 The internet is rich with data, and much of that data seems to exist only on web pages, which -- for some crazy reason -- are designed for humans to read. When students/researchers want to apply data science techniques to analyze collect and analyze that data, they often turn to "data scraping." What is "data scraping?" I define it as using a program to fetch the contents of a web page, sift through its contents with data parsing functions, and save its information into data fields with a structure that facilitates analysis.
The internet is rich with data, and much of that data seems to exist only on web pages, which -- for some crazy reason -- are designed for humans to read. When students/researchers want to apply data science techniques to analyze collect and analyze that data, they often turn to "data scraping." What is "data scraping?" I define it as using a program to fetch the contents of a web page, sift through its contents with data parsing functions, and save its information into data fields with a structure that facilitates analysis.
Python and R users have their favorite packages that they use for scraping data from the web. New SAS users often ask whether there are similar packages available in the SAS language, perhaps not realizing that Base SAS is already well suited to this task -- no special bundles necessary.
The basic steps for data scraping are:
- Fetch the contents of the target web page
- Process the source content of the page -- usually HTML source code -- and parse/save the data fields you need.
- If necessary, repeat for subsequent pages. This applies to those web sites that serve up lots of information in paginated form, and you want to collect all available pages of data.
Let's map these steps to the SAS programming language:
| For this step | Use these features | Get the contents of the web page | PROC HTTP or FILENAME URL |
| Process/parse the web page contents | DATA step, with parsing functions such as FIND, SCAN, and regular expressions via PRXMATCH. Use SAS informats to convert text to native data types. | ||
| Repeat across subsequent pages | SAS macro language (%DO %UNTIL processing) or DATA step with CALL EXECUTE to generate multiple iterations of the fetch/parse steps. |
In the remainder of this article, I'll dive deeper into the details of each step. As an example, I'll present a real question that a SAS user asked about scraping data from the Center for Disease Control (CDC) web site.
Step 0: Find the original data source and skip the scrape
I'm writing this article at the end of 2017, and at this point in our digital evolution, web scraping seems like a quaint pastime. Yes, there are still some cases for it, which is why I'm presenting this article. But if you find information that looks like data on a web page, then there probably is a real data source behind it. And with the movement toward open data (especially in government) and data-driven APIs (in social media and commercial sites) -- there is probably a way for you to get to that data source directly.
In my example page for this post, the source page is hosted by CDC.gov, a government agency whose mandate is to share information with other public and private entities. As one expert pointed out, the CDC shares a ton of data at its dedicated data.cdc.gov site. Does this include the specific table the user wanted? Maybe -- I didn't spend a lot of time looking for it. However, even if the answer is No -- it's a simple process to ask for it. Remember that web sites are run by people, and usually these people are keen to share their information. You can save effort and achieve a more reliable result if you can get the official data source.
If you find an official data source to use instead, you might still want to automate its collection and import into SAS. Here are two articles that cover different techniques:
- Download and import a CSV file from the web
- Use REST APIs to query for and collect JSON data from web services
Web scraping is lossy, fragile process. The information on the web page does not include data types, lengths, or constraints metadata. And one tweak to the presentation of the web page can break any automated scraping process. If you have no other alternative and you're willing to accept these limitations, let's proceed to Step 1.
Step 1: Fetch the web page
In this step, we want to achieve the equivalent of the "Save As..." function from your favorite web browser. Just like your web browser, SAS can act as an HTTP client. The two most popular methods are:
- FILENAME URL, which assigns a SAS fileref to the web page content. You can then use INFILE and INPUT to read that file from a DATA step.
- PROC HTTP, which requires a few more lines of code to get and store the web page content in a single SAS procedure step.
I prefer PROC HTTP, and here's why. First, as a separate explicit step it's easier to run just once and then work with the file result over the remainder of your program. You're guaranteed to fetch the file just once. Though a bit more code, it makes it more clear about what happens under the covers. Next reason: PROC HTTP has been refined considerably in SAS 9.4 to run fast and efficient. Its many options make it a versatile tool for all types of internet interactions, so it's a good technique to learn. You'll find many more uses for it.
Here's my code for getting the web page for this example:
/* Could use this, might be slower/less robust */ * filename src url "https://wwwn.cdc.gov/nndss/conditions/search/"; /* I prefer PROC HTTP for speed and flexibility */ filename src temp; proc http method="GET" url="https://wwwn.cdc.gov/nndss/conditions/search/" out=src; run; |
Step 2: Parse the web page contents
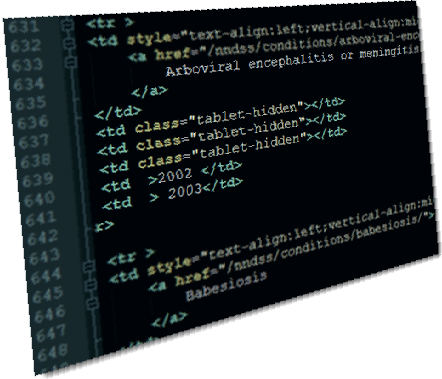
Before you can write code that parses a web page, it helps to have some idea of how the page is put together. Most web pages are HTML code, and the data that is "locked up" within them are expressed in table tags: <table>, <tr>, <td> and so on. Before writing the first line of code, open the HTML source in your favorite text editor and see what patterns you can find.
