
Data is crucial for the development of artificial intelligence (AI) applications. However, the rapid availability of data is a challenge due to increasingly strict privacy regulations.
A possible solution is to use synthetic data. Gartner predicts by 2024 that 60% of the data used to develop AI and analytics applications will be synthetically generated.
What is AI-generated synthetic data exactly?
Where original data is collected through interactions with individuals, synthetic data is generated by an AI algorithm that generates completely new and artificial data points. It is new to apply AI in the data synthesis process to model the generated synthetic data in such a way that it mimics the characteristics, relationships and statistical patterns from the original data set. This is what we call a synthetic data twin, where one mimics original sensitive data with an AI algorithm.
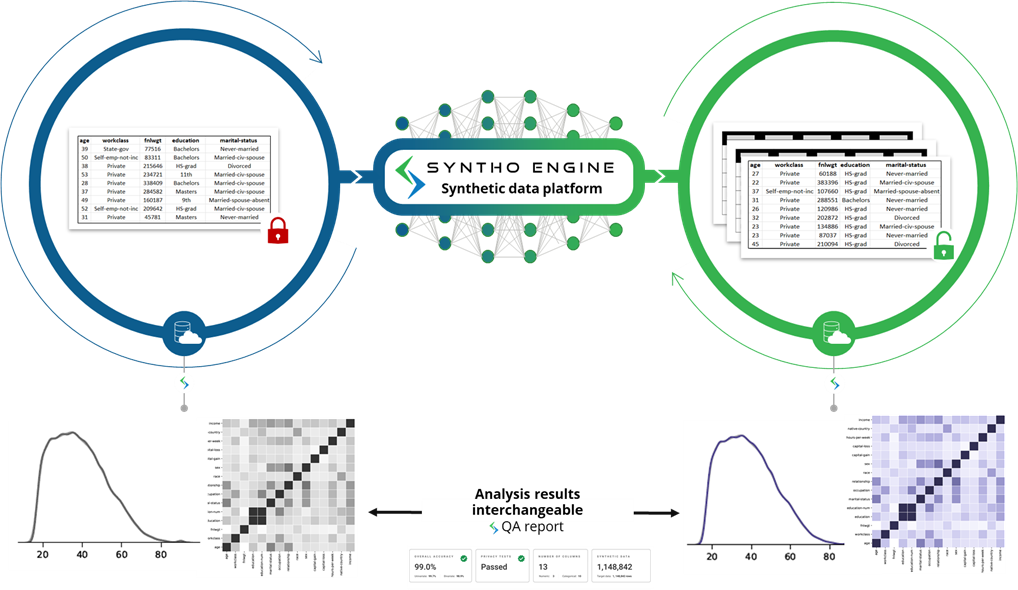
Synthetic data in practice
Syntho, an expert in AI-generated synthetic data, aims to turn privacy by design into a competitive advantage with AI-generated synthetic data. They help organizations to build a strong data foundation with easy and fast access to high-quality data and recently won the Philips Innovation Award.
However, synthetic data generation with AI is a relatively new solution that typically introduces frequently asked questions. To answer these, Syntho started a case study together with SAS. In collaboration with the Dutch AI Coalition (NL AIC), they investigated the value of synthetic data by comparing AI-generated synthetic data generated by the Syntho Engine with original data via various assessments on data quality, legal validity and usability.
Is data anonymization not a solution?
Classic anonymization techniques have in common that they manipulate original data in order to hinder tracing back individuals. Examples are generalization, suppression, wiping, pseudonymization, data masking and shuffling of rows and columns. You can find examples in the table below.
| Example technique | Original data | Manipulated data |
| Generalization | 27 years old | Between 25 and 30 years old |
| Suppression / Wiping | info@syntho.ai | xxxx@xxxxxx.xx |
| Pseudonymization | Amsterdam | hVFD6td3jdHHj78ghdgrewui6 |
| Row and column shuffling | Aligned | Shuffled |
Those techniques introduce 3 key challenges:
- They work differently per data type and per dataset, making them hard to scale. Furthermore, since they work differently, there will always be debate about which methods to apply and what combination of techniques are needed.
