 A family and its members represent a simple hierarchy. For example, the Jones family has four members:
A family and its members represent a simple hierarchy. For example, the Jones family has four members:
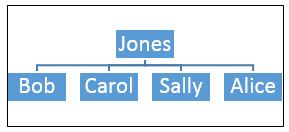
A text file might represent this hierarchy with family records followed by family members' records, like this:
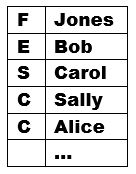
The PROC FORMAT step below defines the codes in Column 1:
proc format; value $type 'F'='Family' 'E'='Employee' 'S'='Spouse' 'C'='Child'; run; |
A hierarchical file is defined by a header record (such as a family record) followed by any number of detail records (such as family members records). While our simple family hierarchy has only two levels, in the business world, a hierarchy can have any number of levels. For example, medical claims data has at least five levels:
- Insured person
- Insured person's dependents
- Patient (insured person or dependent)
- Provider (physician, lab, hospital, etc.)
- Service (date, DX, $, etc.)
This blog will use our simple family hierarchy, with only two levels, but the illustrated techniques can be generalized to any number of levels. The Family record (TYPE='F') represents a header record. All other records represent detail records.
While a text file can represent a hierarchy, modern databases are relational and rectangular. Therefore, a data step must "flatten" the hierarchy to create a rectangular SAS dataset.
This blog is the first in a series of blogs which will illustrate three different solutions to flattening a hierarchical file.
Solution 1 creates one observation per header record, summarizing the detail data with a COUNT variable, like this:
Summary Approach: One observation per header record Obs Family Count 1 Jones 4 2 Sanchez 1 3 Smith 2 ===== 7 |
The above solution is concise, but detail data is lost. Solution 1 is illustrated in today's blog.
Solution 2 also creates one observation per header record, but includes detail data, in a wide format, like this:
Detail Approach: One observation per header record Obs Family Employee Spouse Child1 Child2 Child3 1 Jones Bob Carol Sally Alice 2 Sanchez Mary 3 Smith Nancy Harold |
The above solution is readable for a small number of detail items, but is impractical for larger numbers of detail items. This example allows for up to three children, an arbitrary number, and obviously unrealisic. How many children should we allow for? 10? 15? With mostly missing values? You see the problem.
Solution 3 contains identical data to Solution 2, but in a tall format, with one observation per detail record, like this:
Detail Approach: One observation per detail record Obs Family Person Type 1 Jones Bob Employee 2 Jones Carol Spouse 3 Jones Sally Child 4 Jones Alice Child 5 Sanchez Mary Employee 6 Smith Nancy Employee 7 Smith Harold Spouse |
The above solution is practical for any number of detail items, with no arbitrary limit to the number of children, and no missing values.
All three solutions "flatten" the hierarchical text file to create a rectangular SAS dataset.
All three solutions are efficient because:
- Sorting is not required
- A single DATA step is used
The following DATA step imports the text file into a SAS dataset. This is not a solution:
data not; infile 'c:\temp\families.txt'; input Type: $1. Name $; run; title 'Not a Solution'; proc print data=not; var name type; format type $type.; run; |
Not a Solution Obs Name Type 1 Jones Family 2 Bob Employee 3 Carol Spouse 4 Sally Child 5 Alice Child 6 Sanchez Family 7 Mary Employee 8 Smith Family 9 Nancy Employee 10 Harold Spouse |
The above approach is not a solution because the meaning of an observation is ambiguous. What do the 10 observations represent?
10 families? No!
10 family members? No again!
Some observations represent a family. Other observations represent family members. Worse, family data are not linked to family members' data. For example, "Bob" and "Jones" appear on separate observations, when they should appear on the same observation.
Today's blog will present Solution 1, a summary approach with one observation per header record, without detail data, like this:
Summary Approach Obs Family Count 1 Jones 4 2 Sanchez 1 3 Smith 2 ===== 7 |
Subsequent blogs will present solutions 2 and 3, which preserve detail data.
As a reminder, the data step for our non-solution looked like this:
data not; infile 'c:\temp\families.txt'; input Type: $1. Name $; run; |
Let's modify the non-solution above to output one observation per header record, by adding a KEEP statement and a sub setting IF statement, like this:
The saslog below shows a read count of 10 and a write count of 3. Perfect!
