Anwender in Risiko- oder Controlling-Abteilungen haben – in aller Regel – keine tiefer gehenden Kenntnisse in Abfragen von Datenbanken. Excel ist die Welt, in der sie zu Hause sind und sich wohlfühlen. Komplexe Datenbankfragen, wenn etwa Zusammenhänge zwischen Datenbanktabellen identifiziert werden sollen, führt die IT-Abteilung durch und stellt die Ergebnisse dem Fachbereich wieder als Exceldatei zur Verfügung. Dieses Vorgehen führt dazu, dass Fachbereiche oft lange auf ihre dringend benötigten Daten zur Auswertung und Analyse warten müssen. Bei Fehlern oder Erweiterungen muss dieser Prozess gleich mehrfach wiederholt werden. Mit einfachen Mitteln, mit denen Fachbereiche solche Aufgaben eigenständig durchführen können, ist es aber möglich, Entwicklungszyklen von Auswertungen wesentlich zu beschleunigen.
Nicht immer sind Datenbestände so sauber strukturiert und vor allem dokumentiert, dass Zusammenhänge, sogenannte Primär- und Fremdschlüssel-Verknüpfungen, zwischen den Datenbanktabellen bekannt sind und genutzt werden können. Um diese Zusammenhänge ohne Programmier- oder SQL-Kenntnisse zu erkennen, kann der Fachbereich sogenannte Profiling-Funktionalitäten im Data Management Studio des SAS Datenqualitätswerkzeugs nutzen.
Über eine einfache grafische Benutzeroberfläche können sich Anwender aus den Fachbereichen erste Analysen in wenigen Schritten selbst zusammenklicken. Abhängigkeiten zwischen den Tabellen lassen sich somit schnell und unkompliziert über vorher ausgewählte Tabellenspalten ermitteln.
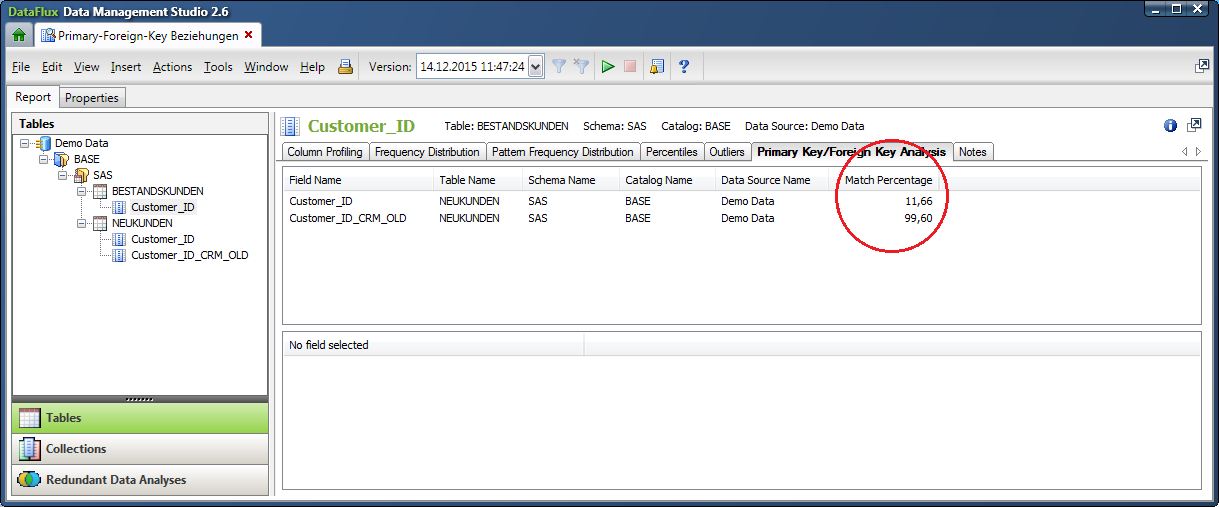
Diese Analyse ermittelt den prozentualen Anteil der Werte einer Schlüsselvariablen aus der Ausgangstabelle (zum Beispiel Customer_ID in Tabelle Bestandskunden) in der oder den gewählten Variablen der Zieltabellen (Customer_ID beziehungsweise Customer_ID_CRM_OLD), in denen eine Abhängigkeit vermutet wird. So erhält man sehr einfach und schnell einen ersten Überblick über Zusammenhänge zwischen Tabellen. Abbildung 1 zeigt, dass die Customer_ID aus der Bestandskundentabelle wesentlich häufiger in der alten, eigentlich nicht mehr zu benutzenden Variablen Customer_ID_CRM_OLD vorkommt (99,60 Prozent) als in der eigentlich vermuteten Variablen Customer_ID (11,66 Prozent) aus der Neukundentabelle.
