SASではグラフ理論(グラフ分析と言ったりもします)や、そのビジュアライゼーションを容易に実践することができます。本ブログでは、何回かにわたりこのトピックを扱っていきたいと思います。グラフ(ネットワーク)は世の中のあらゆるところに存在します。リレーショナルデータベースのER図として抽象化されている世界(企業の業務など)とは異なり、現実の世界では全てのモノが相互に関連しています。昨今注目されているIoTにおいても単に生成されるデータを個別に分析するだけでなく、それによってつくられたネットワークそのものを分析対象にすることで新たな洞察が生まれる期待も大きいと考えられます。今回はまずソーシャルネットワークを例にその様子を紹介していきます。
はじめに
IoTに代表される昨今のように全てが相互に接続された世界では、ある一つのモノそのものを詳細に分析するだけでなく、異なるモノとモノ同士がお互いにどのように関連しているかも理解することの重要性が増しています。ソーシャルネットワークは、モノやサービスについて消費者がどのように考えているか、あるコミュニティが自社に関係のある別のコミュニティとどのようにリンクしているのか、インフルエンサー(情報発信力あるいは影響力をもつ人々)はどこにいるのかなどについて驚くべき事実を提供してくれることが多いのです。このようなネットワークについて理解することで、自社のビジネスにとって役立つ洞察を与えてくれたり、次のマーケティングキャンペーンにおいて誰をターゲットとすべきかについての意思決定に役立つでしょう。
ネットワーク(グラフ)
ネットワークとはモノ(ノード)と、それらモノとモノとを接続するリンクの集合によって構成されます。リンクによって様々な関係性を表現できます。この定義は非常に一般的ですが、我々はありとあらゆるところで、このネットワークを見出すことができます。
数学的には、ネットワークはグラフと呼ばれています(データビジュアライゼーションで使われるグラフとは異なる意味なので注意してください)。相互に接続されたモノは数学的には頂点といい、頂点と頂点を結ぶリンクは、エッジ(辺)といいます。グラフの性質は数学、工学さらには社会科学といった領域でグラフ理論という研究対象となっています。
一方で、ネットワーク・ビジュアライゼーションはこのグラフをビジュアルに表示するためのものです。もっとも一般的な形は、リンクノードダイアグラムで、頂点を表す点または円があり、それらが辺を表す直線や曲線でつながっているものです。頂点の属性は、大きさや色、形にマップされ、辺の属性はリンクの幅や色にマップすることができます。
辺の属性として重要なのが「方向」です。ほとんどの関係性(リンク)は方向性がない、対称なものです。例えば、Facebookにおける友人などがそれにあたります。しかし「方向」があり非対称なネットワークもあります。Twitterにおける"フォロー"がそうです。このような場合には、ビジュアライゼーションは矢印などのような線で関係性の方向を表現することができます。
ソーシャルネットワーク
複雑系の一つの特徴的な側面であり、またそれが全体を予測することを困難にしている理由の一つでもあるものに、それを構成する構造と各構成要素の振る舞いとの間の相互作用があげられます。
その相互作用は、ソーシャルネットワークにおいて特に顕著にみられます。あなたを知っている人があなたの行動に影響を与えたり、またその逆であったりするでしょう。この後紹介するように、ネットワークは「アクター」(人間のことが多いですが、時には自動化されたコンピュータ・エージェントであったり、組織であったりします)によって構成され、それぞれの間の関係性や行動(フォロー、いいね!やリツイート)によって関連付けられます。「アクター」の行動による影響は、関連付けられている別のアクターに対して広範囲に作用します。つまり、全体の中で重要な位置にいるアクターは、グループ全体に対して大きな影響を与えることができるのです。
では、我々はどのようにソーシャルネットワークを理解すればよいのでしょうか?基本的な問いから始めてみます。
- ネットワークの基本的な構造はどうなっているか?ひとつの団結したグループなのか?それとも緩くつながった強固なコミュニティなのか?
- インフルエンサー(影響力のある人)は誰なのか?
