Matchcodes spielen bei der Identifizierung von Dubletten eine zentrale Rolle. Um die Dubletten anhand von Matchcodes zu finden, müssen die Daten meistens erst noch aufbereitet werden. Stehen beispielsweise Anrede und Vor-/Nachname oder Straße und Hausnummer im selben Feld, müssen diese separiert werden, dadurch können bessere Match-Ergebnisse erzielt werden.
Parsing ist hierfür die Methode der Wahl, wie das nachfolgende Beispiel zeigt:
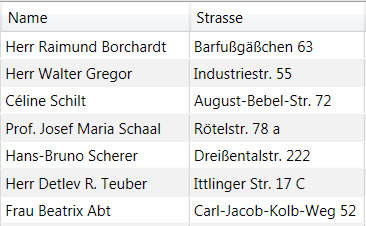
Daten vor Parsing
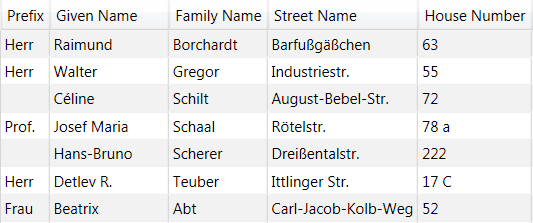
Daten nach Parsing
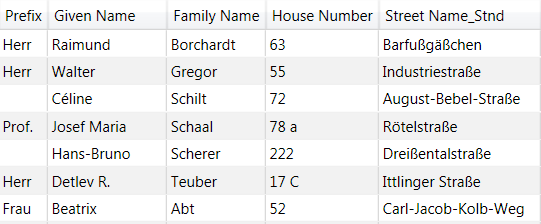
Nach dem Parsing kommt meist die Standardisierung, diese wird eingesetzt, um z. B. Telefonnummern einheitlich zu schreiben. Ebenso kann die Straße in ein einheitliches Format gebracht werden, auch dies ist wichtig für die Genauigkeit der Matchcode-Erstellung.
Nach Standardisierung des Feldes Straße haben die Inhalte nun eine einheitliche Schreibweise, wodurch später der Vergleich der Datensätze untereinander erleichtert wird.
Im nächsten Schritt generieren wir für die relevanten Felder Matchcodes mit unterschiedlicher Sensitivität (85, 90 und 95). Das Arbeiten mit verschiedenen Sensitivitäten hilft, die richtige Match-Strategie zu finden. Der Matchcode wird für folgende Felder generiert: Vorname, Nachname, Straße, Hausnummer, Ort und PLZ. Dies dient dazu, die einzelnen Matchcodes eines Datensatzes mit den anderen Datensätzen zu vergleichen.
Der Vergleich der einzelnen Datensätze untereinander wird mittels Clustering gemacht. In den Eigenschaften des Clustering wird eingestellt, welche Matchcodes für die Übereinstimmung herangezogen werden. Stimmen die Matchcodes mit denen eines anderen Datensatzes überein, wird die gleiche Cluster-ID (CL_ID) vergeben, anhand derer die Dubletten sichtbar werden.
Nachfolgender Screenshot zeigt das Ergebnis nach Clustering:
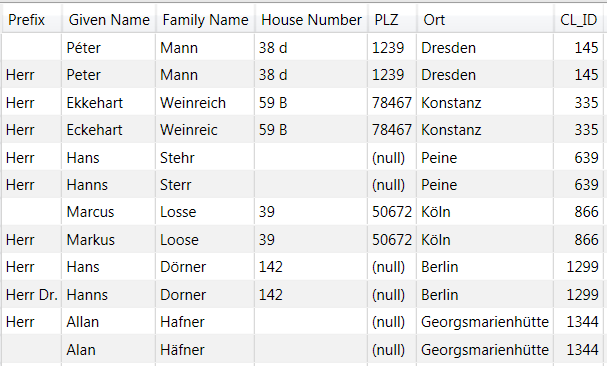
Im letzten Schritt geht es darum, vom Tool einen Vorschlag zu bekommen, welcher Datensatz von den gefundenen Dubletten sich als „Survive Record“ eignet. Nachfolgender Screenshot zeigt, dass der Datensatz, in dem der Name vollständig ist, als „Survive Record“ gekennzeichnet wird (survive = true).
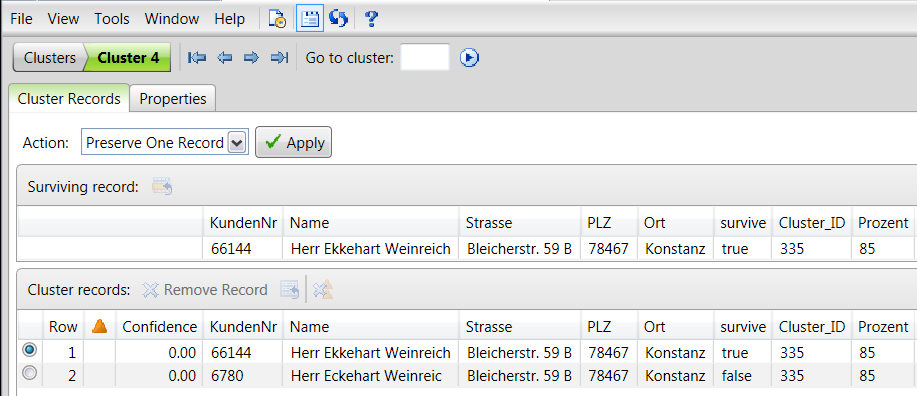
Es empfiehlt sich nicht, das System alleine festlegen zu lassen, welcher Datensatz beibehalten werden soll, und was Dubletten sind. Diese Entscheidung sollten Mitarbeiter des Fachbereichs treffen. Per Editor kann sich jemand aus dem Fachbereich die Cluster anschauen und entscheiden, welcher der beste Datensatz ist. Dies alles passiert unabhängig von den Vorsystemen, sodass Dubletten nur gekennzeichnet, aber nicht gelöscht werden.
Dieses Beispiel befasste sich mit Geschäftspartnerdaten, ist aber auch auf andere Datenbereiche anwendbar.
Mit dem aktuellen Data Loader für Hadoop (DL) kann die Suche nach Dubletten in einem Hadoop-Cluster erfolgen, so wie hier beschrieben. Der DL nutzt als Laufzeitumgebung Spark. Da Spark mittlerweile ein Top-Level-Projekt im Hadoop-Umfeld ist, ist die Nutzung eine Option.