- There is always a one-to-one relationship with the original data. This means that there will always be a privacy risk, that is especially present due to all available techniques and open datasets.
- They manipulate data and thereby destroy data in the process. This is especially devastating for AI tasks where “predictive power” is essential because bad quality data will result in bad insights from the AI model.
An introduction to the case study
For the case study, the target dataset was a telecom dataset provided by SAS containing the data of 56.600 customers. The dataset contains 128 columns, including one column indicating whether a customer has left the company (i.e. ‘churned’) or not. The goal of the case study was to use the synthetic data to train some models to predict customer churn and to evaluate the performance of those trained models. As churn prediction is a classification task, SAS selected four popular classification models to make the predictions, including:
- Random forest.
- Gradient boosting.
- Logistic regression.
- Neural network.
Before generating the synthetic data, SAS randomly split the telecom dataset into a train set (for training the models) and a holdout set (for scoring the models). Having a separate holdout set for scoring allows for an unbiased assessment of how well the classification model might do when applied to new data.
Using the train set as input, Syntho used its Syntho Engine to generate a synthetic dataset. For benchmarking, SAS also created a manipulated version of the train set after applying various anonymization techniques to reach a certain threshold (of k-anonymity). The former steps resulted in four datasets:
- A training dataset (i.e. the original dataset minus the holdout dataset)
- A holdout dataset (i.e. a subset of the original dataset)
- An anonymized dataset (based on the training dataset)
- A synthetic dataset (based on the training dataset)
Datasets 1, 3 and 4 were used to train each classification model, resulting in 15 (3 x 5) trained models. SAS subsequently used the holdout dataset to measure the accuracy with which each model predicts customer churn. The results are presented below, starting with some basic statistics.
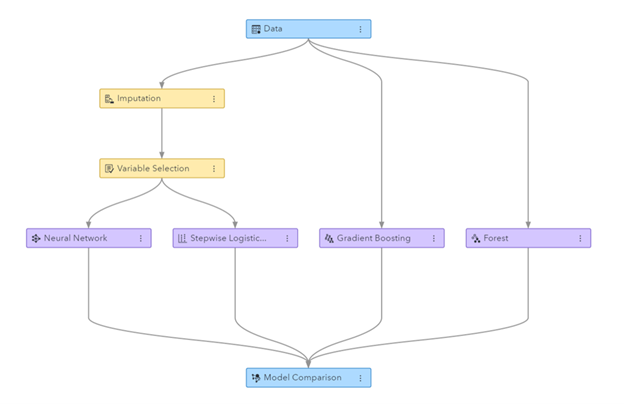
Figure: Machine Learning pipeline generated in SAS Visual Data Mining and Machine Learning
Basic statistics when comparing anonymized data with original data
Anonymization techniques destroy even basic patterns, business logic, relationships and statistics (as in the example below). Using anonymized data for basic analytics thus produces unreliable results. In fact, the poor quality of the anonymized data made it almost impossible to use it for advanced analytics tasks (e.g. AI/ML modeling and dashboarding).

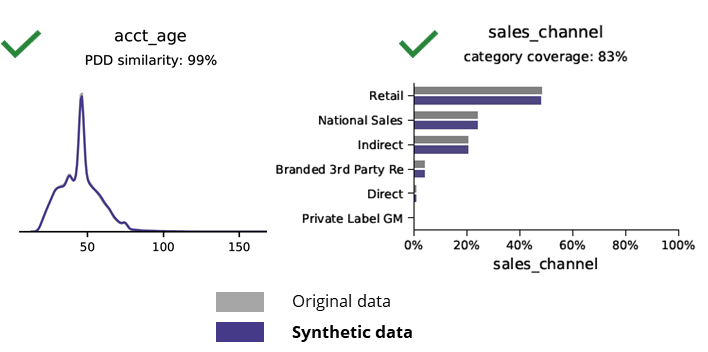
AI-generated synthetic data and advanced analytics
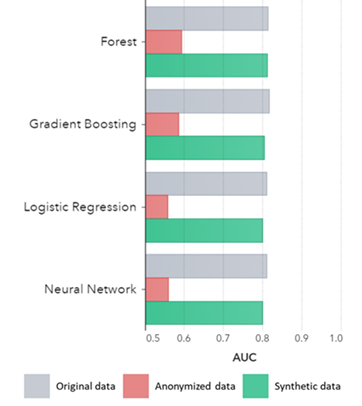
Synthetic data generation with AI preserves basic patterns, business logic, relationships and statistics (as in the example below). Using synthetic data for basic analytics thus produces reliable results. Synthetic data holds not only basic patterns (as shown in the former plots), but it also captures deep ‘hidden’ statistical patterns required for advanced analytics tasks. The latter is demonstrated in the bar chart below, indicating that the accuracy of models trained on synthetic data versus models trained on original data is similar. Furthermore, with an area under the curve (AUC*) close to 0.5, the models trained on anonymized data perform by far the worst. The full report with all advanced analytics assessments on synthetic data in comparison with the original data is available on request.
