Erfahrungen aus einem Selbstversuch mit SAS Contextual Analysis

Bitte verstehen Sie mich nicht falsch. Ich bin unseren SAS Produkten und SAS Lösungen gegenüber in keinster Weise misstrauisch! Trotzdem wollte ich die Möglichkeiten unserer neuen Lösung für Text Analytics „SAS Contextual Analysis 14.1“ auf der eigenen Haut spüren und verstehen lernen. Und: das Ergebnis ist überzeugend! Fangen wir aber ganz vorne an.
Ein Blick in die Produktbeschreibung - Die Funktionen und Möglichkeiten von SAS Contextual Analysis
Blickt man in die Produktbeschreibung von SAS Contextual Analysis so erfahren Sie,
- dass Sie damit große Sammlungen von Text-Dokumenten analysieren, Sentiments identifizieren und robuste Modelle zur Kategorisierung und Extraktion von Inhalten erstellen können.
- Dies erlaubt Ihnen eine automatische Identifikation von Themen in Ihren Dokumentensammlungen und die Definition von Kategorien und der natürlich-sprachlichen Regeln für die Zuweisung zu diesen Kategorien.
Der Selbstversuch – Text Analyse meiner beiden Bücher im SAS Press Verlag
Um besser verstehen zu können, was bei der Text Analyse in SAS Contextual Analysis geschieht, habe ich eine Dokumentensammlung verwendet, die mir persönlich sehr nahe ist und die ich inhaltlich sehr gut kenne; die 59 Kapitel meiner beiden Bücher im SAS Press Verlag „Data Preparation for Analytics Using SAS“ und „Data Quality for Analytics Using SAS“.


Zugegeben: Die geringe Anzahl von 59 Dokumenten ist nicht gerade ein „Big Data Problem“ und der SAS High Performance Analytics Server bewältigt auch Dokumentensammlungen mit Millionen von Dokumenten. Für mich war es aber interessant zu sehen, ob SAS Contextual Analysis in meinen Kapiteln gemeinsame Themen finden kann und welche Kapitel zu einem thematischen Cluster zusammengefasst werden, ohne dass ich vorab Informationen beisteuere oder mein Wissen als Autor in die Kategorisierung einfließen lasse.
Die Text-Analytics Verarbeitung von SAS Contextual Analysis
Aus Data Mining Sicht haben wir es hier mit einer klassischen „Un-Supervised Analysis“ zu tun: Dem Analytik-Tool werden die Daten präsentiert, ohne dass es zusätzliche Informationen über eine mögliche Segmentzugehörigkeit oder das nächstfolgende Ereignis gibt. SAS Contextual Analysis läuft dabei automatisch die gesamte Prozesskette der Text-Analyse durch:
- Das Parsing der Wörter und Einteilung in unterschiedliche Entitäten (Hauptwort, Zeitwort, …).
- Die Synonym-Erkennung und die Berücksichtigung von Stop-Listen zur Entfernung von redundanten Wörtern, wie „der, die, das, und, von, mit, ….“
- Die Gewichtung der Wörter (Terme) und der Identifikation von Termen, die sich zur Gruppierung von Dokumenten eignen.
- Automatische Erkennung der zugrunde liegenden Themen in den Dokumente
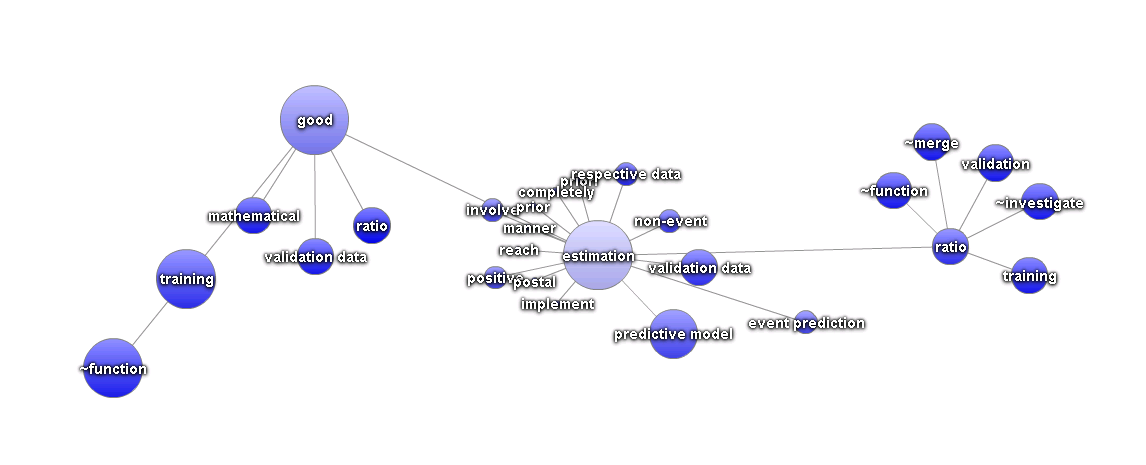
Es funktioniert! 8 sauber abgegrenzte Dokumenten Cluster als Ergebnis
Zur besseren Veranschaulichung habe ich die 59 Dokumente anhand ihrer Gewichte für die automatisch gefunden Themen mit einer Clusteranalyse im SAS Enterprise Miner analysiert. Dabei werden 8 Cluster gefunden, die in folgender Tabelle dargestellt sind. zur besseren Veranschaulichung sind die Kapitel des „Data Quality Buchs“ in grün und die Kapitel des „Data Preparation Buchs“ in gelb dargestellt.