For this example from the CDC, the data we're looking for is in a table that has 6 fields. Fortunately for us, the HTML layout is very regular, which means our parsing code won't need to worry about lots of variation and special cases.
<tr >
<td style="text-align:left;vertical-align:middle;">
<a href="/nndss/conditions/chancroid/">
Chancroid
</a>
</td>
<td class="tablet-hidden"></td>
<td class="tablet-hidden"></td>
<td class="tablet-hidden"><i>Haemophilus ducreyi</i></td>
<td >1944 </td>
<td > Current</td>
</tr> |
The pattern is simple. We can find a unique "marker" for each entry by looking for the "/nndss/conditions" reference. The line following (call it offset-plus-1) has the disease name. And the lines that are offset-plus-7 and offset-plus-8 contain the date ranges that the original poster was asking for. (Does this seem sort of rough and "hacky?" Welcome to the world of web scraping.)
Knowing this, we can write code that does the following:
- Reads all of the text lines into a data set and eliminates the blank lines, so we can have a reliable offset calculation later. For this, I used a DATA step with INFILE, using the LENGTH indicator and a simple IF condition to skip the blank lines.
- Finds each occurrence of the "/nndss/conditions/" token, our cue for the start of a data row we want. I used the FIND function to locate these. If this was a more complex pattern, I would have used PRXMATCH and regular expressions.
- "Read ahead" to the +1 line to grab the disease name, then to the +8 line to get the end of the date range (which is what the original question asked for). For these read-ahead steps, I used the SET statement with the POINT= option to tell the DATA step to read the data file again, but skip ahead to the exact line (record) that contains the value we need. This trick is one way to simulate a "LEAD" or look-ahead function, which does not exist in the SAS language. (Here's an article that shows another look-ahead method with the MERGE statement.)
Here's the code that I came up with, starting with what the original poster shared:
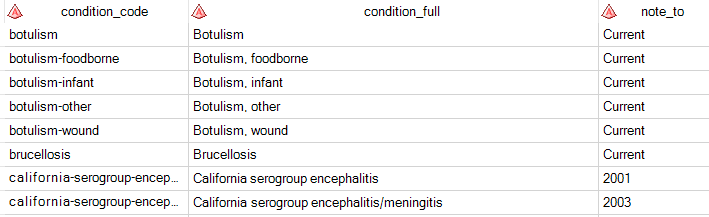
/* Read the entire file and skip the blank lines */ /* the LEN indicator tells us the length of each line */ data rep; infile src length=len lrecl=32767; input line $varying32767. len; line = strip(line); if len>0; run; /* Parse the lines and keep just condition names */ /* When a condition code is found, grab the line following (full name of condition) */ /* and the 8th line following (Notification To date) */ /* Relies on this page's exact layout and line break scheme */ data parsed (keep=condition_code condition_full note_to); length condition_code $ 40 condition_full $ 60 note_to $ 20; set rep; if find(line,"/nndss/conditions/") then do; condition_code=scan(line,4,'/'); pickup= _n_+1 ; pickup2 = _n_+8; /* "read ahead" one line */ set rep (rename=(line=condition_full)) point=pickup; condition_full = strip(condition_full); /* "read ahead" 8 lines */ set rep (rename=(line=note_to)) point=pickup2; /* use SCAN to get just the value we want */ note_to = strip(scan(note_to,2,'<>')); /* write this record */ output; end; run; |
The result still needs some cleanup -- there are a few errant data lines in the data set. However, it should be simple to filter out the records that don't make sense with some additional conditions. I left this as a to-do exercise to the original poster. Here's a sample of the result:
Step 3: Loop and repeat, if necessary
For this example with the CDC data, we're done. All of the data that we need appears on a single page. However, many web sites use a pagination scheme to break the data across multiple pages. This helps the page load faster in the browser, but it's less convenient for greedy scraping applications that want all of the data at once. For web sites that paginate, we need to repeat the process to fetch and parse each page that we need.
Web sites often use URL parameters such as "page=" to indicate which page of results to serve up. Once you know the URL parameter that controls this offset, you can create a SAS macro program that iterates through all of the pages that you want to collect. There are many ways to accomplish this, but I'll share just one here -- and I'll use a special page from the SAS Support Communities (communities.sas.com) as a test.
Aside from the macro looping logic, my code uses two tricks that might be new to some readers.
- The DLCREATEDIR option along with the LIBNAME statement allows me to create a special holding folder on-the-fly, without the need for operating system commands
- The INFILE statement uses a wildcard notation ("*.html") to process all of the HTML files that I collect in that folder. It does not need to know the specific filenames nor how many there are. This allows a single DATA step to read all of the HTML files in one pass.