1186 data summary1; 1187 keep Name; 1188 infile 'c:\temp\families.txt'; 1189 input Type: $1. Name $; 1190 if type='F'; * Header records only; 1191 run; NOTE: 10 records were read from the infile 'c:\temp\families.txt'. The minimum record length was 5. The maximum record length was 9. NOTE: The data set WORK.SUMMARY1 has 3 observations and 1 variables. |
The results look like this:
Summary Approach Obs Name 1 Jones 2 Sanchez 3 Smith |
That was easy! We just need to add a COUNT variable and we're done for today!
Initializing the COUNT variable and controlling the output is tricky without a BY statement and FIRST. / LAST. variables, but nothing we can't handle!
Here's Solution 1. The log below shows a read count of 10 and a write count of 3, identical to our simple version above.
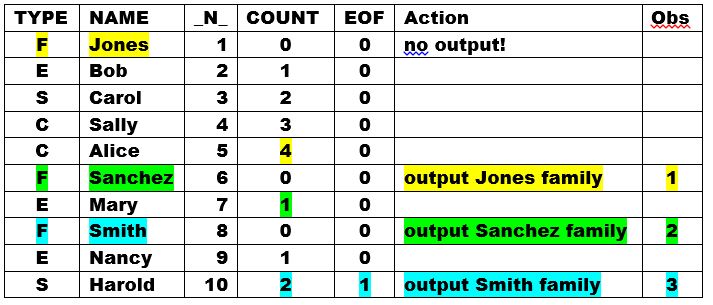
930 data summary2; 931 keep Family Count; 932 retain Family; 933 infile 'c:\temp\families.txt' end=eof; 934 input Type $ Name $; 935 if type='F' then do; * Family record; 936 if _N_ > 1 then output; 937 Family=Name; 938 Count=0; 939 end; 940 else Count+1; * Family member record; 941 if eof then output; * Last record; 942 run; NOTE: 10 records were read from the infile 'c:\temp\families.txt'. The minimum record length was 5. The maximum record length was 9. NOTE: The data set WORK.SUMMARY has 3 observations and 2 variables. |
The RETAIN statement holds the value of the FAMILY variable in memory until the next "F" record, which causes the DO group to:
- output one observation per header (family) record
- overwrite the retained value of the FAMILY variable with the NAME of the next family
- initialize the retained value of the COUNT variable back to zero for the next family.
The value of the COUNT variable is also retained because it appears in a sum statement
ELSE COUNT+1;
where it counts the detail records (family members) for each family when TYPE is not 'F';
Since there is no final 'F' record to trigger the DO group for the last family, the final statement
IF EOF THEN OUTPUT;
outputs the last family. EOF is an end-of-file flag, created by the END= option on the INFILE statement.
The table below illustrates how the above program works.
This blog has gotten long enough, so I will stop here, for today, but watch this space for my next blog, which will illustrate Solution 2, which, like Solution 1, creates one observation per header record, but includes detail data, in a wide format, like this:
Detail Approach: One observation per header record Obs Family Employee Spouse Child1 Child2 Child3 1 Jones Bob Carol Sally Alice 2 Sanchez Mary 3 Smith Nancy Harold |




9 Comments
Hi Jim,
How can I read these kind of data in sas, any example? I have schema and I have tried mapping too, but I am having hard time.
Please help with any example.
Thanks in advance.
Hemant
Jim,
I think that this set of blogs on reading hierarchical data is an excellent series. Thank you! I've got one question - how is the total count (7) generated and printed? Or is that left as an exercise for the student?!
Kathleen
Hi Kathleen. Thank you for posting. The total count (7) is generated by adding SUM COUNT; to the PROC PRINT step (not shown).
Pingback: Reading Hierarchical Data - Part 3
Pingback: Reading hierarchical data (Part 2) | SAS Training Post
And..the 1987 edition of the SAS Applications Guide has an example of how to read in the Census Public Use hierarchical files. (An earlier edition included JCL for reading the Public Use files from tape!)
Thanks Jim, could you please explain > macro in the last code example?
Hi Daria,
Thank you for noticing the >. That happens when I'm editing the posts in different views. I have fixed the code. -Maggie, SAS Training Post Editor
Ok thank you! Makes sense now! Looking forward to the next post :)