Creating an architecture to support AI is about creating a modern platform for advanced analytics, and means being able to support all steps of the analytics lifecycle.
Requirements
An architecture for advanced analytics/artificial intelligence need to cover three main domains, data, discovery and deployment.
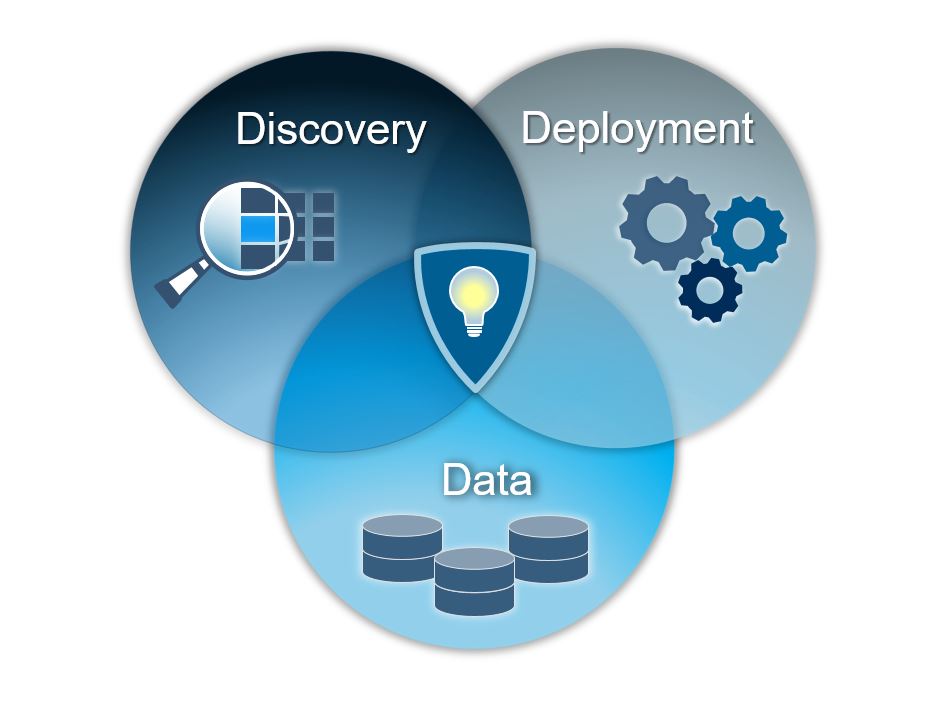
Data
Data is the foundation of analytics: after all, we need something to analyse. Data can come from a multitude of places and include a multitude of types such as:
- Traditional data in data warehouses and operational systems, most commonly relational databases and files such as CSV and XML. Because this is the most obvious source, most enterprises are most mature in handling these data.
- Hadoop systems, usually containing data lakes or data reservoirs, have become the default standard for storing huge amounts of data relatively cheaply but in a way that allows scalable performance.
- Streaming data can come from a wide range of sources, including sensors, network data, IoT, social media, and digital customer interactions. Working with streaming data is becoming increasingly important, as new types of data emerge, and the need for speed increases significantly.
Discovery
The discovery stage is where the magic happens. It includes exploring and modelling data to be able to understand them and also train algorithms and models. Data volume is increasing as the time permitted to obtain answers is decreasing, so platforms need to support different types of analytics in different places. We need capability to work as much as possible where the data resides (whether stream, relational database or data lake). There will, however, be cases where we cannot push everything down to the source. These include analytics that are more advanced than the source can manage, combining multiple sources or when the load is too great for the source system (for instance when an enterprise data warehouse is already struggling with performance).
Deployment
Deployment is where we actually get value from our analytics. This value comes from getting access to the data, understanding it and developing algorithms. It usually emerges when we actually apply this information. We need to be able to present the information in a clear and understandable way, generate data back to source systems or data warehouses and also integrate it into operational systems for automated decisions. All this needs to happen while reducing performance implications by working as close to the source as possible.
