATE_OUT, one observation after the event, and DATE_IN, two observations before the event:
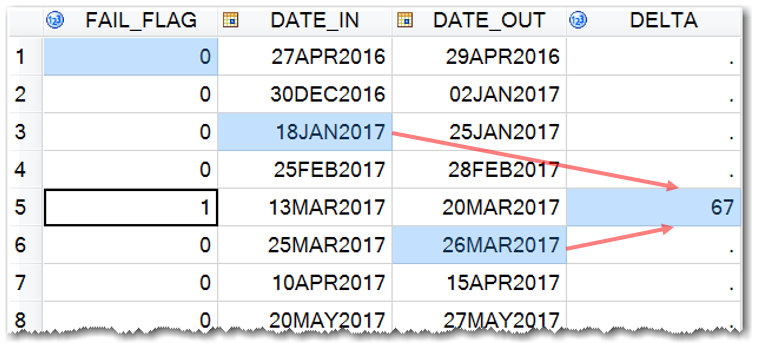
That is, we want to calculate DELTA in the observation where FAIL_FLAG = 1 as
26MAR2017 – 18JAN2017 = 67 (as shown in light-blue highlighting in the above figure).
With the HOP() function, that calculation in the data step would look like this:
data SAMPLE; set SAMPLE; if FAIL_FLAG then DELTA = hop(DATE_OUT,1) - hop(DATE_IN,-2); run; |
It would be reasonable to suggest that the hop() function should return a missing value when the second argument produces an observation number outside of the dataset boundary, that is when
_n_ + j < 0 or _n_ + j > num, where _n_ is the current observation number of the data step iteration; num is the number of observations in the dataset; j is the offset argument value.
Do you see anything wrong with this solution? I don’t. Except that the HOP function exists only in my imagination. Hopefully, it will be implemented soon if enough SAS users ask for it. But until then, we can use its surrogate in the form of a %HOP macro.
%HOP macro
The HOP macro grabs the value of a specified variable in an offset observation relative to the current observation and assigns it to another variable. It is used within a SAS data step, but it cannot be used in an expression; each invocation of the HOP macro can only grab one value of a variable across observations and assign it to another variable within the current observation.
If you need to build an expression to do calculations with several variables from various observations, you would need to first retrieve all those values by invoking the %hop macro as many times as the number of the values involved in the expression.
Here is the syntax of the %HOP macro, which has four required parameters:
%HOP(d,x,y,j)
d – input data table name;
x – source variable name;
y – target variable name;
j – integer offset relative to the current observation. As before, a negative value means a previous observation, a positive value means a subsequent observation, and zero means the current observation. The parameter j value can be either integer constant or a numeric variable name; in the latter case that variable's value at the current observation will be used as the offset.
Using this %HOP macro we can rewrite our code for calculating DELTA as follows:
data SAMPLE (drop=TEMP1 TEMP2); set SAMPLE; if FAIL_FLAG then do; %hop(SAMPLE,DATE_OUT,TEMP1, 1) %hop(SAMPLE,DATE_IN, TEMP2,-2) DELTA = TEMP1 - TEMP2; end; run; |
Note that we should not have temporary variables TEMP1 and TEMP2 listed in a RETAIN statement, as this could mess up our calculations if the j-offset throws an observation number out of the dataset boundary.
Also, the input data table name (d parameter value) is the one that is specified in the SET statement, which may or may not be the same as the name specified in the DATA statement.
In case you are wondering where you can download the %HOP macro from, here it is in its entirety:
%macro hop(d,x,y,j); _p_ = _n_ + &j; if (1 le _p_ le _o_) then set &d(keep=&x rename=(&x=&y)) point=_p_ nobs=_o_; %mend hop; |
Of course, it is “free of charge” and “as is” for your unlimited use.
Your turn
Please provide your feedback and share possible use cases for the HOP function/macro in the Comment section below. This is your chance for your voice to be heard!

62 Comments
Thank you so much! I use it often.
You are welcome, Anna! I am glad you find it useful.
Based on my experience on working with the data from clinical trials having such a build-in SAS function would be really helpful! Since every now and again I faced a need to get durations of certain events, such as time from pre-onset of adverse event to time when such event can be considered as resolved (not only based on actual onset/stop dates, but also considering other related timing info, such as date when corresponding lab parameter showed increase/decrease), etc.