これらの問いを総合するとネットワークの影響がお互いにどのように作用しているのかをマクロな視点とミクロな視点で明らかにすることができます。
データ準備
今回は、ソーシャルネットワークの分析を紹介するためにツイッターデータを使用します。SAS Visual Analyticsでは、ツイッターデータを取り込むことが可能ですが、非常に大きなデータをインポートするとデータが非常に膨大になります。そのような場合にネットワークをよりよく理解するために、ネットワーク分析のためのツールであるSASのOPTGRAPHプロシジャを使用します。将来のバージョンでは同様のことをSAS Visual Analytics上だけでテキスト解析やフォーキャスティングと共に利用できることになる予定です。
この例では、#SASUSERS, #SASSGF14といったハッシュタグで抽出したツイッターデータを使用します。このデータは以下のような構造をしています。
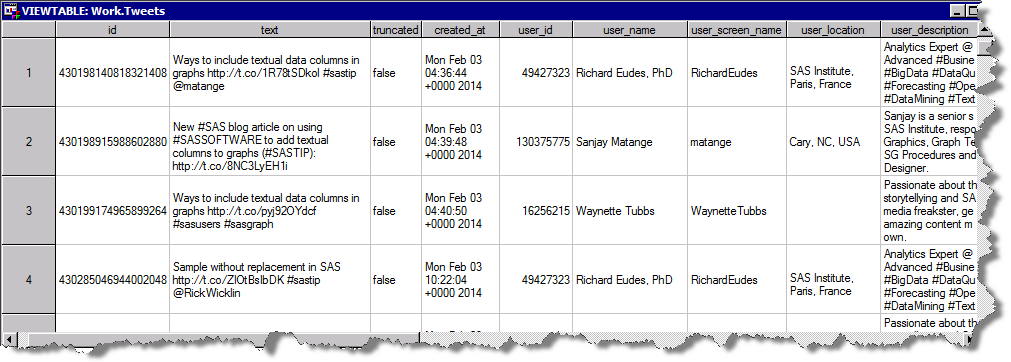
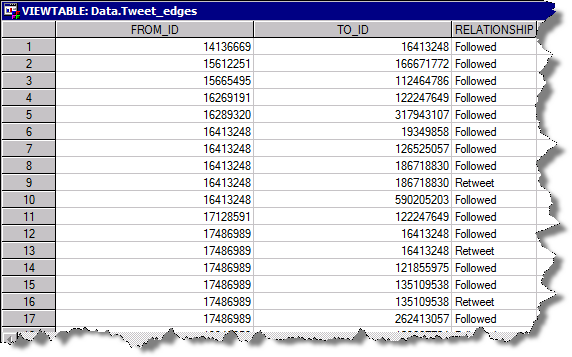
前述したように、このネットワークは、これらのツイートをしているユーザーたちと(テキストそのものは今回は関係ありません)、それぞれのユーザー間の関係性(AがBをフォロー)によって表現されます。その情報に基づいて、二つの列、FROM_IDとTO_ID(このIDはツイッターのユーザーIDです)を使用したデータ構造を作成します。RELATIONSHIP列は、このリンクの意味を表現しています。
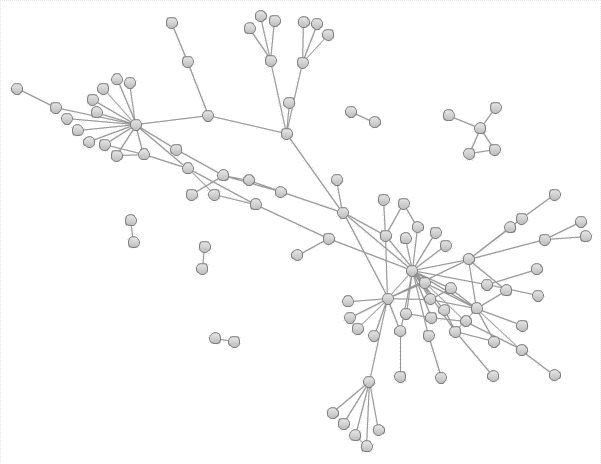
このテーブルをSAS Visual Analyticsにロードしてみるだけでも、以下のような興味深いネットワーク構造を見ることができます。
フォローワーの数などを人の属性に設定することにより、このネットワークに含まれている人あるいは組織についての最初の洞察を得ることができます。
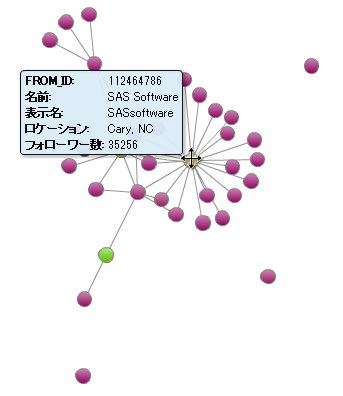
もちろん、このように考える方もいるでしょう。フォローワーの数が多いからといっても必ずしもその人物がネットワーク上の重要な人物とは限らないだろう、と。では、より深く理解するためにコミュニティとキーとなるアクターを特定する方法を見てみましょう。
コミュニティの検出
コミュニティの検出、あるいはクラスタリングとは、つながりの強いノード同士をグループ化してネットワークをいくつかのサブ・ネットワークに分解していくプロセスです。
