Jede Analyse sollte damit beginnen, die Natur der zugrunde liegenden Datentabelle zu beschreiben und charakterisieren. Nur so kann sichergestellt werden, dass die in einer späteren Modellierung zugrunde liegenden Modellannahmen validiert sind und die Grundlagen der Analyseergebnisse den jeweils erforderlichen minimalen Qualitätsansprüchen genügen. Anderenfalls ist das spätere Modell sinnlos, die Analyse fehlerbehaftet, und die daraus abgeleiteten Erkenntnisse oder Maßnahmen sinn- und nutzlos,- ja im schlimmsten Fall könnten sie sogar kontraproduktiv sein und das Gegenteil bewirken, was man eigentlich erreichen möchte. Zur Charakterisierung einer Tabelle gehören beschreibenden Statistiken wie z.B. die Anzahl Beobachtungen (N) der Mittelwert, die Standardabweichung, Minimum, Maximum oder gewisse Perzentile. Ein oft vergessenes Qualitätsmerkmal ist die Häufigkeit von fehlenden Werten.
Darstellung fehlender Werte in SAS Tabellen
Keine Angst, fehlende Werte kommen selbst in den besten Studien vor. Man sollte mir ihnen nur korrekt umgehen. Standardmäßig werden fehlende Werte in numerischen Variablen durch SAS mit einem Punkt `.` angezeigt. Über die Option Missing=‘x‘ können auch andere Zeichen zur Anzeige von fehlenden Werten genutzt werden, wie das folgende Beispiel verdeutlicht.

Auszählen Fehlender Werte von numerischen Variablen
Für numerische Variablen genügt ein einziger Aufruf der MEANS-Prozedur, um die Antwort zu berechnen. Durch die Option _numeric_ im Var-Statement werden alle numerischen Variablen der Tabelle zur Berechnung der beschreibenden Statistiken selektiert; Allerding sollte man auch den Namen der Option zur Ausgabe von Missing Values kennen. Dieser heißt NMISS und muss im Prozedurkopf zusammen mit den anderen gewünschten beschreibenden Statistiken angefordert werden. Die Anzahl der fehlenden Werte werden dann in der Ergebnisspalte NMiss ausgegeben, wie im folgenden Beispiel verdeutlicht:
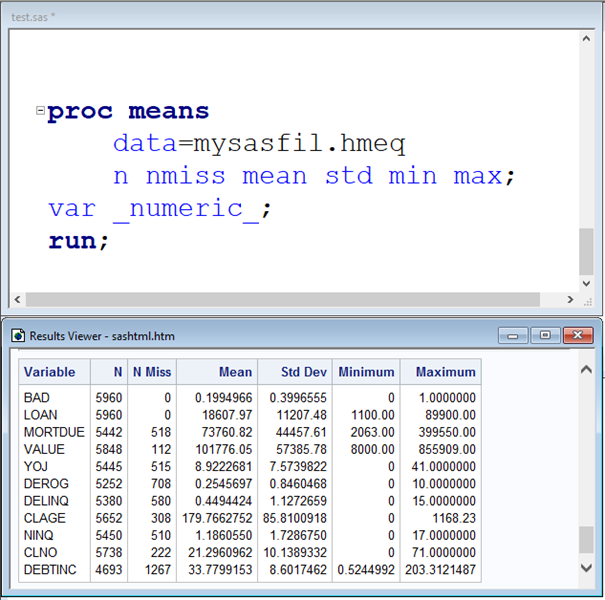
Wir sehen die Variable DEBTINC ist nur zu 79% mit validen Werten besetzt, denn sie hat 1267 fehlende Werte. Bevor wir diese Variable als Prädiktor in ein Modell aufnehmen können müssen wir uns gründlich Gedanken machen, den für 1/5 alle Fälle ist sie nicht aussagefähig.
Aber was ist mit den kategoriellen Variablen unsere Tabelle? Die haben wir bisher ignoriert. Wie sind deren fehlende Werte kodiert, und wie kann man deren fehlende Werte auszählen. Damit werden wir uns im nächsten BLOG beschäftigen.
Hier zum Schluss zur Vollständigkeit der Programmtext zum Kopieren:
data test;
do i= 1 to 10;
Wert=ranuni(123);
if i in (3,7,9) then Wert=.;
output;
end;
run;
proc Print;Title "1. Missing='.'";run;
Option missing='?';
proc Print;Title "2. Missing='?'";run;
Title;
proc means
data=mysasfil.hmeq
n nmiss mean std min max;
var _numeric_;
run;