/* Create a temp folder to hold the HTML files */ options dlcreatedir; %let htmldir = %sysfunc(getoption(WORK))/html; libname html "&htmldir."; libname html clear; /* collect the first few pages of results of this site */ %macro getPages(num=); %do i = 1 %to &num.; %let url = https://communities.sas.com/t5/custom/page/page-id/activity-hub?page=&i.; filename dest "&htmldir./page&i..html"; proc http method="GET" url= "&url." out=dest; run; %end; %mend; /* How many pages to collect */ %getPages(num=3); /* Use the wildcard feature of INFILE to read all */ /* matching HTML files in a single step */ data results; infile "&htmldir./*.html" length=len lrecl=32767; input line $varying32767. len ; line = strip(line); if len>0; run; |
The result of this program is one long data set that contains the results from all of the pages -- that is, all of lines of HTML code from all of the web pages. You can then use a single DATA step to post-process and parse out the data fields that you want to keep. Like magic, right?
Where to learn more
Each year there are one or two "web scraping" case studies presented at SAS Global Forum. You can find them easily by searching on the keyword "scrape" from the SAS Support site or from lexjansen.com. Here are some that I found interesting:
- A way to fetch user reviews from iTunes using SAS -- a good example of scraping "proprietary" data from a provider who is not likely to make this available easily in another way.
- Using SAS to Help Fight Crime: Scraping and Reporting Inmate Data -- this example may be a bit dated, but you can see the extensive use of PRX* functions to pull data from the web page.


14 Comments
I remember way back in the USENET days in the mid-90s, the NFL would post text data files on a very elementary World Wide Web for each game. The files would contain the game scoring summary and team stats, which were perfect for BASE SAS parsing -- especially when you're running a fantasy football league. This was before Yahoo! Sports or ESPN running online fantasy leagues, so all scoring had to be done by hand... except for our league. We would gather all 16 text files -- one file for each game, and combine them with our fantasy team lineups and let SAS do all the scoring in a matter of seconds.
i am trying to follow your step but encountering the "connection being refused" issue.
May i know if there are any solutions?
Thanks.
ERROR: Error connecting to 198.246.102.39:443. (The connection was refused.)
ERROR: Unable to establish connection to wwwn.cdc.gov.
ERROR: Unable to connect to Web server.
I suspect that you're trying this from a place that has a proxy/firewall. If so, you'll need to specify the PROXYHOST settings -- your internet gateway -- on the PROC HTTP statement. This is probably already configured for your browser, but programs like SAS will need the value set in the code.
Hi Chris,
if i try your code, it runs fine and shows the expected result.
proc http method="GET" url="https://wwwn.cdc.gov/nndss/conditions/search/" out=src; run;
However if i change the link to
proc http method="GET"
url='https://data.chhs.ca.gov/dataset/licensed-healthcare-facility-listing'
out=src ;
run;
I get "ERROR: Web server could not complete requested operation." , could you please help
I can't explain the error, but I think you probably want to download a specific listing of Licensed Facilities, right? If so, right-click on the DOWNLOAD button and select Copy Link Address, then paste that into your program. It's a very long link, but here's what I tried.
PROC IMPORT did not do a clean job, so you'll probably want to modify and write your own DATA step. But I did get nearly 7000 records.
Pingback: 데이터 분석 프로젝트를 성공적으로 시작하기 위한 체크 리스트 10가지 - SAS Korea
Can I use proc http to read a *.html file into a folder?
Thank you
Sorry Chris
What I actually have is a large number of html files that aren't posted on the web due to becoming obsolete. But, I have data from the time period when they weren't obsolete. I need the information that is stored in roughly 1,200 files. Can I use proc http to read the downloaded files or do I need to create my own data step code?
Thank you
Ah, right. Yes, you can use PROC HTTP to download these and save each in the OUT=. Then you can use DATA step to read/process these.
Yes, if the HTML is static and not dependent on you being logged in via a browser, depending on cookies, etc. Simply save the file as the OUT= response in PROC HTTP.
Hi Chris.
I like the example you show with %getPages macro that loops to retrieve the pages you want. What if I don't know how many pages I need to retrieve or my max number of pages grows over time? Do you have any suggestion for how to loop until there are no more pages to read?
You could check the macro variable that PROC HTTP updates to make sure your URL is working. As you iterate through and find a page that returns anything but an HTTP 200 code, maybe that's an indicator you're done.
Or, look at a page that results from going beyond the page boundary, and add code in your program to detect that. It's a messy business!
Hi , Chris . Is there a way to scrape websites with a load more button? For example a website shows 20 articles at a time , in order to view more articles the user is required to click on the load more button . Is there any way to ignore this load more button?
Mohammad,
Maybe. The "load more" function on many websites might work by issuing a new URL with pagination params (ex: &page=2). If that's the case, you would repeatedly use PROC HTTP to iterate through the pages you need.
Another method often used is a javascript call to asynchronously fetch more records and display them on the page. In this case, you would have to look at the page source or script to see what's called and emulate that in PROC HTTP. Another trick is to watch the network traffic in your browser console, and see what HTTP calls are being used to fetch more records.