SASではこのようなグラフ分析のためのツールOPTGRAPHプロシジャを提供します。OPTGRAPHが提供する様々な機能はまたの機会にご紹介します。今回は、このコミュニティ検出に使用したいと思います。以下の例では、指定した分解解像度に基づいて、一度に二種類のコミュニティグループの計算をしています。解像度を大きくするとより多くのコミュニティを生成することができます。
proc optgraph loglevel = moderate data_links = data.tweet_edges out_nodes = work.tweet_groups graph_internal_format = thin; data_links_var from = from_id to = to_id; community resolution_list = 1.0 0.5; run; |
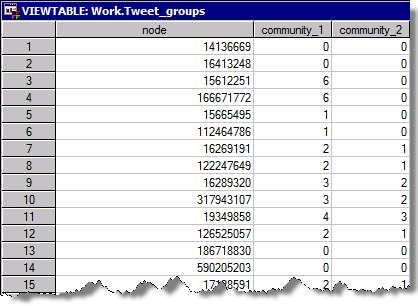
ここで計算されたコミュニティ情報を先のデータに結合してSAS Visual Analyticsに読み込み、色役割にコミュニティ番号を指定することで、その様子をビジュアライズすることができます。
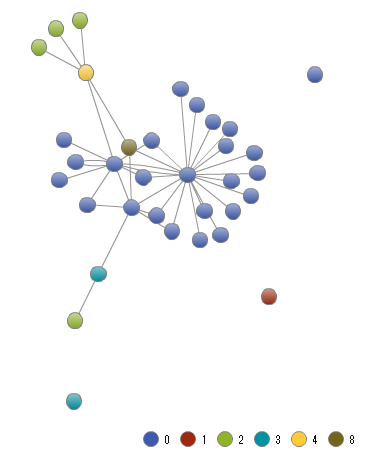
このような小さなグラフ(ネットワークという意味です)では、ビジュアライゼーションだけでも多くの洞察を得ることができます。人間の目で見ても、ネットワーク上にあきらかな分岐箇所を見て取ることができますし、端の方では長い「ペンダントチェーン」のような構造もパッと見て把握することができます。しかし、コミュニティ検出手法を使用することでこのネットワーク構造についてさらなる洞察を得ることが可能となります。
コミュニティの情報を使用することで、コミュニティを色分けしそれぞれを比較することができるようになりますし、コミュニティ情報をフィルター条件に使用することもできます。一般的にビジュアライゼーションにおいて懸念されることの一つに、ビジュアライゼーションの結果そのものが大きすぎたり、複雑すぎたりすることで、人間の認知能力の限界を超えてしまい、理解そのものが困難になったり、有用な洞察を見落としてしまう可能性があげられます。このように、データを絞りながら、より多くの詳細な情報をラベルやリンクの方向性として表示することができるので、注目したいコミュニケーションを切り替えながら、より詳細な情報を探索していくことが可能となります。
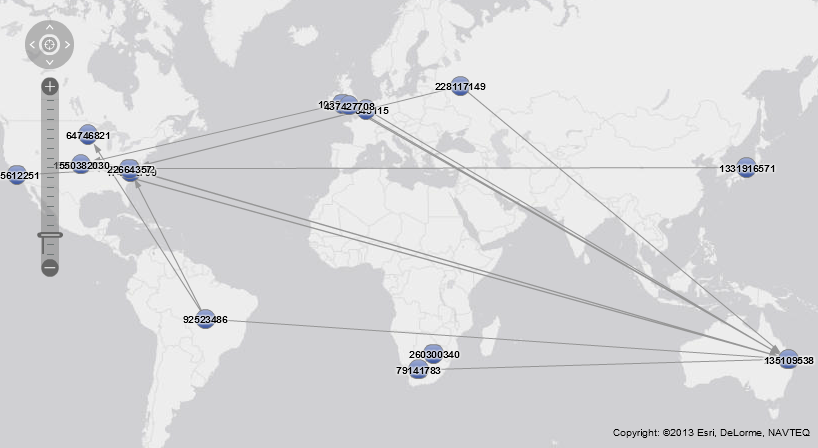
