I've said it before: spreadsheets are not databases. However, many of us use spreadsheets as if they were databases, and then we struggle when the spreadsheet layout does not support database-style rigor of predictable rows, columns, and variable types -- the basic elements we need for analytics and reporting. If you're using SAS to read data from Microsoft Excel, what can you do when the data you need doesn't begin at cell A1?
By design, SAS can read data from any range of cells in your spreadsheet. In this article, I'll describe how to use the RANGE statement in PROC IMPORT to get the data you need.
With SAS 9.4 and later, SAS recommends using DBMS=XLSX for the most flexibility. It works on all operating systems without the need for additional components like the PC Files Server. Your Excel file must be in the Excel 2007-or-later format (XLSX). You do need a licence for SAS/ACCESS to PC Files. (Just learning? These DBMS=XLSX techniques also work in SAS University Edition.)
If your Excel data does not begin in cell A1 (the default start point for an import process), then you can add a RANGE= value that includes the specific cells. The easiest method is to use a Named Range in Excel to define the exact boundaries of the data.
How to add a Named Range
To define a named range in Excel, highlight the range of cells to include and simply type the new name of the range in the Name Box:
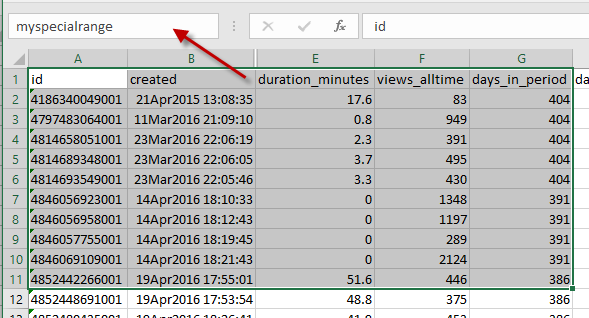
Then save the Excel file.
Then to import into SAS, specify that range name in the RANGE= option:
proc import datafile="/myprojects/myfile.xlsx" out=mydata replace; range="myspecialrange"; run; |
Using Excel notation for a cell range
What if you don't know the range ahead of time? You can use PROC IMPORT to read the entire sheet, but the result will not have the column headers and types you want. Consider a sheet like this:
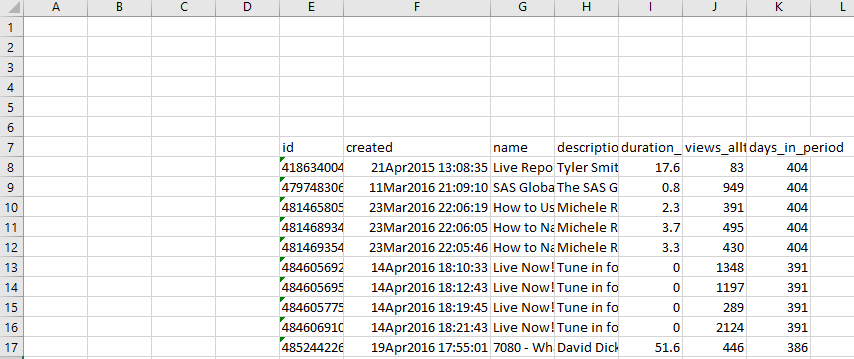
This code will read it:
proc import datafile="/myprojects/middle.xlsx" out=mid dbms=xlsx replace; run; |
But the result will contain many empty cells, and the values will be read as all character types:
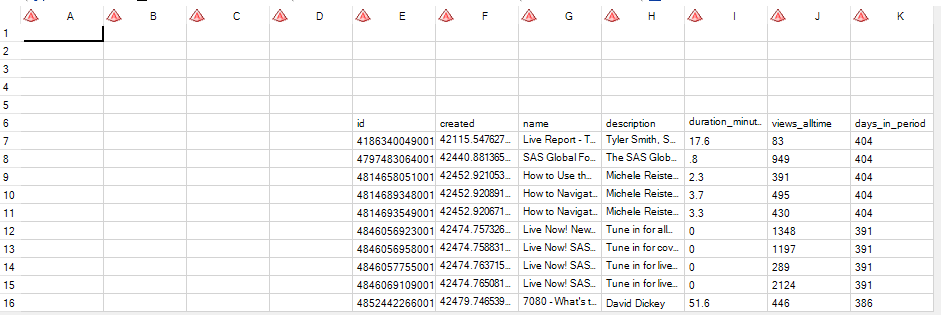
With additional coding, you can "fix" this result in another pass using DATA step. Or, if you're willing to add the RANGE option with the Excel notation for the specific cell ranges, you can read it properly in the first pass:
proc import datafile="/myprojects/middle.xlsx" out=mid dbms=xlsx replace; range="Sheet1$E7:K17" ; run; |
How to "discover" the structure of your Excel file
You can also use LIBNAME XLSX to read entire sheets from Excel, or simply as a discovery step to see what sheets the Excel file contains before you run PROC IMPORT. However, LIBNAME XLSX does not show the Excel named ranges.