I think that the main advantage of the approach described above is that all derivations can be done within one data step.
Below is a SAS code that I'm currently (when needed) using to handle the same (since up to date there is no such HOP function). It is based on the capabilities of PROC SQL:
data sample; do date_in=today() to today()+30; date_out=date_in+rand('integer',1,6); fail_flag=ifn(weekday(date_in)=5,1,0); row+1; output; end; format date_in date_out date9.; run; proc sql; create table get_delta as select *, case when a.fail_flag then (select date_out from sample where row=a.row+1) - (select date_in from sample where row=a.row-2) else . end as delta from sample as a; quit;Thank you, Kristina, for your constructive feedback. Your SQL solution looks great!
I like the idea of a single macro that can do both lags and leads, especially because it allows dynamic control of the lead and lag length. And if fail_flag=1 is a rare event I suspect "point=" is the right underlying strategy.
But the problem for me, when using a sorted data set, is that the underlying POINT= approach doesn't actually take advantage of the fact that the data are ordered. For large sorted data sets, I suspect that using lag functions, and emulating leads via "auto-merge with firstobs", is likely to be much faster, as it involves no direct-addressing of observations. Instead it uses SAS's very fast sequential read engine.
Consider the problem posted: get the number of days elapsed between the 2nd record prior to a failure and the 1st record after the failure. And that result should be assigned to the record having fail_flag=1:
data want; merge have have (firstobs=2 keep=date_out rename=(date_out=nxt_date)); delta = ifn(fail_flag=1,nxt_date - lag2(date,.); drop nxt_date; run;I suspect that for relatively large data sets, or relatively frequent precipitating events, that there would be a substantial time savings vs point=. For example I deal with datasets containing a day of stock trades (billions of observations time-stamped to the nano-second, sorted by trade symbol and time), looking for price changes and then retrieving some type of lagged or lead information surrounding the newly price record.
The other restriction that may limit use of %hop is when there needs to be a "where=" expression, which doesn't work in the "set ... point=" statement. For example, if instead of 2 records prior and 1 record later, you have a class variable, with values 1 and 2, and you only want to count records with the same class as the fail_flag=1 record. Unfortunately SAS won't let you use "set &d (where=(class=1)) point=&I". (One could program around that for lags, but subsetted leads are a good deal more challenging).
Mark, thank you for your comment. I totally agree with you that for different scenarios different solutions may be warranted. We are not talking "one size fits all" solution here; it is always a good idea to have an arsenal of diverse tools to choose from. I particularly target this hop() solution to clinical trials processing, where programmers deal with relatively small data tables and very tight programming deadlines. Plus, if suggested here hop() function (not my surrogate %hop() macro) is implemented in SAS, it might be fulfilled by different algorithms and means than point= option and be much more efficient for large data processing.
Nice! This will be very handy to calculate what we need sometimes. Thanks.
Hi Rodger, thank you for your feedback. I am glad to hear this is useful for your work.
From a programming point of view, what you are looking for is the ability to index the observations of a variable. Using the data step, this would mostly need to be done by creating an array. However, the TIMEDATA procedure will automatically allow that kind of access to a variable as a series. Consider this code which shows computing a 5 term moving average using an array and using PROC TIMEDATA. (see below)
Actually from within the TIMEDATA procedure, you can even skip using FCMP, and access the observations directly. Here is an example from the documentation:
proc timedata data=transactions out=timeseries outarray=arrays; by customer; id date interval=day accumulate=total; var withdrawals deposits; outarrays balance; balance[1] = deposits[1] - withdrawals[1]; do t = 2 to _LENGTH_; balance[t] = balance[t-1] + (deposits[t] - withdrawals[t]); end; run;Here is the example contrasting the data step with TIMEDATA when using an FCMP subroutine:
proc fcmp outlib=work.timefnc.funcs; subroutine movingAverage5term( series[*], ma[*]); outargs ma; actlen = DIM(series); do t = 1 to actlen; if ( t < 3 ) then ma[t] = .; else if ( t > (actlen - 2) ) then ma[t] = .; else ma[t] = (series[t-2] + series[t-1] + series[t] + series[t+1] + series[t+2])/5; end; endsub; run; quit; options cmplib = work.timefnc; proc transpose data=sashelp.air out=airtrans prefix=air; var air; run; proc print data=airtrans; run; data smooth_air; set airtrans; array air{144} air1-air144; array maair{144}; call movingAverage5term(air,maair); run; proc transpose data=smooth_air out=airma prefix=MA; id _name_; var maair1-maair144; run; proc print data=airma;run; proc print data=airma; run; proc timedata data=sashelp.air outarray=airMA2 print=(arrays); id date interval=month; vars air; outarrays maair; call movingAverage5term( air, maair ); run; proc print data=airMA2; run;Thank you, Tammy, for your feedback which shows totally different perspective. I would just add that PROC TIMEDATA is part of the SAS/ETS® software which provides a wide variety of tools/procedures for economic analysis, forecasting, economic and financial modeling, time series analysis, financial reporting, and manipulation of time series data.
