Scalability is the key objective of high-performance software solutions. “Scaling out” is a concept which is accomplished by throwing more server machines at a solution so that multiple processes can run in dedicated environments concurrently. This blog post will briefly touch on several scalability concepts that affect SAS.
Functional roles
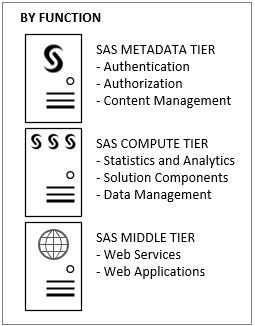 At SAS, we have a number of different approaches to tackle the ability to scale our software across multiple machines. As we often see with our SAS Enterprise Business Intelligence solution components, we’ll split up the various functional roles of SAS software to run on specific hosts. In one of the most common examples, we’ll set aside one machine for the metadata services, another for the analytic computing workload, and a third for web services.
At SAS, we have a number of different approaches to tackle the ability to scale our software across multiple machines. As we often see with our SAS Enterprise Business Intelligence solution components, we’ll split up the various functional roles of SAS software to run on specific hosts. In one of the most common examples, we’ll set aside one machine for the metadata services, another for the analytic computing workload, and a third for web services.
While this is more complicated than deploying everything to a single machine, it allows for a lot of flexibility in providing responsive resources which are optimized for each role. Now, we’re not limited to just three machines, of course.
Read more:
SAS® 9.4 Intelligence Platform: Overview
Clusters
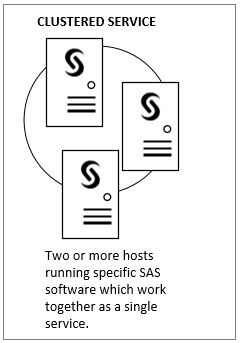 For each of these functional roles – Meta, Compute, and Web – we can scale them out independently of the others. Depending on the technology involved, different techniques must be employed. The Meta and Web functional roles, in particular, are well-equipped to function as clusters.
For each of these functional roles – Meta, Compute, and Web – we can scale them out independently of the others. Depending on the technology involved, different techniques must be employed. The Meta and Web functional roles, in particular, are well-equipped to function as clusters.
Generally speaking, a software cluster is comprised of services that present as peers to the outside world. They offer scalability and improved availability where any node of the cluster can perform the requested work, continue to offer service in the face of failure of one or more nodes (depending on configuration) and other features.
Read more:
- SAS® 9.4 Intelligence Platform: System Administration Guide, Third Edition
- SAS® 9.4 Intelligence Platform: Middle-Tier Administration Guide, Second Edition
Grids
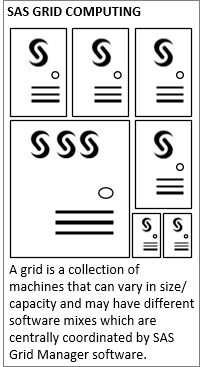 The Compute functional role has some built-in ability to act as a cluster if the necessary SAS software is licensed and properly configured – which is pretty great already – but this ability can be extended even further to act as a grid. A grid is a distributed collection of machines that process many concurrent jobs by coordinating the efficient utilization of resources which may vary from host.
The Compute functional role has some built-in ability to act as a cluster if the necessary SAS software is licensed and properly configured – which is pretty great already – but this ability can be extended even further to act as a grid. A grid is a distributed collection of machines that process many concurrent jobs by coordinating the efficient utilization of resources which may vary from host.
With proper implementation and administration, grids are very tolerant of diverse workloads and a mix of resources. For example, it’s possible to inform your grid that certain machines have certain resources available and others do not. Then, when you submit a job to the grid, you can declare parameters on the job that dictate the use of those resources. The grid will then ensure that only machines with those resources are utilized for the job. This simple illustration can be implemented in different ways depending on the kind of resources and with a high-degree of flexibility and control.
Another common component of clusters and grids is the use of a clustered file system. A clustered file system is visible to and accessed by each machine in the grid (or cluster) – typically at the exact same physical path. This is primarily used to ensure that all nodes are able to work with the same set of physical files. Those files might range from shared work product to software configuration and backups, event to shared executable binaries. The exact use of the clustered file system can of course vary from site to site.
Read more:
- SAS® 9.4 Grid Manager product documentation
- SAS® 9.4 Intelligence Platform: Application Server Administration Guide
- A Survey of Shared/clustered File Systems
Massively Parallel Processing
 Extending grid computing even further is the concept of massively parallel processing (or MPP). As we see with Hadoop technology and the SAS In-Memory solutions, a number of benefits can be realized through the use of carefully planned MPP clusters.
Extending grid computing even further is the concept of massively parallel processing (or MPP). As we see with Hadoop technology and the SAS In-Memory solutions, a number of benefits can be realized through the use of carefully planned MPP clusters.
One common assumption behind MPP (especially in the implementation of the SAS In-Memory solutions) has historically been that all participating machines are as identical as possible. They have the same physical attributes (RAM, CPU, disk, network) as well as the same software components.
The premise of working in an MPP environment is that any given job (that is, something like a statistical computation or data to store for later) is simply broken into equal size chunks that are evenly distributed to all nodes. Each node works on the problem individually, sharing none of its own CPU, RAM, etc. with the others. Since the ideal is for all nodes to be identical and that each gets the same amount of work without competing for any resources, then complex workload management capabilities (such as described for grid above) are not as crucial. This assumption keeps the required administrative overhead for workload management to a minimum.
Read more:
Hadoop and YARN
Looking forward, one of the challenges of assuming dedicated, identical nodes and equal-size chunks of work in MPP has been that it’s actually quite difficult to keep everything equal on all nodes all of the time. For one thing, this often assumes that all of the hardware is exclusive for MPP use all of the time – which might not be desirable for systems which sit idle overnight, on weekends, etc. Further, while breaking workload up into equal-size bits is possible, it’s sometimes tough to keep the workload perfectly equal and distributed when there exists competition for finite resources.
For these and many other reasons, Hadoop 2.0 introduces an improvement to the workload management of a Hadoop cluster called YARN (Yet Another Resource Negotiator).
The promise of YARN is to better manage resources in a way accessible to Hadoop as well as various other consumers (like SAS). This will help mature the MPP platform, evolving it from the old Map-Reduce framework to a more flexible platform to handle a wider variety of different workload and resource management challenges.
And of course, SAS solutions are already integrating with YARN to take advantage of the capabilities it offers.
Read more:
- Hadoop: What it is and why it matters
- SAS® 9.4 Guide to Software Updates
- SAS high-performance capabilities with Hadoop YARN
- Share your cluster – How Apache Hadoop YARN helps SAS
