The project that I'm currently working on requires several input data tables, and those tables must have a specific schema. That is, each input table must contain columns of a specific name, type, and length in order for the rest of the system to function correctly. The schema requirements aren't too fancy; there are no specs for keys, indexes, or constraints. It's simply "your data sets need columns that look like this".
Even though the schema is "published", the data tables themselves will be prepared by humans using Who Knows What Processes. Therefore, we must adopt a "trust but verify" approach before accepting the data and turning the crank on what could be a long-running analysis.
I could "eyeball" the differences by capturing the data column attributes from each table and comparing them with what I know I need, but that approach doesn't scale well.
I wrote a simple SAS macro that I use to create a report that shows whether the input data passes a simple schema "sniff test". It compares a "candidate" table against a table that has a known "good" column layout, and reports on the substantive differences.
DOWNLOAD: %check_reference_data from here.
The output of the macro is another data set that contains one record per column-pair, showing a list of potential problems with the input data, ranked by severity. The severity assignments are a bit arbitrary, but effective enough for my project:
- "SEV 1" is assigned if a required column is missing, or is present but has a different type (numeric vs. character).
- "SEV-2" is assigned if a required column has a greater-than-expected length, as it might lead to truncation of data values downstream.
- "SEV-3" is assigned if the column has a different SAS format, as it could indicate possible misinterpretation (a DATE format vs. DATETIME, for example).
- And "SEV-4" is more of an "FYI" when the input data contains additional columns that aren't required.
Sample uses:
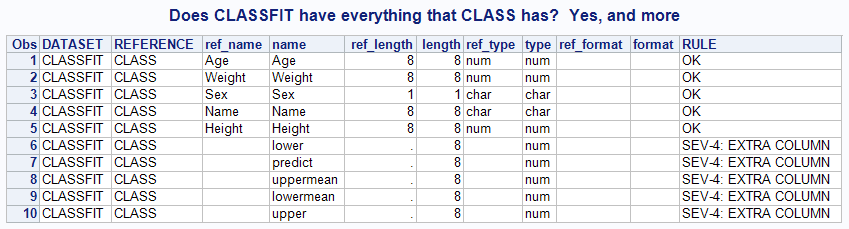
%check_reference_data(SASHELP,CLASS,SASHELP,CLASSFIT,WORK.CHECK); title "Does CLASSFIT have everything that CLASS has? Yes, and more"; proc print data=work.check; run; |
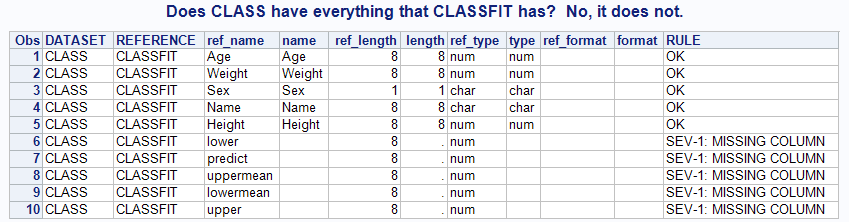
%check_reference_data(SASHELP,CLASSFIT,SASHELP,CLASS,WORK.CHECK); title "Does CLASS have everything that CLASSFIT has? No, it does not."; proc print data=work.check; run; |
If you examine the code behind the macro, you might notice that it creates a temporary view of the input data. Why? During work on my project, I noticed that some of the supplied input data differed from the schema only by one or two column names. Sometimes it's easier to "fix" that data on the way in than to send it back to the customer to regenerate. The temp view allows me to apply simple data set options like this:
%check_reference_data(REF,CLASS,CUST,CLASS(rename=(GENDER=SEX)),WORK.CHECK); title "Fixed for customer-provided data that was SEX-less"; proc print data=work.check; run; |
And by the way, for this check to work I don't need to keep a complete copy of "good" data lying around. I can create an empty table with the desired schema "on the fly" like so, and then use it as the reference table in my macro:
/* create reference table attributes */ /* using SQL, but DATA step works too */ proc sql; create table work.PATIENT ( SEX VARCHAR(1) FORMAT=$1., YOB NUMERIC(8) FORMAT=4., ZIP_CODE VARCHAR(5), PATIENT_ID VARCHAR(15) ); quit; |
This macro provides a simple, "good-enough" approach for verifying the input data. It provides instant feedback as to whether the data can be used, and gives us confidence that we can proceed to the next step of the analysis.

1 Comment
Nice. I changed
where libname="&ref_lib" and memname="&ref_table"
to
where libname="%sysfunc(upcase(&ref_lib))" and memname="%sysfunc(upcase(&ref_table))"
so that I don't have to remember to put the library and dataset names in upper case.