Man sieht sehr eindrucksvoll wie die Kapitel anhand ihrer Inhalte zu unterschiedlichen Clustern zusammengefunden werden. Manche Cluster enthalten nur Kapitel aus einem Buch:
- Im Cluster 1 finden sich all jene Kapitel die im Data Quality Buch das Thema der fehlenden Werte behandeln.
- Oder das Cluster 7, welches die Simulationsstudien umfasst, die in den Kapiteln 15-23 beschrieben sind.
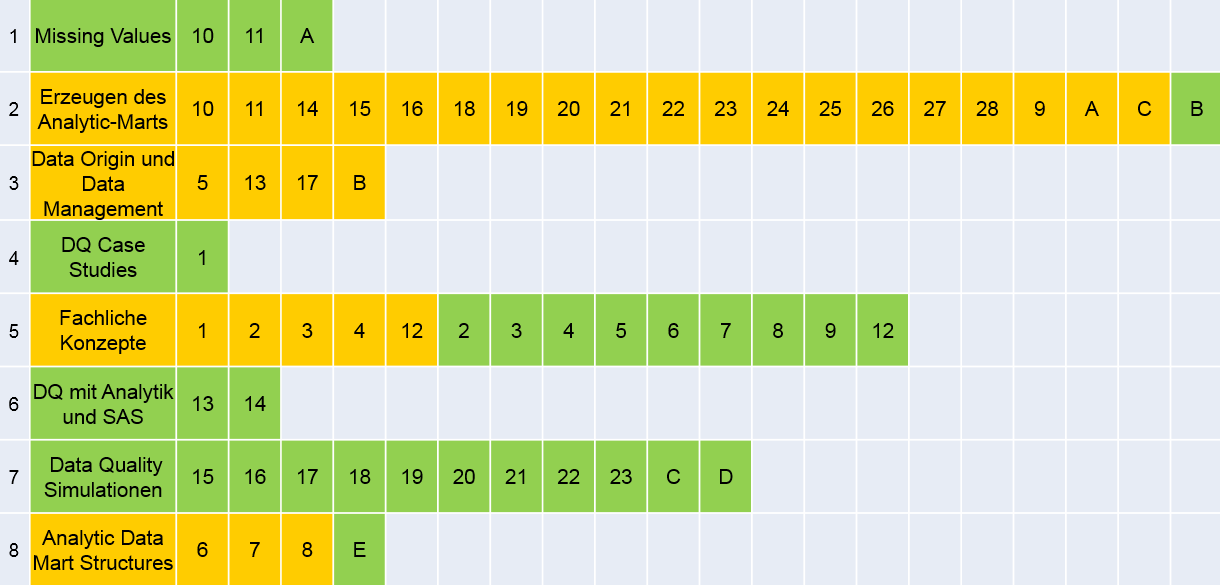
In manchen Clustern sind Kapitel aus beiden Büchern enthalten. Cluster 8 enthält die Kapitel zu analytischen Datenstrukturen aus dem „Data Preparation Buch“, der Appendix E im „Data Quality Buch“ ist eine Zusammenfassung aus diesem Kapiteln. Dies demonstriert eindrucksvoll, dass Inhalte, die quer über unterschiedliche Dokumente als „nahe“ oder „ähnlich“ erkannt werden sollen, tatsächlich auch als solche gefunden werden.
Die unterschiedliche Anzahl der Dokumente pro Cluster zeigt auch, dass hier nicht nach vorgegebenen Schemen vorgegangen wird, sondern dass die Kapitel ausschließlich anhand ihres Inhalts gruppiert werden. Cluster 4 enthält nur ein einzelnes Kapitel. Das Kapitel 1 im Data Quality Buch ist eine Sammlung von Fallbeispielen und vom Inhalt her nicht mit anderen Kapiteln vergleichbar.
Mit Vertrauen gestärkt zu neuen Anwendungsfällen
Diese Ergebnisse bestärken mich in meinem Vertrauen, dass Sie mit SAS Contextual Analysis Einblick in Ihre Dokumentensammlungen bekommen können. Sie erfahren, was Ihre Kunden über Sie denken, welche Themen in Ihren Texten enthalten sind und wie Sie diese automatisch in Gruppen einteilen können, ohne jedes Dokument einzeln lesen zu müssen.
Am nächsten SAS Club am 17. November 2015 in Wien präsentiere ich dieses Fallbeispiel live. Ich würde mich freuen, wenn ich Sie zu dieser Veranstaltung begrüßen kann.
