Trusted data is key to driving accurate reporting and analysis, and ultimately, making the right decision. SAS Data Quality and SAS Data Management are two offerings that help create a trusted, blended view of your data. Both contain DataFlux Data Management Studio, a key component in profiling, enriching monitoring, governing and cleansing your data. Clustering, or grouping similar names or addresses together, is one data quality activity that helps to reduce the number of duplicates in a given data set. You do this by using fuzzy matching to group similar names or addresses together. As an example, a marketing analyst might want to remove duplicate customer names or addresses from a customer list in order to reduce mailing costs.
Have you ever wondered how the cluster results would differ if you changed the match code sensitivity for one of your data columns, or removed a column from one of your cluster conditions or added a new cluster condition? Well, wonder no more!
The Cluster Diff node in DataFlux Data Management Studio compares the results of two different Clustering nodes based on the same input data. This is useful for comparing the results of different cluster conditions and/or different match code sensitivities.
All records from the input set must be passed to both Clustering nodes and both Clustering nodes must pass out all their data in the same order for this comparison to work. To summarize, in both Clustering nodes, you must select the All clusters output option and you cannot use the Sort output by cluster number option.
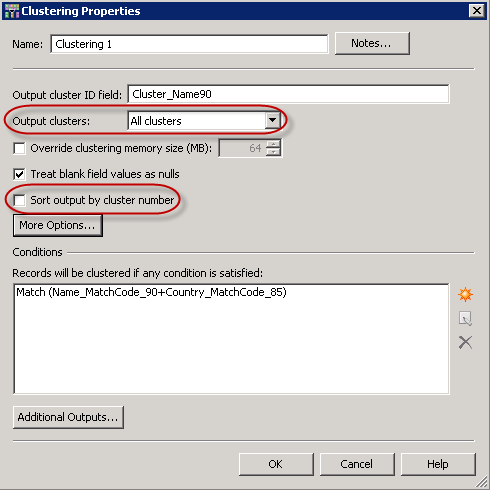
The results of both Clustering nodes are then fed into the Cluster Diff node. In order to perform the comparison, the Cluster Diff node must know the unique identifier for the input records (Record ID) and the Cluster number that is returned from the respective Clustering node.
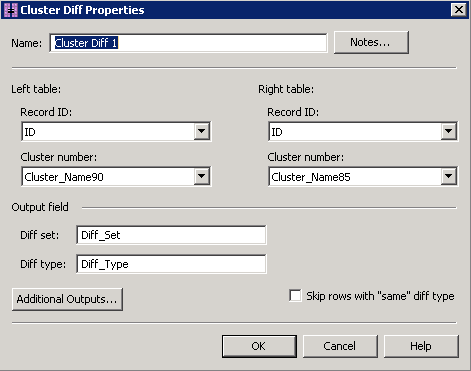
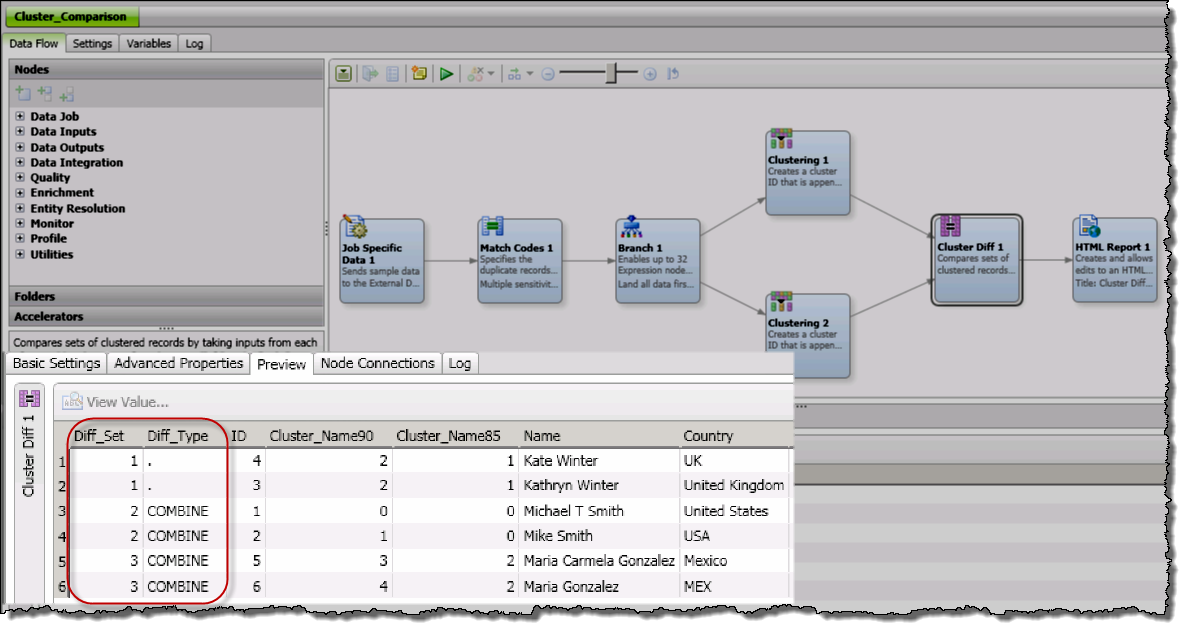
The Diff type value describes the type of change when performing the cluster number comparison between the two Clustering nodes. The possible values for Diff type include COMBINE, DIVIDE, NETWORK, and SAME which is represented as a period (.). When comparing the results of the two Clustering nodes the results are reviewed as a Diff set. Within a Diff set:
- If the records were in different clusters on the “left table” and in the same cluster on the “right table,” then its Diff type is COMBINE.
- If the records were in the same cluster on the “left table” and in different clusters on the “right table,” then its Diff type is DIVIDE.
- If the records were in same cluster on the “left table” and in the same cluster on the “right table,” then its Diff type is “.” (SAME).
- If when comparing the “left table” cluster to the “right table” clusters at least one record is added to the cluster AND at least one record is removed from the cluster, then its Diff type is NETWORK.
The Cluster Diff node is not a node that is typically used in a production matching job. However, it is a node that is useful in helping you compare and contrast different match code sensitivities and/or cluster conditions that enable you to achieve the best matching results for your data set.