Technical capabilities
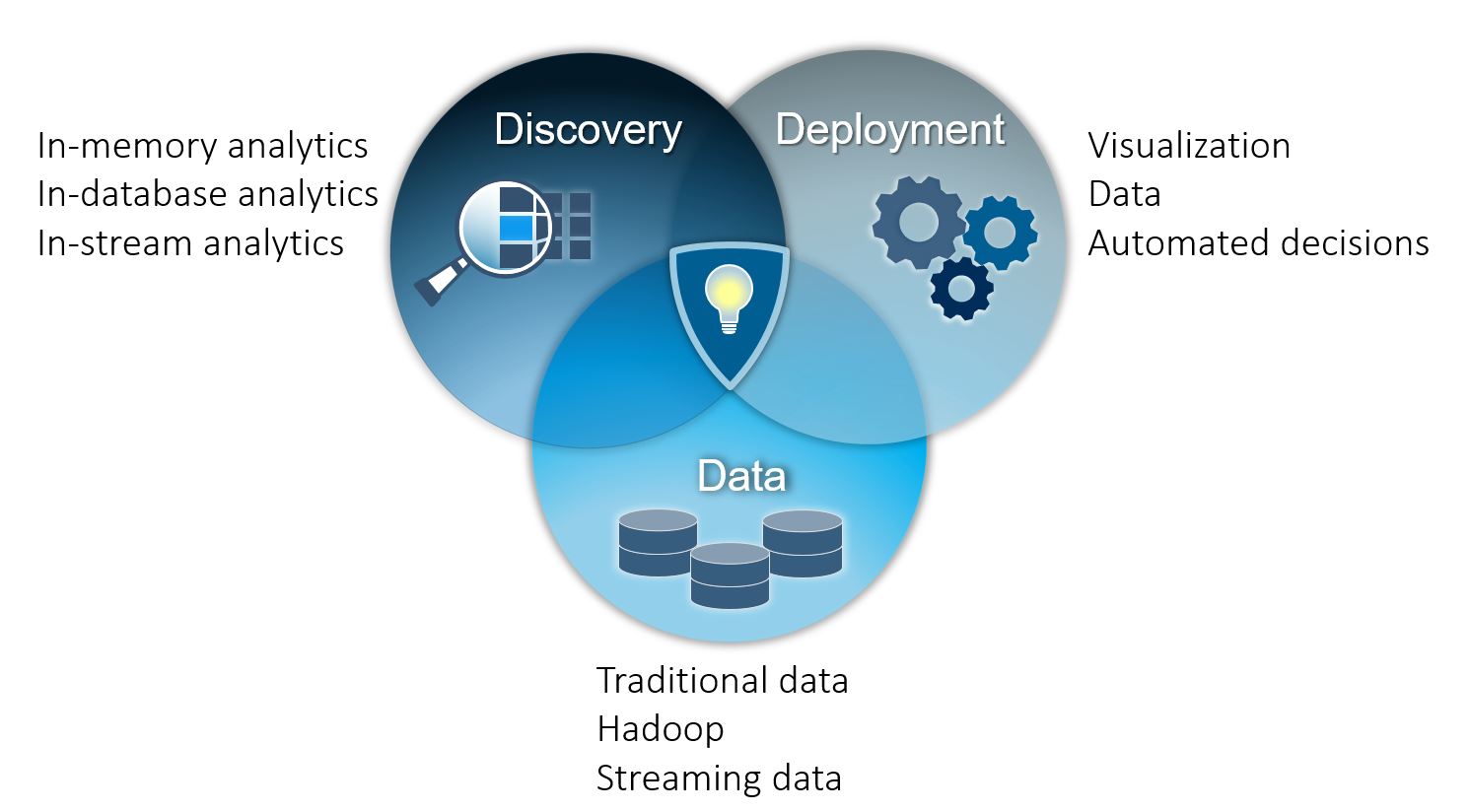
The technical capabilities also need to work across the three domains. The platform must be able to:
- Load available file formats, such as XML, CSV, JSON, and Excel;
- Access all types of available relational databases while pushing as much work as possible down to them, to reduce the amount of data movement;
- Access data from Hadoop while again pushing down as much work as possible; and
- Access, transform and analyse data in-stream from any source, without batches and with data in motion if possible, to manage high performance requirements.