*AUC: the area under the curve is a measure of the accuracy of advanced analytics models, taking into account true positives, false positives, false negatives and true negatives. 0,5 means that a model predicts randomly and has no predictive power and 1 means that the model is always correct and has full predictive power.
Additionally, this synthetic data can be used to understand data characteristics and main variables needed for the actual training of the models. The inputs selected by the algorithms on synthetic data compared to original data were very similar. Hence, the modeling process can be done on this synthetic version, which reduces the risk of data breaches. However, when inferencing individual records (eg. telco customer) retraining on original data is recommended for explainability, increased acceptance or just because of regulation.
Other conclusions:
- Models trained on synthetic data compared to the models trained on original data show highly similar performance.
- Models trained on anonymized data with ‘classic anonymization techniques’ show inferior performance compared to models trained on the original data or synthetic data.
- Synthetic data generation is easy and fast because the technique works exactly the same per dataset and per data type.
Synthetic data for model development and advanced analytics
Having a strong data foundation with easy and fast access to usable, high-quality data is essential to developing models (e.g. dashboards [BI] and advanced analytics [AI & ML]). However, many organizations suffer from a suboptimal data foundation resulting in 3 key challenges:
- Getting access to data takes ages due to (privacy) regulations, internal processes or data silos.
- Classic anonymization techniques destroy data, making the data no longer suitable for analysis and advanced analytics (garbage in = garbage out).
- Existing solutions are not scalable because they work differently per dataset and per data type and cannot handle large multi-table databases.
Synthetic data approach: develop models with as-good-as-real synthetic data to:
- Minimize the use of original data, without hindering your developers.
- Unlock personal data and have access to more data than was previously restricted (e.g. due to privacy).
- Easy and fast data access to relevant data.
- Scalable solution that works the same for each dataset, datatype and for massive databases.
This allows organizations to build a strong data foundation with easy and fast access to usable, high-quality data to unlock data and leverage data opportunities.
Testing and development with high-quality test data are essential to delivering state-of-the-art software solutions. Using original production data seems obvious, but is not allowed due to (privacy) regulations. Alternative Test Data Management (TDM) tools introduce "legacy-by-design" in getting the test data right:
- Does not reflect production data and business logic and referential integrity are not preserved.
- Work is slow and time-consuming.
- Manual work is required.
Synthetic data approach: Test and develop with AI-generated synthetic test data to deliver state-of-the-art software solutions smart with:
- Production-like data with preserved business logic and referential integrity.
- Easy and fast data generation with state-of-the-art AI.
- Privacy-by-design.
- Easy, fast and agile.
This allows organizations to test and develop with next-level test data to deliver state-of-the-art software solutions!
More information
In this use case, Syntho, SAS and the NL AIC work together to achieve the intended results. Syntho is an expert in AI-generated synthetic data and SAS is a market leader in analytics and offers software for exploring, analyzing and visualizing data.
Like to learn more? For more information please visit the Syntho website or contact Wim Kees Janssen (CEO & Founder of Syntho) via e-mail: kees@syntho.ai or Edwin van Unen (Principal Analytics Consultant at SAS) via e-mail: Edwin.vanUnen@sas.com.