Häufig steht der Fachbereich allerdings vor schwierigeren Herausforderungen. Dies kann passieren, wenn zum Beispiel Werte der Schlüsselvariablen nicht 1:1 in den abhängigen Tabellen vorkommen, sondern zusätzlich in voran- oder hintangestellten Zeichenketten eingeschlossen sind (XXXX_1234567890_XXXX). Des Weiteren gibt es häufig Variablen in Tabellen, deren Bezeichnungen (C_001 bis C200) keinen Aufschluss über Sinn und Zweck der Variablen geben. Schlüsselvariablen zu identifizieren, wird dadurch massiv erschwert.
Damit der Fachbereich auch diese Hürde sicher meistern kann, steht ihm eine Funktion im SAS Data Management Studio zur Verfügung, die eigentlich dafür gedacht ist, Dubletten zu identifizieren. Der große Vorteil dieser Funktion liegt dabei in der „unscharfen Suche” (zum Beispiel: Finde „1234567890” in XXXX_1234567890_XXXX, siehe Abbildung 2), anstatt einer exakten Suche, wie im ersten Beispiel beschrieben.
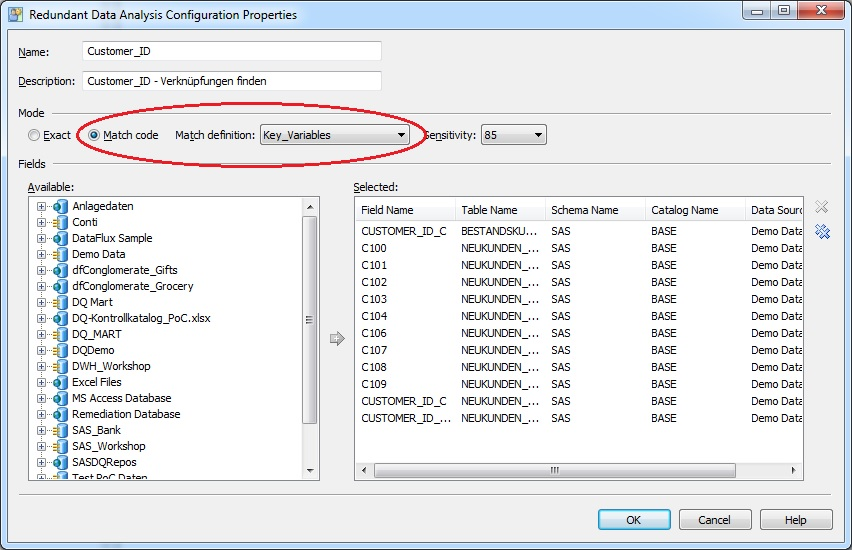
Mit einem exaktem Vergleich (Abbildung 3 und 4) würde man nicht alle möglichen Kombinationen finden und damit eventuell versteckte Schlüsselbeziehungen (in der Variablen C109) nicht identifizieren.
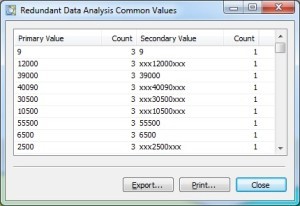
 Mit der unscharfen Suche ist es möglich, Beziehungen zu finden, bei denen die Werte nicht zu 100 Prozent mit der Ausgangstabelle übereinstimmen. Die Farben der Ampelfunktion in der Ergebnisansicht (Abbildung 4 und 5) entsprechen allerdings dem ursprünglichen Sinn der Funktion „Suche nach Dubletten”; bei dieser speziellen Verwendung der Funktion bedeutet grün, dass „keine”, gelb, dass „wenige” und rot, dass „sehr viele” Abhängigkeiten gefunden wurden.
Mit der unscharfen Suche ist es möglich, Beziehungen zu finden, bei denen die Werte nicht zu 100 Prozent mit der Ausgangstabelle übereinstimmen. Die Farben der Ampelfunktion in der Ergebnisansicht (Abbildung 4 und 5) entsprechen allerdings dem ursprünglichen Sinn der Funktion „Suche nach Dubletten”; bei dieser speziellen Verwendung der Funktion bedeutet grün, dass „keine”, gelb, dass „wenige” und rot, dass „sehr viele” Abhängigkeiten gefunden wurden.

Auch ohne IT- oder SQL-Kenntnisse kann der Fachbereich damit schnell und einfach Zusammenhänge zwischen Daten untersuchen und Abhängigkeiten zwischen Tabellen finden, um diese für weitergehende Analysen zusammenzuführen. Auch wenn der Fachbereich selbst nicht in der Lage ist, mit SQL-Codes oder den entsprechenden Werkzeugen umzugehen, so wird dennoch die Zusammenarbeit mit der IT maßgeblich beschleunigt, die IT entlastet – und damit der Prozess für alle Beteiligten effektiver.

