
Developers are trying to help AI to speak all the world’s languages, but it's a complicated journey.
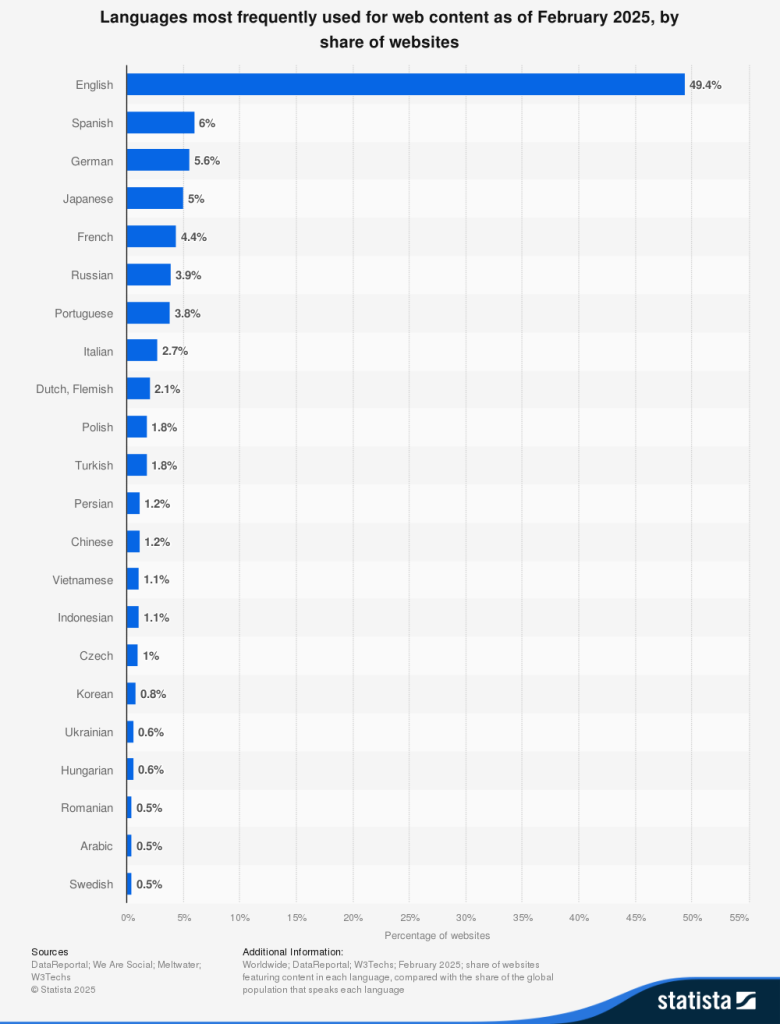
While there are around 7,000 languages spoken globally, digital technology primarily revolves around just a few. English dominates over half of all written content online, even though only around 16% of the global population speaks it. Meanwhile, languages with smaller digital footprints often struggle for representation, making accessing social media, e-commerce and other platforms tough.
Why AI struggles with language diversity
Large language models (LLMs) power everything from chatbots to translation tools, but they aren’t equally skilled in every language. That’s because AI models rely on vast amounts of text data to learn – and most of that data is in English or other widely spoken languages. The result? AI performs well in languages with abundant digital content but often stumbles in those with fewer online resources.
The imbalance isn’t just about quantity; it’s about complexity, too. Some languages, like Mandarin, use tones that change a word’s meaning. Others, like Finnish or Basque, have unique grammatical structures that don’t resemble the languages AI sees most often. Then there’s code-switching, which I've personally witnessed in multilingual communities like India, where the conversation might jump from Hindi to English to Marathi in a single breath. Capturing nuances that no dictionary could ever hope to translate presents a unique challenge for AI.
Even dialects with the same language can cause problems. Spanish, for example, varies significantly between Mexico, Spain and Argentina. But most AI models default to one “standard” version, leaving some speakers with translations that don’t fully capture their meaning.
Bias is also an issue
Bias is another major challenge. Since LLMs are trained on existing online content, they inherit the same biases found on the internet. If AI pulls most of its data from Western sources, it may misrepresent or exclude perspectives from other parts of the world.
This imbalance also affects AI performance, particularly for languages with a limited digital presence. We’ve already seen the consequences:
- A book title by Korea’s first minister of culture was mistranslated into an offensive phrase by Google Lens’s camera-based translation feature, allegedly due to its training on internet communications and a lack of context.
- Critics scrutinized a startup’s use of AI voice technology to alter or remove accents for call center agents, despite the company’s claim, as reaffirming bias.
- Names translated as months of the year, incorrect time frames and mixed-up pronouns are the everyday failings of AI-driven translation apps that are causing havoc in the US asylum system.
- The Japanese Broadcasting Corporation (or NHK in Japan) discontinued its AI-based multilingual subtitles service after its Google Translate-powered system mistakenly rendered 'Senkaku Islands' as 'Diaoyu Islands' during a live broadcast. The error raised diplomatic and accuracy concerns, prompting the broadcaster to end the service and consider developing its own AI translation system.
- Georgia Tech researchers found that chatbots are less accurate in Spanish, Chinese, and Hindi compared to English when asked health-related questions.
These examples highlight the real-world consequences of AI language bias. To build genuinely inclusive AI, developers must ensure that diverse languages and cultural contexts are adequately represented in training data.
Building better multilingual AI
So, how do we better integrate language with AI? It starts with better training strategies:
- Balanced sampling: Giving underrepresented languages more weight in AI training.
- Community involvement: Collaborating with native speakers and organizations like Masakhane (for African languages) and AI4Bharat (for Indian languages) to improve AI representation.
- Data augmentation: Using back-translation and text generation to create additional text in underrepresented languages.
- Synthetic data: Generating text using large multilingual models or generative adversarial networks (GANs).
- Data quality control: Developing language-specific preprocessing pipelines and using native speakers to validate data samples.
- Collaborative data sharing: Involves creating open-source datasets and establishing data-sharing agreements with other institutions. Projects like Mozilla's Common Voice and Meta AI's No Language Left Behind are pioneering efforts in this space. They collect vast amounts of voice data and continuously monitor model performance across multiple languages.
The ethics of multilingual AI
Language is deeply tied to culture and identity. If AI fails to represent a language accurately, it risks distorting meaning or marginalizing entire communities.
There’s also the issue of who owns the data. Many underrepresented languages come from cultures with strong oral traditions and digitizing these languages for AI use raises questions of consent and ownership. Who gets to decide how a language is used in AI models? And how do we ensure that AI serves as a tool for inclusivity rather than erasure?
A more inclusive AI future
The goal isn’t just to teach AI more languages – it’s to make AI work better for everyone. By investing in more inclusive training methods, collaborating with diverse language communities and tackling bias head-on, we can create AI systems that truly reflect the richness of global communication. Remember, responsible innovation begins with responsible innovators. As creators and stewards of technology, it is up to us to ensure that ethical principles and a commitment to inclusivity guide our advancements.
The digital world shouldn’t leave anyone behind. And with the right approach, AI can help bridge language gaps instead of widening them.