Managing discovery
Three main components are needed to manage the discovery domain, in-database analytics, in-stream analytics, and in-memory analytics.
In-database analytics will perform advanced analytics without moving the data from the source, reducing the data extraction time. This can be extremely powerful, especially for data from a clustered environment such as Hadoop. It can also enhance more traditional databases by allowing them to score (use trained algorithms on new data) without extracting the data.
In-stream analytics is all about analysing streaming data without having to store it. Analysing streaming data is often time-critical, and in-stream analytics can speed things up. Tasks can range from more simple data discovery, to ongoing training and retraining of algorithms based on the data in the stream.
In-memory analytics is a great tool to achieve fast calculations of vast amounts of data. It is usually performed in a compute cluster, which allows for a scalable platform that can be ready for changes in requirements and increases in data size. This is where we combine data from multiple sources, and run analysis tasks that are not suitable for running at the data location.
As analytical problems become more and more complex, a combination of the three techniques will be needed. For example, streaming data may be joined with traditional data, or models may be trained in a separate in-memory cluster containing historical data and then deployed in the stream or to databases.
Deployment and value
Deployment can range from presenting the information clearly and making it easy to understand, to making automated decisions.
There are again three important categories of capabilities: visualization, data access and automated decision-making. Visualization is a powerful tool, most commonly used to present information within a business but also to customers.
Data is a common output from analytics and is commonly used to transfer the results back to enterprise data warehouses or data lakes for further analysis and consumption by other systems. The focus here is on delivering the data, not accessing what is already there.
Automated decisions are most applicable when discussing AI, where systems act by themselves in an quasi-intelligent way. This requires a way to define decisions based on algorithms, a way to retrain/evaluate the algorithms and then integrate the results into the system where the decision should be made, for example, a web site or call centre application. To achieve flexibility and shorter implementation times, this is usually done by REST web services.
One platform for the analytics lifecycle
Alongside the technical capabilities, it is also important to support the process around the analytics.
Data are required, and deployment is needed to get value from analytics, so all three domains need to work together to support the whole analytical lifecycle. This includes both agile discovery on the left-hand side and the governed, automated parts of the right-hand side. The most efficient way to achieve a good interaction across both sides of the analytics life cycle, and have working overlaps between data, discovery and deployment, is to use a common platform for advanced analytics. This will minimize the work required to integrate the different domains, such as manual work to deploy an algorithm created by an analyst focusing more on assuring the quality than on actually rewriting the model itself.