ツイッターに登録しているユーザーの多くはプロファイル属性のロケーションを登録しています。したがってジオコーディングすることによって、ネットワークを地図上にマップすることも可能です。このようにすることで、ネットワークのノードやコミュニティを選択する際に地理的な情報を利用することも可能となります。
「重要人物は誰か?」分析
ネットワーク上の重要な人物、あるいは中心人物を決定するにはいくつかの評価指標があります。
- 媒介中心性(Betweenness)は、あるノードが他のノードの最短経路である度合いを指標にしたものです。値が高ければ高いほど常に情報流通の中にいることを表しています。例えば、関所の番人や会社組織における承認者など、そこを通過しなければならないので、そこには情報が流通し影響力が生まれるケースも一つ例です。「いろんな顔を持つ人」(音楽もやるし、スポーツもやるしお茶もたしなんで、色々な種類の人と交流がある)と定義しても良いかもしれません。
- 固有ベクトル中心性(Eigenvector centrality)とは、隣接するノードの中心性を加味する指標です。Googleのページランクが例として挙げられます。値が高いことは、そのノードが他のポピュラーなノード中でポピュラーであることを表しています。これは例えば、組織やクラスの中で影響力のあるコミュニティに顔がきく人を思い浮かべるとわかりやすいでしょう。「大事な場面には常にいる人」みなさんのまわりにもいると思います。
- 次数中心性(Degree)は、どれだけ多くのノードがそのノードにリンクしているかという指標です。非常にシンプルな指標であり、例えば何人友人がいるか、フォローワーが何人か、などです。その人自身に情報発信能力があることを示しています。「いわゆる人気者・いつもいい情報を提供してくれる人」です。
- 近接中心性(Closeness)は、他のノードとの距離をもとにした指標です。全ての人と近しい人が高いスコアとなります。例えるなら、「誰とも好き嫌いなく分け隔てなくコミュニケーションをとれる人」でしょうか。
- 影響力(Influence)は、次数中心性を一般化したもので、リンクの重みとリンク先に繋がっているノードの重みを考慮に入れたものです。この指標は、PROC OPTGRAPHでも利用可能であり、シンプルな計算で済むため大規模グラフにも適用することが可能です。
OPTGRAPHプロシジャの例を見てみましょう。
