Zur Vorgeschichte
Meine Tante Susi ist eine ältere Dame, die auf ihren 80. Geburtstag zusteuert und auf dem Land wohnt. Den Festnetzanschluss bei ihren Telefonanbieter hat sie seit den 60er Jahren. Damals, und noch viele Jahre später, war es in Tante Susis Land üblich, dass man als Telekommunikations-Kunde nicht umworben wurde, sondern in Form eines Antrags um einen Telefonanschluss „bitten“ musste. Das war also noch lange, bevor Themen wie „Customer Relationship Management“ oder „Kundenbeziehung“ wichtig wurden. Mit einem solchen Antrag wurden somit auch keine personenbezogenen Daten (Geburtsdatum oder andere demographische Merkmale) erfasst, da man keine Notwendigkeit dafür hatte. Eines der wichtigsten Merkmale war eben die Adresse des Telefonanschlusses, damit man die Rechnung versenden konnte.
In den 90er Jahren kamen dann in vielen Unternehmen Themen wie „Kundensegmentierung“ und „Den Kunden besser verstehen“ auf, so auch bei Tante Susi’s Telefonanbieter. Ab dann wurde verpflichtend mit jedem Neuvertrag oder Vertragswechsel das Geburtsdatum des Kunden erfasst. Meine Tante Susi blieb von dieser Maßnahme unberührt, da sie den nie Vertrag wechselte oder erweiterte („Ein einfaches Festnetztelefon reicht!“) und auch nie an Kundenbefragungen oder Marketingaktionen teilnahm. Somit wurden von ihr nie zusätzliche Daten erhoben. Und sie ist nicht die einzige in dieser Situation. In ihrem Freundeskreis gibt es viele mit dieser „Datenhistorie“.
Der Statistiker in seinem Kämmerchen
Wenn nun der Statistiker in der Auswerteabteilung bei Tante Susis Telefonanbieter in die Kundendatenbank blickt, um eine Auswertung des „Alters der Kunden“ zu erstellen, sieht er möglicherweise folgendes Bild.
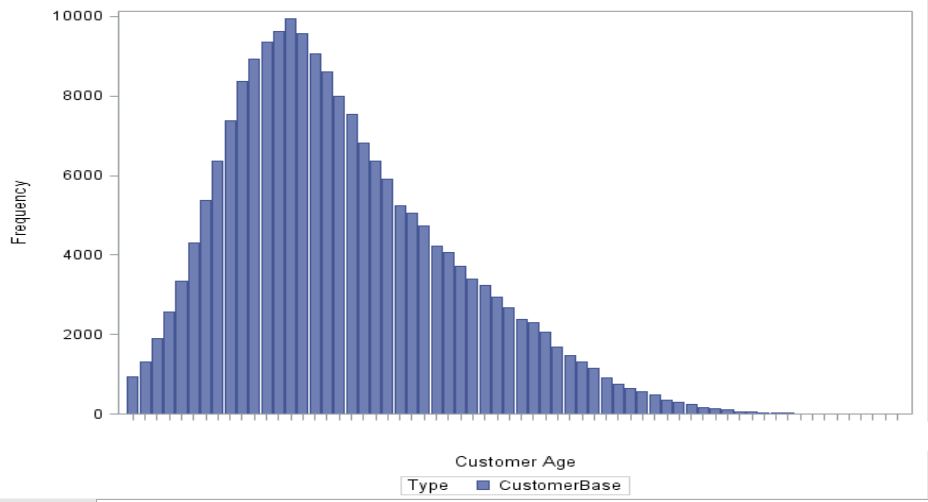
Die Altersverteilung nach Jahren zeigt, in welchen Altersgruppen es wie viele Kunden gibt. Auf dieser Basis lassen sich z.B. Prioritäten für Produktbündelungen oder Marketingaktionen nach Altersgruppen priorisieren.
Zusätzlich wird der Statistiker zu dieser Graphik noch den Anteil der fehlenden Werte angezeigt bekommen, d.h. wo das Alter aufgrund eines fehlenden Geburtsdatums nicht errechnet werden konnte. Dieser Anteil beträgt für unser Beispiel 9,1 %. Für den Statistiker stellt sich nun die Frage, wie er mit den fehlenden Werten umgehen soll.
