Most SAS procedures support the BY statement, which allows you to create a report or analysis for each distinct value of a variable in your data set. The syntax is simple, and SAS procedures are usually tuned to do a good job of processing the data efficiently.
However, the BY statement approach has some limitations:
- If input data is a SAS data set, you must make sure the data is first sorted by the BY variable. (For database data, you can get away without doing that, as SAS pushes the ORDER BY instruction to the database.)
- It's difficult to interleave BY output from multiple steps within your program.
For example, suppose you want to show a PROC PRINT output followed by a PROC SGPLOT chart for each value of a variable in a data set. Using the BY statement in each of these two steps would produce a series of PROC PRINT results, followed by a series of PROC SGPLOT results. (Oh, and don't forget that you can use SGPLOT and SGPANEL for classification plots without explicit BY processing.)
There is a SAS programming pattern that allows you to extend the concept of BY processing to larger segments of your SAS program. In pseudo-code, this allows you to implement program logic such as:
for each value BY_VAL of VAR in DATASET
do;
PROC step1 (for VAR=BY_VAL)
run;
PROC step2 (for VAR=BY_VAL)
run;
/* other PROC or DATA steps as needed */
/* each for the case of VAR=BY_VAL */
end;
In real SAS code, the programming pattern uses the SAS macro language. (Of course! Because with SAS macro, there is almost nothing that you can't do.)
Let's take a simple code example through this transformation. Let's combine a PROC FREQ step with a PROC SGPLOT step. Here's the example without BY processing or classification. The results show a report and plot for ALL values of Type within SASHELP.CARS. It's okay, but it doesn't provide much insight into the different classifications of car Type (Hybrid, Truck, Sedan, and so on).
title "Type by Origin in SASHELP.CARS"; proc freq data=sashelp.cars; table origin*type /nocum nopercent list; run; proc sgplot data=sashelp.cars; histogram mpg_city; density mpg_city / type=kernel; run; |
Step 1. Get your program working for one value using WHERE=
Before introducing any macro statements into the mix, it's a good idea to get your non-macro logic correct. Things are much easier to debug and troubleshoot before you add any macro processing. This modification shows what the program would look like with one known value of Type:
title "HYBRID by Origin in SASHELP.CARS"; proc freq data=sashelp.cars (where=(type="Hybrid")); table origin*type /nocum nopercent list; run; proc sgplot data=sashelp.cars(where=(type="Hybrid")); histogram mpg_city; density mpg_city / type=kernel; run; |
Example output:
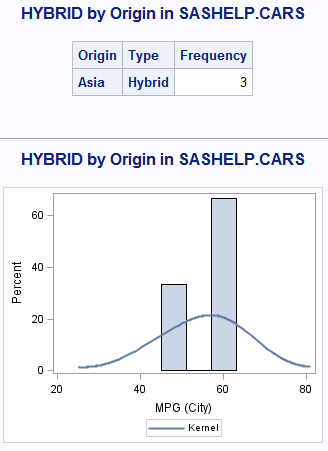
Step 2. Count the distinct values and create macro variables for each
Once you're happy with the output for the single distinct value in you created in Step 1, it's time to gather the information you need to repeat that step for each distinct value in the data. Before you can achieve this with a SAS macro loop, you're going to need two bits of information: how many distinct values are there (for the loop index), and what ARE those distinct values (for each iteration). Here's the pattern of code to figure this out:
/* create macro vars with values and a total count of distinct values */ proc sql noprint; select strip(put(count(distinct VAR),15.)) into :varCount from DATASET; select distinct VAR into :varVal1- :varVal&varCount from DATASET; quit; |
This pattern uses the SELECT INTO feature of PROC SQL, which allows you to populate SAS macro variables with the output of any query operation. I use this code pattern often, so I created an editor abbreviation to make it easy to insert into any SAS program as I work. Then I can simply replace the key parts of the statements with the values I need from the program, such as for this example:
proc sql noprint; select strip(put(count(distinct TYPE),15.)) into :varCount from SASHELP.CARS; select distinct TYPE into :varVal1- :varVal&varCount from SASHELP.CARS; quit; |
I replaced "VAR" with my class variable, "TYPE". And I replaced "DATASET" with "SASHELP.CARS". That's it.
