Die deutschen Versicherer haben sich zusätzlich zum Bundesdatenschutzgesetz, das die Datenverarbeitung und die Speicherung von personenbezogenen Daten festlegt, zur Einhaltung des brancheneigenen Code of Conduct verpflichtet. Kundendaten aus verschiedenen Versicherungssparten werden aber aus wirtschaftlichen Gründen, um Cross-Selling-Potenziale zu identifizieren oder Risikoklassen zu berechnen, häufig zu Auswerte- und Analysezwecken in einer Datenbank gespeichert oder zusammengeführt.
Nur freigegebene Daten darf man dabei in lesbarer Form, andere Informationen nur anonymisiert oder pseudonymisiert zur Verfügung stellen. In der Regel kann man Daten einer kompletten Spalte entweder verschlüsselt oder unverschlüsselt in einer Datenbanktabelle speichern. Möchte man aber zum Beispiel Datensätze von Kunden zur Berechnung von Risikoklassen weiterverwenden, so müssen in diesen Datensätzen personenbezogene Informationen pseudonymisiert werden.
Um Daten nun nicht aufsplitten oder mehrfach replizieren zu müssen, wäre es einfacher, wenn man alle Daten in einer Datenbanktabelle entsprechend den gesetzlichen Vorgaben unterschiedlich verschlüsseln könnte. Wie kann man auf einfache Art und Weise Anwendern Daten zur Verfügung stellen, bei denen nur bestimmte Werte einer Spalte entweder lesbar, anonymisiert oder pseudonymisiert ausgegeben werden sollen?
Folgende Tabelle enthält beispielhaft personenbezogene Daten eines Versicherungsnehmers (Vergrößerte Ansicht mit klick aufs Bild).
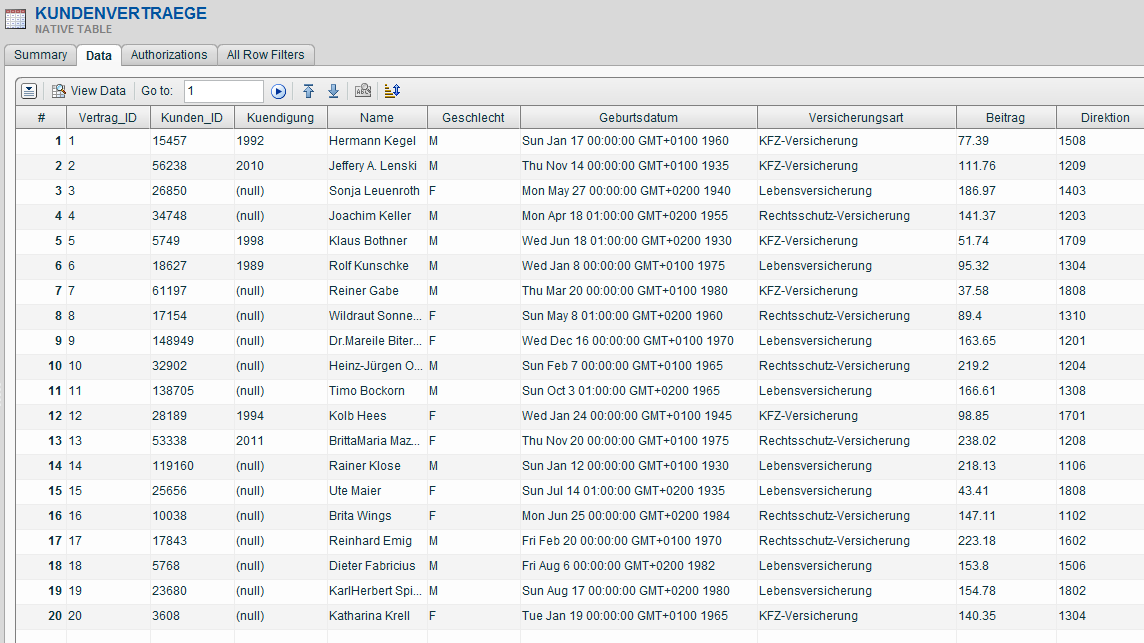
Lediglich Vertragsdaten für Kfz-Versicherungen, deren Vertrag nicht gekündigt oder deren Kündigung nicht älter als zehn Jahre ist, sollen den Mitarbeitern der Kfz-Sparte lesbar zur Verfügung gestellt werden. Die Namen der Versicherungsnehmer anderer Vertragsarten sollen anonymisiert oder pseudonymisiert werden, wenn bei Verträgen die Kündigung länger als 10 Jahre zurückliegt, egal welcher Versicherungsart sie angehören.