- Soll er eine Gruppe mit „Alter unbekannt“ machen?
- Soll er die Beobachtungen mit fehlenden Werte von der Analyse einfach ausschließen?
- Soll er ein durchschnittliches Alter von etwa 42 Jahren annehmen?
- Oder ist es besser für die 9,1 % fehlenden Werte entsprechend der tatsächlichen Häufigkeitsverteilung Werte einzusetzen.
In den letzten beiden Varianten würde man implizit die Annahme treffen, dass es sich hier um zufällig fehlende Werte handelt und keine Systematik hinter der Tatsache „Geburtsdatum fehlt“ liegt.
Wenn wir nun aber zurück zu meiner Tante Susi und Ihren Freundinnen kommen, wird uns klar, dass die fehlenden Werte vorwiegend bei Kunden in der höheren Altersgruppe zu finden sein werden. Ab einem bestimmten Jahr konnte man ja gar keinen Vertrag ohne Bekanntgabe des Geburtsdatums bekommen. Somit können wir vermuten, dass die Verteilung der fehlenden Alterswerte sich nicht zufällig über die gesamte Verteilung erstreckt, sondern am rechten Ende der Verteilung angesiedelt sein wird, wie in der folgenden Graphik zu sehen ist. Die Bestimmung eines optimalen Ersetzungswerts für „Alter fehlt“ wird somit diese Tatsache berücksichtigen müssen und in Form einer fachlich basierten Regel erfolgen.

Der rote Bereich im Histogramm sind somit „meine Tante Susi und ihre Freundinnen“. Diese bilden genau genommen ein eigenes Kundensegment: ältere, langjährige Kunden, die für Produkt- oder Vertragswechsel keine Affinität gezeigt haben. Und sind somit bei Marketingaktionen und Kundenansprachen gesondert zu behandeln. Vielleicht haben diese Kunden Bedarf an spezieller Hardware (Telefon mit großen Tasten, einfache Bedienung), vielleicht benötigen sie spezielle Beratung durch die Hotline.
Hinaus in die Wirklichkeit!
Was lernen wir als Statistiker und Statistikerinnen daraus? Die Daten, die wir analysieren erzählen eine Geschichte. Sie reflektieren nicht nur den Wert, den sie messen sollen, sondern auch die fachlichen Prozesse, z.B. die Art der Datenerhebung und Datenspeicherung. Es ist somit für uns alle wichtig, nicht nur die statistische Brille, sondern auch die fachliche Brille aufzusetzen, um brauchbare Ergebnisse zu generieren. Für die statistische Auswertung gilt in diesem Fall: Selten passieren die Dinge zufällig. Machen wir uns also Gedanken, ob wir Gegebenheiten in den Daten wie fehlende Werte, Ausreißer, Fehler wirklich als zufällig „abtun“ können, oder ob wir hier diese Daten gesondert untersuchen und behandeln müssen.
Statistische Verfahren und SAS können uns hier helfen zu beurteilen, ob fehlende Werte zufällig sind oder ob systematische Muster dahinter liegen. Methoden dazu sind Kacheldiagramme, wie in meinem letzten Beitrag vom Februar 2013 schon vorgestellt, oder multivariate Verfahren wie die Hauptkomponentenanalysen für die fehlenden Werte. Eine andere Möglichkeit ist auch das Faktum „Wert fehlt ja/nein“ zu verwenden und dies in Form eines Predictive Models zu untersuchen und festzustellen, welche Variablen mit der Tatsache, dass das Geburtsdatum fehlt korreliert sind. Im Beispiel mit meiner Tante Susi würde man feststellen, dass dies Faktoren, wie „langjährige Kundenbeziehung“ und „einfaches Produktbündel“ sind.
Interesse geweckt?
Wenn diese Zeilen Ihr Interesse geweckt haben, finden Sie zu diesen Thema mehr Details in meinem neuen Buch „Data Quality for Analytics Using SAS“ bzw. können Sie die Folien meines Vortrags auf der A2013 Konferenz in London (Englisch) und der Predictive Analytics Konferenz in Wien (Deutsch) sehen. Den Picture-Blog meiner Büchern finden Sie hier.