UPDATE 26Mar2012: With new features in SAS 9.3, the above code pattern becomes even simpler. See how to improve on this SAS programming pattern.
When I run just these statements in SAS Enterprise Guide, I can use my SAS Macro Variable Viewer to see how my macro variables were initialized.
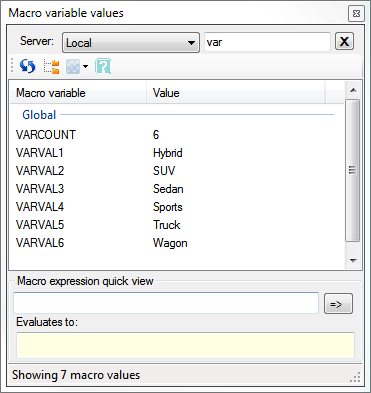
Step 3. Wrap your program logic in a macro function, and add a %DO loop
Now it's time to wrap the program segment in a %MACRO statement, and then add a %DO loop so that the segment is processed varCount times. (That's going to be 6 times, in our example.)
%macro ReportOnEachType; %do index = 1 %to &varCount; title "HYBRID by Origin in SASHELP.CARS"; proc freq data=sashelp.cars (where=(type="Hybrid")); table origin*type /nocum nopercent list; run; proc sgplot data=sashelp.cars(where=(type="Hybrid")); histogram mpg_city; density mpg_city / type=kernel; run; %end; %mend; %ReportOnEachType; |
If this is your first time creating a SAS macro program, I suggest spending the few minutes to learn from Stacey in this tutorial, 3 Steps to Build a SAS Macro Program:
Step 4. Fix your WHERE= processing to reference the macro variables
Now we've got the correct number of steps running, but the output is the same for each step -- not very interesting! We need to customize the program statements to use each distinct value of Type.
%macro ReportOnEachType; %do index = 1 %to &varCount; title "&&varVal&index. by Origin in SASHELP.CARS"; proc freq data=sashelp.cars (where=(type="&&varVal&index.")); table origin*type /nocum nopercent list; run; proc sgplot data=sashelp.cars(where=(type="&&varVal&index.")); histogram mpg_city; density mpg_city / type=kernel; run; %end; %mend; %ReportOnEachType; |
Note how we need to reference our macro variable that contains the distinct value: "&&varVal&index." You need a "double &" to dereference (fancy word for reference the reference) the correct macro variable for the current index value.
Step 5. (OPTIONAL) Keep tinkering towards perfection
Now you've "rolled your own" BY group processing, but don't stop there! With a few more tweaks we can make it even better:
/* create macro vars with values and a total count of distinct values */ proc sql noprint; select strip(put(count(distinct TYPE),15.)) into :varCount from SASHELP.CARS; select distinct TYPE into :varVal1- :varVal&varCount from SASHELP.CARS; quit; %macro ReportOnEachType; title; ods noproctitle; ods layout start columns=2; %do index = 1 %to &varCount; ods region; proc freq data=sashelp.cars (where=(type="&&varVal&index.")); SYSECHO "Processing freq for &&varVal&index., &index. of &varCount."; table origin*type /nocum nopercent list; run; ods region; ods graphics / width=500 height=400 imagename="plot&&varVal&index."; proc sgplot data=sashelp.cars(where=(type="&&varVal&index.")); SYSECHO "Processing plot for &&varVal&index., &index. of &varCount."; histogram mpg_city; density mpg_city / type=kernel; xaxis label="MPG (City) for &&varVal&index."; run; %end; ods layout end; %mend; %ReportOnEachType; |
I added ODS LAYOUT statements (officially experimental, but works well in HTML) to generate two-column output, with tables and charts side-by-side. I added SYSECHO statements so that I can track progress of the program as it runs in SAS Enterprise Guide. If you've got lots of data with lots of distinct values, it can take a while. You might appreciate the running status message. And I added some ODS GRAPHICS options to control the name of the output image files, just to make my results easier to track on the file system.
Here's an example of my final report. Can you take it even further? I'll bet that you can!