proc optgraph loglevel = moderate data_links = data.tweet_edges out_links = work.tweet_edges out_nodes = work.tweet_nodes; data_links_var from = from_id to = to_id; centrality clustering_coef degree = out influence = weight close = weight between = weight eigen = weight; run; |
結果として二つのテーブルが作成されます。ひとつめのテーブルにはノード(ツイッターデータの場合にはユーザー)属性が格納されています。
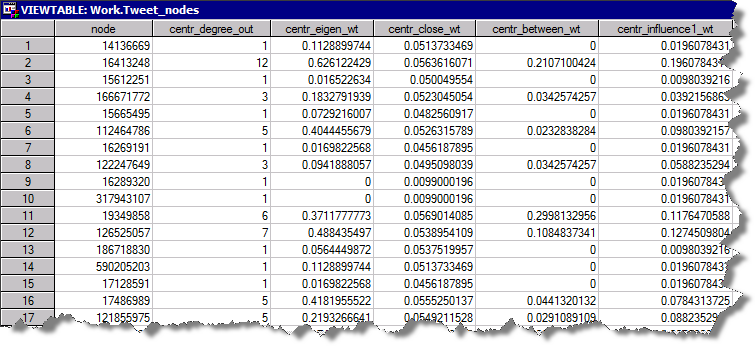
二つ目のテーブルにはリンクの属性が格納されています。
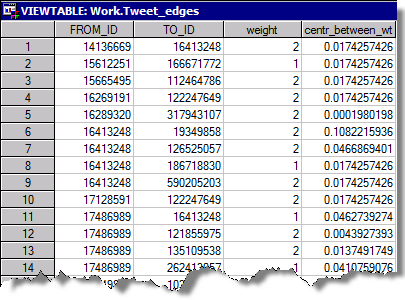
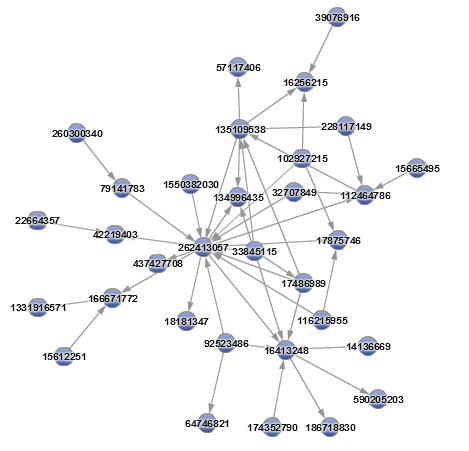
先ほどと同様に、もともとのネットワークデータにこれらの情報を結合し、SAS Visual Analyticsにロードします。そうするとキープレーヤーに関する興味深い詳細についての情報を得ることができます。
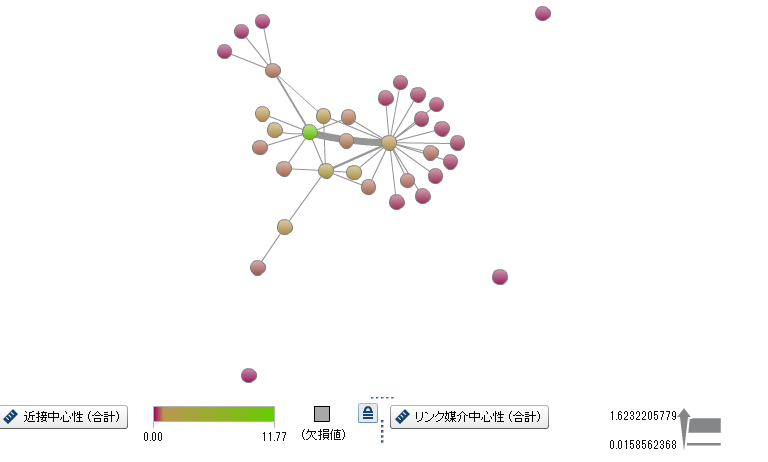
また、固有ベクトル中心性と媒介中心性のスコアをプロットすることにより、ソーシャルネットワークにおける重要なノードを特定することが可能です。両方の指標が共に高いノードは明らかに重要なノードです。しかし、どちらか一方だけが飛びぬけて高いスコアの場合にも、重要な特定の役割を担っているノードと考えられます。
媒介中心性スコアが高く、固有ベクトル中心性スコアが低い場合には、中心となるノードへの唯一のパスを担っている可能性があります。つまり、「門番」であり、ともすれば孤立しているはずのノード群を中心となるネットワークに中継しているケースです。一方、媒介中心性スコアが低く、固有ベクトル中心性スコアが高い場合には、ネットワークのコアメンバーとよくつながっており、「常に様子をうかがっている人」と考えられます。
SAS Visual Analyticsを使用してこの分析を行うことは非常に簡単です。バブルプロットを使用することができます。
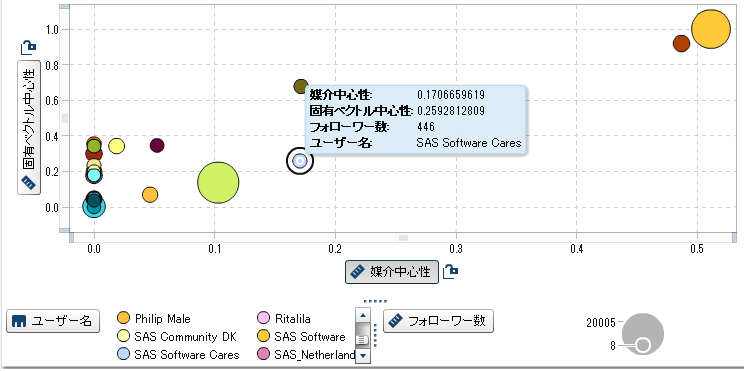
まとめ
SASのグラフ分析機能とSAS Visual Analyticsを使用してソーシャルネットワーク分析をすることで、非常に様々な洞察を得られることがご理解いただけたと思います。