Thanks a lot :), it's nice article.
It's a nice comment, thanks a lot, Vishnu 🙂
There are 3 approaches to combining observations from different points:
1) Multiple SET statements with WHERE clause
2) Transpose statement to convert all rows to a single row
3) SQL to combine to a single statement
However, it's important to remember that, for clinical trials, usually you want the "long skinny" organization with multiple observations per individual, because the appropriate tools are MIXED/GENMOD/GLIMMIX, which all require a TIME/VISIT variable under the SUBJECT. So all of this is changing the correct organization into an incorrect organization.
Thank you, Paul, for your input. I am sure there are way more than your suggested "3 approaches to combining observations from different points". One of them (#4) is presented in this blog post.
I love simple solutions and this code is so simple! So thanks!
Thank you, Bruce, I really appreciate your feedback.
My previous comment is not entirely complete. It should also include ...and IF each iteration is in fact reading an observation from the data set.
Check as an example following code and compare save_n_ with n:
data test; do n=1 to 1000; output; end; run; options firstobs=10; data ruin_n_; save_n_ = _n_; set test(where=(mod(n,5) ne 0)); run;Agree, FIRSTOBS= option and WHERE statement do not agree with _N_.
May be we should ask for new automatic variable: _CURROBS_ that contains the actual observation number that is processed. May be such variable exists, but I am not aware of it.
Erik, thank you for your input. I doubt that such automatic variable exists. However, if it did, it could be very confusing especially when used with such "trouble makers" as FIRSTOBS= option and/or WHERE statement. Without them, the data step iteration counter _N_ will work just fine as the "actual observation number that is processed".
Having a separate LAG and LEAD function does not make sense. So I vote for the HOP function. However I want to warn for a (little) shortcoming in the solution. You are using the _N_ automatic variable. In nine out of ten cases it will indeed correspond with the observation number. But it needs not to be the same. It is only the same IF you start to read at observation 1 and do not use a FIRSTOBS option.
Erik, thank you for your input and the warning. Indeed, FIRSTOBS=X option can be a distortion as _N_ will be equal to 1 for the actual X-th observation. I guess, for the %HOP macro that relies on the _N_ that is the limitation to not use FIRSTOBS= option.
I would like to add a vote in favor of the HOP function. I have never used the LAG function. If I have a simple need for accessing a value in another observation, a simple RETAIN works well. On the one occasion when I needed extreme flexibility to access values in a matrix-like way, then POINT= got the job done. (SAS/IML probably would have been perfect for the job, but I didn't know it.) I don't seen myself ever using the LAG function, but the HOP function would provide more functionality (no pun intended) and I could see myself using a HOP function if it existed. In the meantime, thanks for a clever macro.
Thank you, Susan, for your kind feedback and vote. The goal of this blog's exercise is to expand SAS data step programming functionality.
I think this can be a useful function. It solves a problem I once had when I needed to use the lag function in a somehow dynamic way. Then I needed to loop through the lag functions but could not do it because I could not dynamically change the name of the function (from lag to lag2 and so on) based on my data (without using a macro). With the Hop function, this problem would have been solved.
Of course the Hop function should be used with caution, but that goes for other functions as well.
