
Hadoop feiert seinen 10. Geburtstag und ist zum Synonym für Big Data geworden. Mit rasant steigendem Datenvolumen werden aber auch die Herausforderungen bezüglich Datengüte größer. Ich hatte bereits einen Beitrag dazu geschrieben. Teil 1 finden Sie hier.
Wenn Daten ohne wirkliches Konzept an einen Ort abgelegt werden, gibt es ein Datenqualitätsproblem. Dabei spielt es keine Rolle, ob die Daten aus einer Datenbank, einem ERP-System oder einem Data Warehouse kommen.
Beispiele für Quellen schlechter Datenqualität: Werte fehlen / Ein Mussfeld ist leer / Geschäftspartner sind als privat klassifiziert oder als Organisation gekennzeichnet / Ausprägungen sind falsch / Dubletten usw usf.
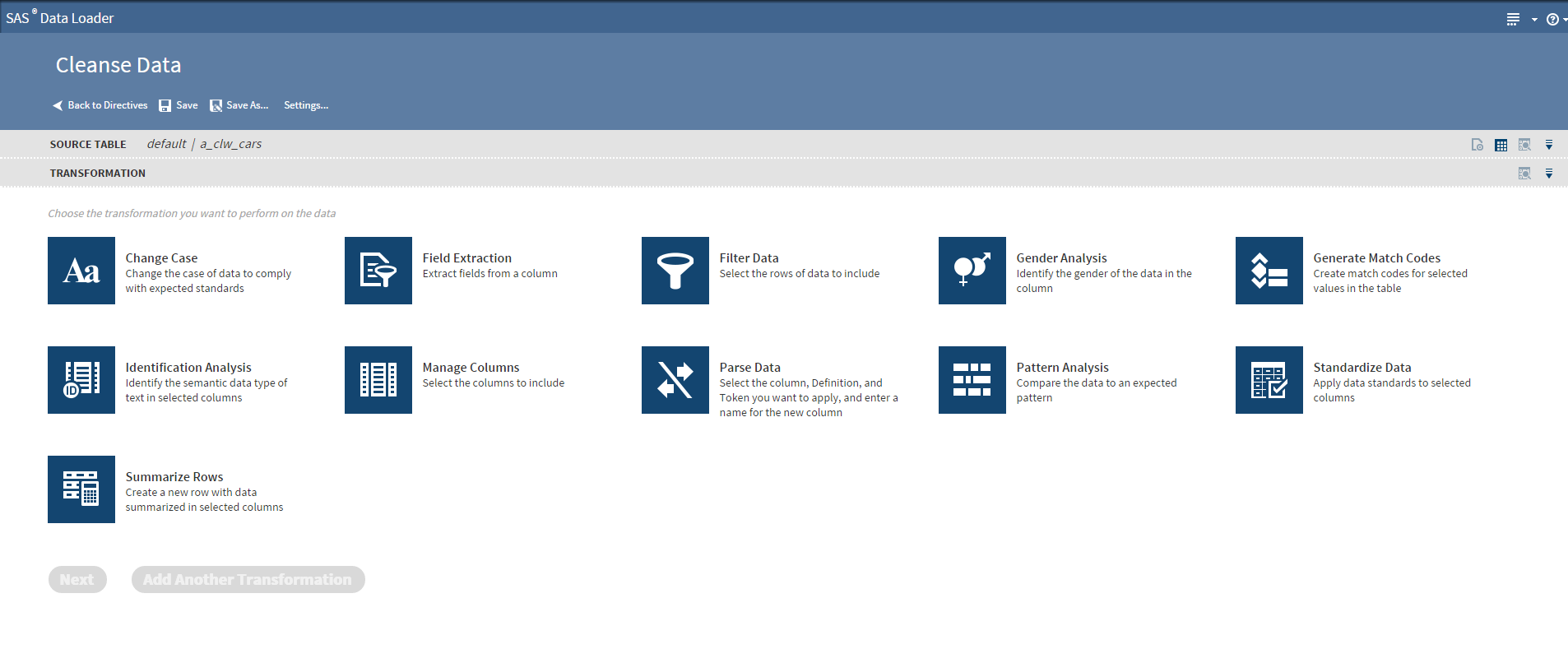
Das muss nicht sein, denn es gibt Methoden wie das Profiling, um Daten sauber zu halten. Mit dem Profiling bekomme ich schnell einen Überblick über die Dateninhalte. Mit Standardmetriken (Musteranalysen (Verteilung), Blank Count, Null Count, Eindeutigkeit, Ausreißer) kann der Anwender Inhalte schnell verstehen und Probleme erkennen.
Nach dem Profiling kommt: Fehlerhafte Daten nicht nur erkennen, sondern die Probleme beseitigen. Nicht selten wird versucht, mittels ETL-Tool mangelnde Datenqualität anzugehen. Aus der Erfahrung heraus benötigt man andere Funktionen, um fehlerhafte Datensätze zu bereinigen. Wenn es sich um semistrukturierte Daten handelt, ist es gut, einen Parser (Parsing-Definition) zu haben, der die einzelnen Token erkennt und diese in Feldern aussteuert, beispielsweise bei Weblogdaten, Geschäftspartnerinformationen und Produktdaten.

Neben Parsing ist die Standardisierung eine weitere wichtige Methode, um Daten zu vereinheitlichen. Darüber hinaus prüft beispielweise die Identifizierungssanalyse, ob eine E-Mail gültig ist, erkennt anhand der Domäne das Herkunftsland oder validiert Telefonnummern.
Letzten Endes ist es nicht eine Methode oder Funktion, die die Datenqualität verbessert, sondern die Kombination von vielen Methoden. Fachbereiche benötigen ein leicht zu bedienendes Werkzeug, das ihren Anforderungen bezüglich Datenqualität gerecht wird. Hier gilt: stellt die IT nichts zur Verfügung, wird durch das Business ein Workaround geschaffen (Schatten IT). Mit dem SAS Loader für Hadoop, könnte die IT dem Fachbereich ein geeignetes Werkzeug bereitstellen und damit das Hadoop Ecosystem wertvoller machen.
Der SAS Data Loader für Hadoop bietet Standardmethoden, um gute Datenqualtität innerhalb eines Hadoop-Cluster herzustellen und ist für Fachbereiche entwickelt.
Die Hadoop Welt ist in ständigem Wandel, manche Projekte etablieren sich im Markt - Spark ist hierfür ein gutes Beispiel. In der aktuellen Version des Data Loader für Hadoop 2.4 wird Spark für Cluster und Survive Data genutzt, eine Methode zur Dublettensuche und Erzeugung von korrekten Stammdaten, Stichwort Golden Record.
Wer das Data Lake Konzept umsetzt, sollte schon beim Speichern im Hadoop-Cluster für Datenqualität sorgen und dafür ein geeignetes Werkzeug nehmen. Anstatt mangelnde Datenqualität per Programmierung anzugehen.