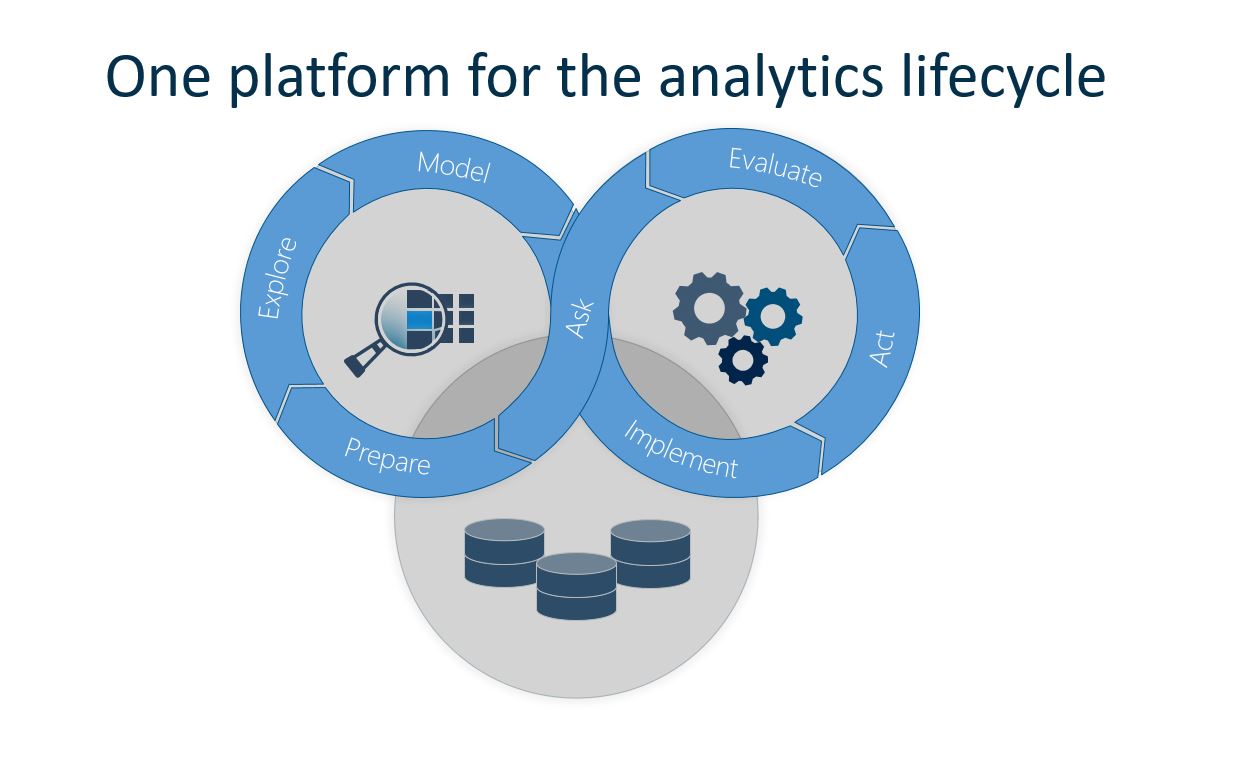
To achieve this, the platform will need some extra capabilities:
Governance for decision management
This includes versioning of models/algorithms, and automatic deployment and evaluation of the models when they are running in production. This is important because it gives the IT side and the analysts creating the models a common framework. It also frees up time because the modeller will not need to focus on evaluation of models, and the IT side will not need to recode the algorithm.
A data lab where analysts can work in an agile manner
This will enable them to prove or disprove hypotheses quickly. Rapid prototyping can be extremely beneficial in analytics. The data lab will contain much of the same components as the regular platform, and should be built in the same way, so content can move out of the lab and be reused when building a production flow. This can be isolated in the same environment as production, but is more commonly built as a separate environment alongside the production platform.
An open approach to allow additional systems to be integrated
Although the platform is built to handle all possible types of analytical problems, there will always be something that must be solved outside it. Specialized systems containing algorithms for a specific task or models and algorithms written and developed by other tools will need to be incorporated into the process and governance. The platform therefore needs to be open, to allow integration with other systems to support decision-making. The platform must support governance and evaluation of models built both within and beyond it.
Platform capability for the AI analytics lifecycle
We hosted a digital panel discussion on Twitter covering this theme. Read the #saschat summary here: Platform capability for the AI analytics lifecycle

2 Comments
Hi, how do I follow the panel discussion without Twitter? Is there a way to follow it from outside Twitter?
"We will host a digital panel discussion on this topic on Twitter. Join us on Wednesday, 28th February from 6pm CET (5pm UK, noon ET and 9am Pacific) to explore data, discovery and deployment effectiveness. You can follow the discussion with hashtags #analyticsplatform and #saschat."
We are delighted in your interest in this saschat. While the best experience is from being logged in to a Twitter account and engaging with the panel it is nevertheless possible to simply follow the conservation. You do not need a Twitter account, just search for Twitter #saschat and this url will allow you to see the discussion https://twitter.com/search?f=tweets&vertical=default&q=%23saschat