Thank you, Kristian, for your input. I especially appreciate you sharing a real-life use case for the hop() function.
Very clever, and very well written Leonid. There are obviously alternatives, including 1) extracting and creating variables needed, then merging back to the main data set; 2) using an actual matrix, either with SAS arrays or with SAS/IML. However, there are always at least two ways to do anything in SAS, and I think this adds a nice alternative that provides ease of use, easy to understand, and programmer efficiency.
So, I vote for including it! Nice work. -Dave
Thank you, Dave, for your comment. I agree with you. That's why I like to have multiple and diverse tools in my SAS workshop.
Looks promising. Thank you.
Thank you, Grigori, for your input.
A goal of this exercise is to "access SAS dataset variable values similar to accessing elements of a matrix." For readers who have access to SAS/IML software, the built-in LAG (and DIF) functions in SAS/IML support positive and negative lags (lags and leads) of vectors and matrix columns. For more about lags and leads in SAS/IML, see my blog post about the LAG function or consult the SAS/IML documentation.
Thank you, Rick, for your comment and complementary references. While I did not mean SAS/IML software suggesting "access SAS dataset variable values similar to accessing elements of a matrix (Aij)", you bring up an excellent angle by injecting IML into this discussion.
Interesting! I am (was) very keen on testing facilities, but Very restrictive in using them in HEAVY production.
It turned out the other day, that I have never used DO.. WHILE and DO.. UNTIL in HEAVY production.
Of course I have tested them, used it as a SAS teacher. But never in heavy production - for good reasons.
Anders, thank you for your comment. Could you please clarify what you mean by "heavy production" vs. light production or just production. From my experience, there are so many different production environments with different optimization criteria - from optimizing program development cycle (when program runs just once) to optimizing processing time (when program operates on big data in interactive applications). Some optimization is done programmatically, some may require hardware solutions...
Hi Leonid,
This is very helpful! I have one naive question. In the %hop, the _o_ which will have number of observations in a dataset, is assigned a value at the end of SET statement but is referenced in the if condition before the SET statement. Can you please help me to understand how this works i.e. how the if condition gets executed with _o_ before it is even defined?
Thanks,
Tata
Thank you, Tata, for your comment. You asked one very good question! The key here is that the SET statement option nobs= assigns a value to the _o_ variable during data step compilation, that is before execution. Therefore, it is available in the IF statement's condition during the data step execution. Try running this perfectly legitimate code:
data _null_; call symputx('num',n); stop; set sashelp.air nobs=n; run; %put &=num;Even though SET statement never gets executed (it is placed after STOP statement that terminates data step), macro variable num is assigned its value in the CALL SYMPUTX based on the value of n.
Thanks a lot!! Very interesting article. Will look forward for next interesting article.
Brilliant! The value of j is even not necessarily a constant integer. It could be any integer variable. So how far to hop is really based on the value of the variable at current observation.
Thank you, Jerry. You are absolutely correct: the value of j can be either integer constant or a value of numeric variable at the current observation.
Smart. Very, very smart.
It opened my eyes for the possibility of writing my own macro functions that can be used within datastep. Thank you.
Bartosz, thank you for your comment. I hop(e) this empowers you in your SAS programming efficiency.
I like your out-of-the-box thinking!
Thank you, Tricia! I am humbled by your appreciation.
Great post!
I will be happy to learn this new function.
Thanks a lot.
Thanks, Mamadou! Meanwhile, you can use %hop macro as a substitution.
Nice out of the box thinking. Yes, would vote for it. It would surely add some things as some spreadsheet (Static) or streaming thinking.
Seeing the LAG function as a limited queue (may be renaming is sensible ) it has value in combination with a HOP().
The power of SAS is not in being a follower, doing the same things as others do.
The power of SAS is in doing things others haven't thought of yet.
Tell Jim if you like.
To explain the possible usage.
When processing a record knowing information needed somewhere several records before or expecting it somewhere several records later, then hopping to those (smart limited) would often make things much easier and with a far better performance behavior.
It would be even possible processing a large table in a big queued approach while sending out new messages.
For this kind of solutions I normally spend a lot of time in designing the needed behavior and test it until it works as desired.