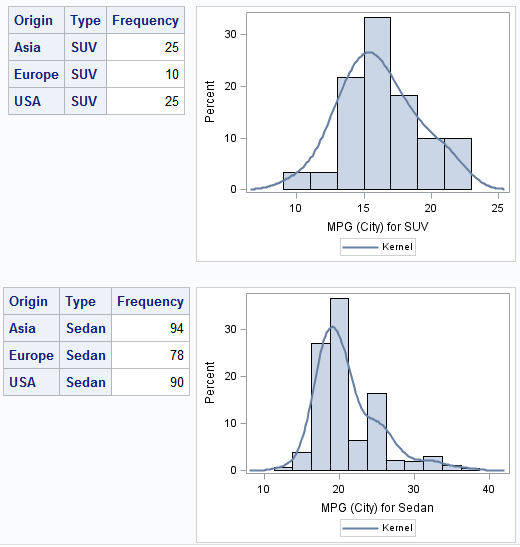

{kind=link}
14 Comments
While this is a great article on BY processing using macros, SAS 9.2 SGPLOT does support BY processing. Just make sure your data is sorted by the BY variable.
I stand corrected! I will correct the original text in the article. Thanks Sanjay!
Re:
select strip(put(count(distinct VAR),15.)) into :varCount from DATASET; select distinct VAR into :varVal1- :varVal&varCount from DATASET;Starting in 9.3, you can do two new things:
This is better than the first method, because you may have noticed that &varCount used to have trailing blanks anyway, due to the STRIP() result being padded out to a fixed-width character before the INTO assignment. However, you don't need it:
This replaces both SELECTs with the new open-ended INTO list, which sets only as many varValNs as it needs to, plus the &SQLOBS macro variable to give you the final count.
Thank you Gordon! These are cool improvements in 9.3, and they make this very common coding pattern even more efficient.
This is a well-written description of how to create a macro that cutomizes the behavior of a SAS program. The various steps are all well explained and clear.
From an efficiency point of view, the advantage of the BY-group analysis is that it passes through the data one time for each procedure. The macro approach shown here passes through the data k times for each procedure, where k is the number of BY-group categories. Therefore, for large data, the BY-group analysis is preferred.
If you want to generate a report that orders the tables and graphs by the BY groups, you can write the output to an ODS document, and then reorder the output using the REPLAY statment in PROC DOCUMENT. This approach is shown in SAS Sample 36505, which also includes a version of your analysis (but without your helpful exposition). Another SAS Sample contains similar information.
So my question is: can you adapt your macro to give us the best of both worlds? Use the BY-group analysis to efficiently get all of the tables and graphs into a document. (No macro is required for this step.) Then write a macro that fills out the body of a PROC DOCUMENT call to replay the output in the order that you desire?
Rick, thanks for the comments and for the links to samples.
The question: can I write a macro to leverage the output of BY processing to a carefully arranged output using PROC DOCUMENT. Yes, I'll bet that I can. But that's a topic for another post; if someone else beats me to it, I'll be grateful.
One more comment about BY group efficiency - it's true that BY groups process the data just once, where this approach makes multiple passes. But imagine if you had SAS Grid Computing environment. With a few extra statements, you could easily spread the processing out to many different nodes, each processing one BY value. It would churn more I/O and compute cycles, but the clock time might be reduced. That tradeoff might be acceptable, depending on your business goals.
If the dataset has an index on the desired BY variable, then the engine with the WHERE= will use the index to pluck only the rows it needs. This works best, of course, when the dataset is sorted on the BY variable, but should help even when it isn't.
Well Done! Nicely written and easy to understand.
Pingback: Improving on a SAS programming pattern - The SAS Dummy
Rather than counting the number of unique vars first and using the resulting macro variable to set the upper limit for the INTO :, use the following syntax, saves a step:
proc sql; select distinct var into :varVal1 - :varVal&sysmaxlong from dataset ; %let varCount = &sqlobs; quit;Harry, good tip! When using SAS 9.3, this approach is even a bit more intuitive with the open-ended INTO range.
Pingback: Reorder the output from a BY-group analysis in SAS - The DO Loop
You saved my life thank you
All in a days work. Thanks for the feedback!