Mit einer CASE-WHEN-Anweisung und den verschiedenen Verfahren zur Verschlüsselung ist es mit dem SAS Data Federation Server möglich, Werte einer Spalte – in diesem Beispiel die Spalte „Name” – in Abhängigkeit der Werte in den Spalten „Kuendigung” und „Versicherungsart” entweder zu pseudonymisieren (d. h. die ursprünglichen Werte sind nicht wieder herzustellen), zu anonymisieren (d. h. mit dem entsprechenden Schlüssel sind die ursprünglichen Werte wieder herstellbar) oder den Originalwert auszugeben.
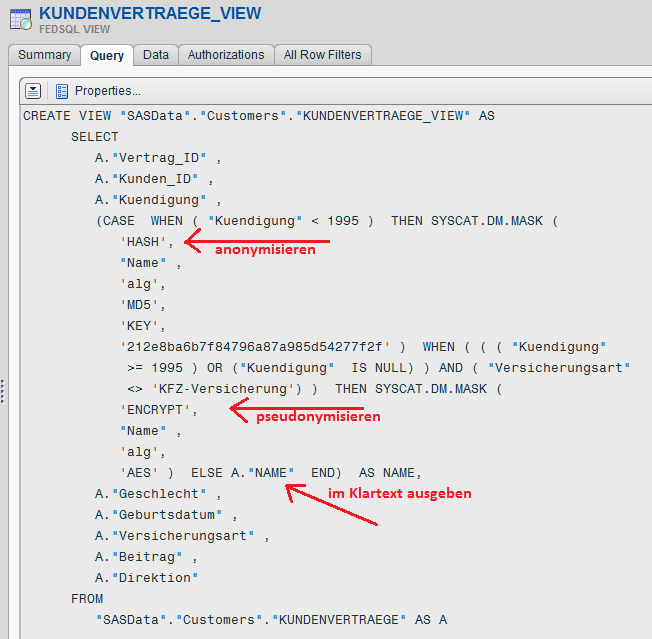
Das Ergebnis der obigen Abfrage zeigt, dass der Name des Versicherungsnehmers in Abhängigkeit vom Zeitpunkt einer Kündigung oder der Versicherungsart pseudonymisiert (roter Rahmen), im Klartext (blauer Rahmen) oder anonymisiert ausgegeben wurde (siehe folgende Abbildung - vergrößerte Ansicht mit Klick aufs Bild).
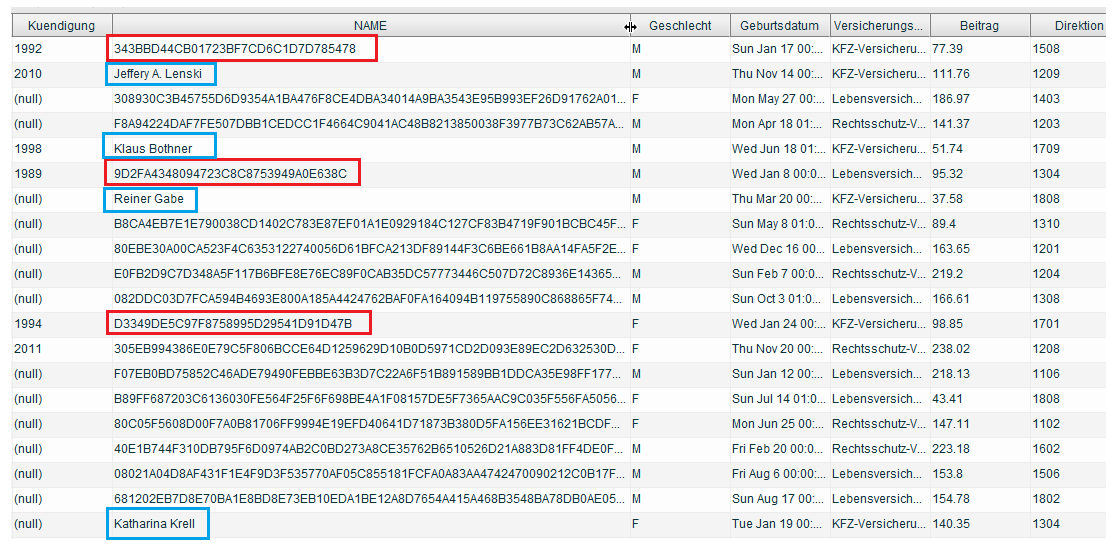
Dieses Vorgehen macht es der IT einfach, personenbezogene Daten, entsprechend den gesetzlichen Vorgaben und den brancheneigenen Verpflichtungen, jedem Anwender entsprechend seiner Aufgabe und Rolle zur Verfügung zu stellen.