The alternative of grouped SQL processing is a serial slow approach only having nice with the best tools/hardware.
Still having those needed delays in wall-clock time for the split in those several steps being planned.
Thank you, Jaap, for your kind feedback and your very powerful words about the power of SAS.
Here's a version using point that 1) doesn't require an index, and 2) is closer to the actual problem statement.
data test; do SK=1 to 20; fail_flag=SK in (2,9,13,15,18,20); date_in=SK; date_out=SK+int(ranuni(123)*10)+3; output; end; format date: date9.; drop sk; run; data test3; set test nobs=nobs; if fail_flag then do; i=_n_-2; j=_n_+1; if i gt 0 then set test (keep=date_in rename=(date_in=_date_in)) point=i; if j lt nobs then set test (keep=date_out rename=(date_out=_date_out)) point=j; delta=_date_out-_date_in; end; output; call missing(of _date:); run;Hi Scott, thanks for sharing your code sample. However, I don't see how your code sample is an alternative as it is practically identical to the solution described in this blog post using %hop macro with the exception of you setting temporary variables to missing values while I just drop them.
The index key lookup (double set statement) also allows random access to a SAS dataset. So does a hash object, but that doesn't work for memory constrained conditions. But it requires an index to be built.
Hi Scott, thank you for your feedback. I am not sure I fully understand how "index key lookup" relates to "double set statement", and why "double". A single set statement with point= option does allow for direct (random) access. I would love to see your hash object implementation of the HOP functionality.
Hi Leonid,
Thank you for this little gem. Actually, I clipped this article to my snippet library. You taught us again that SET statement is much more versatile than its typical usage - once per a DATA step. My own solution used a couple SQL clauses with MONOTONIC(). Your four lines of code beat it hands down. Right on!
Anton, thank you for your comment. We all learn from each other.
FYI in your %HOP() macro I'm concerned about POINT=, which can be very dependent on record buffering for fast processing. There is an example in my 1st SAS book "Saving Time and Money Using SAS" (SAS Press) where I reduced a mainframe Data Step's elapsed time from 7 hours to 3 minutes just by sorting the data set with POINT=, and that 3 minutes included the PROC SORT step time!
Philip, your concern is well-taken. However, you are switching to a different topic. In this post the accent is on effective programming, while your concern is efficient processing. In many cases, take clinical trials for example, SAS programmers deal with relatively small data tables, while very complex calculations and very tight deadlines. In such cases they are not at all concerned with the processing speed, but are very much concerned about the speed of program development.
Hi Philip,
I do understand your performance concerns. But they also say that "premature optimization is the root of all evil". For example, I work mostly in pharma statistical programming and the analysis programs here typically run in production mode only a few times during the project, most datasets are not huge so programming time > run time. And if it is not, it is typically statistics what consumes most cycles. So personally I found Leonid's little macro to be clever, thought-provoking and potentially useful. But if I encounter hard performance limits, I can always pick up your book you so courteously referred to.
Niiice! I was expecting something FAR more complex at the end. Was thinking 'fcmp + open()' whilst reading it but the macro approach is definitely easier to absorb.
Allan, thank you for your comment. If you find an alternative solution along your thinking 'fcmp + open()', I would love to hear from you.
I'm not sure if I would ever use this HOP() function, simply because it needs too many restrictive conditions. For questions like this I use a "range" merge in PROC SQL, where a match can be made where, say, value (date?) in data set B is between date and date+14 in data set A. I can also calculate the difference in these dates to find the closest record in B to date in A. The PROC SQL code would not be restricted to sequential, or even neighbouring, records.
Or maybe I've not understood how HOP() could be useful?
Thank you, Philip, for your feedback. What restrictive conditions do see are needed? I only see that you must be within the data table boundaries to be able to grab any value of any variable for calculations. The HOP() function described in this post relates to calculations within a single data table.
I would still use PROC SQL to match records in the same data set. I can now see its benefit for SAS programmers without SQL experience, but would request a "health warning" be attached to HOP(), as I can envision some pretty horrendous speed issues if misused. LAG() works well within the Data Step model, because it is used within sequential record input. HOP() will require asynchronous file reads, which could bring processing of a large data set to its knees.