On SAS for Windows systems, you can use LIBNAME EXCEL (32-bit) or LIBNAME PCFILES (64-bit) to reveal a little more information about the Excel file.
libname d pcfiles path="c:\myprojects\middle.xlsx"; proc datasets lib=d; quit; /* always clear the libname, as it locks the file */ libname d clear; |
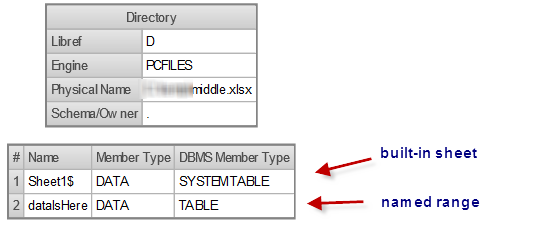
Note that DBMS=XLSX does not support some of the options we see in the legacy DBMS=XLS (which supports only old-format XLS files), such as STARTROW and NAMEROW. DBMS=XLSX does support GETNAMES (treats the first record of the sheet or range as the variable names). See the full reference for Excel file import/export in the SAS documentation.

9 Comments
Can this also be used to export to a specified range in the spreadsheet?
PROC EXPORT with DBMS=XLSX can write/overwrite a specific sheet, but I don't think it can do a named range, nor an adhoc cell range.
For creating new workbooks, ODS EXCEL provides many options for embedding Excel capabilities -- formulas, filtering, freeze rows, etc.
And if you have the SAS Add-In for Microsoft Office, you can pull in SAS content into any part of your sheet. It's magical, but not driven by pure SAS code.
You wrote "spreadsheets are not databases". This is true but they have moved closer. Excel has had for some time the feature now called "tables" and previously "lists". This imposes some rules. They can even be linked to real databases. I find them very useful. They have unique names, too.
.
SAS currently completely ignores Excel tables. Please could SAS recognise and read them.
.
Read more about Excel tables here: https://support.office.com/en-us/article/overview-of-excel-tables-7ab0bb7d-3a9e-4b56-a3c9-6c94334e492c
Peter, thanks for the comment. I'm not familiar with Excel tables, but I'll take a look and investigate what our plans are.
Thank you for posting an interesting blog on SAS . We appreciate the excel range solution. It is great to find excellent concent in the blog. Our SAS assignment experts have appreciated it.
Hi Chris, I accidentally found that you can specify only the left-top part of the range and it works too. That is instead of range="Sheet1$E7:K17" you can use range="Sheet1$E7:" provided that you want to use all the rows and columns to the right and down from E7. It saves you from scrolling all the way down and to the right to find right-bottom corner cell. I was not able to find that feature documented though.
Hi Chris, I was wondering if there is an update for the code Leonid used? I tried using this range= "Sheet1$A2:" and "Sheet1$A2:0" using SAS 9.4, but neither seem to be working for me. I receive this error: ERROR: File _IMEX_.'Line_level$A2:0'n.DATA does not exist.
(The label of sheet 1 is Line_level)
how can i limit the number of rows i read from excel? whenver i try to use something like nobs or obs dataset options i get errors.
thank you.
My current code is:
%macro readxls;
%do w = 1 %to &filecount;
%do s = 1 %to 2;
proc import datafile="/workspace/&&filename_&w"
out=sheetname_&w&s
dbms=xlsx replace;
sheet = "&&sheetname_&s";
getnames= YES;
run;
%end;*close sheet loop;
%end;*close workbook loop;
You can't tell PROC IMPORT directly how many obs to read. But if you set OPTIONS OBS=n before the statement (and reset to OBS=MAX when done), it will limit the amount of data read.