Now there is a lot of discussion around data virtualization, and as new types of data emerges this creates need for new ways of accessing and consolidating data across sources (both structured and non-structured).
Data Virtualization is not something new, in its simplest form it is creating abstracted views on top of data, either as an abstraction layer, or as a consolidate data view from multiple tables. Thus, for example SQL and Data Views is just that, virtualization of your data.
In addition to visualizing your data these views also offer the functionality of maintaining security on row/column levels and the enrichment of data (computed columns). Most database systems have views; some of them segmented into dynamic views (run on query) and materialized/cached views (stored ready for execution and updated on change on underlying data).
Some databases such as Teradata, Netezza and some NoSQL vendor’s even recommend only allowing data access through the view layer, this to better control data access.
Wikipedia states the following functionalities of Data virtualization[1] :
- Abstraction – Abstract the technical aspects of stored data, such as location, storage structure, API, access language, and storage technology.
- Virtualized Data Access – Connect to different data sources and make them accessible from a common logical data access point.
- Transformation – Transform, improve quality, reformat, etc. source data for consumer use.
- Data Federation – Combine result sets from across multiple source systems.
- Data Delivery – Publish result sets as views and/or data services executed by client application or users when requested
Since the definition of Data virtualization varies from provider to provider, based on the Associated functionality, benefits and flexibility, I think it is best understood by describing the flow in a diagram:
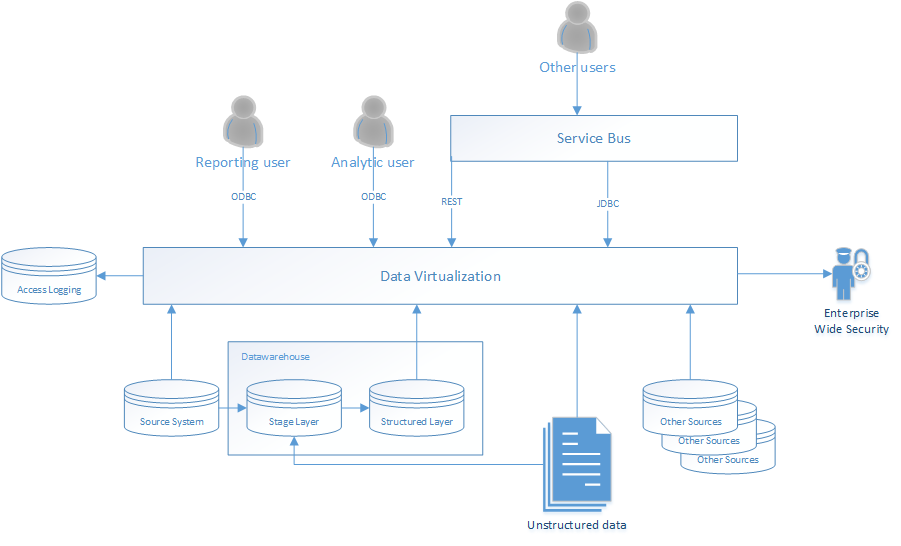
Fig 1. Flow addressing a variety of ways on utilizing Data Virtualization
Security
As end users, via one common layer access all underlying data, we have a single point of access that provides us:
- Possibility to have an Enterprise Security platform facilitating access to the data , providing for instance column, row level security and masking/encryption of sensitive data
- Possibility of logging all accesses done to the data, facilitating tracking of all queries down to the level needed to be able to analyze log data to discover anomalies through the analysis of log data
This helps both in control of data as well as compliance with data regulations such as the Personal Data Act.
Speed of development
As the Data Virtualization view is flexible, we can change where it looks for its data. Thus if an end user orders data, it can quickly be provided by virtualizing it by pointing against for instance the source system. After qualifying that this is what the end user wants, data quality and control can be achieved via standard ETL/ELT processes through for instance a Data warehouse. After this process is finished the virtualization view is repointed against the Structured Layer.
The end user will be unaware of this and:
- End-user applications can be developed from day one of the delivery cycle
- If the data is not what the end user wants, this is picked up immediately and not after days (or weeks) of ETL development
Added data value
As we can combine structured data with unstructured data or other sources, we can add upon our data for data scientific purposes. This provides us with the capability of being able to quickly explore and pick up data that can provide added insight or value. Further, it would require a defined change process for utilizing and transforming this data into day-to-day operations, but having the tools and methods for it is essential.
Data as a Service (DaaS)
By creating a standardized accessible layer, we can provide data to subscribers/consumers as a service. Technology would normally be standard Data access protocols such as ODBC/JDBC as well as Web Services such as REST, JSON etc.
Data deduplication
Closely tied to DaaS is deduplication. With the power to dynamically virtualize our data, as well as better controlling which data we have and standardizing connections to it, we can greatly reduce data duplication cost:
- End systems can use data as a service and not maintain complete copies
- By minimizing number of layers in a DWH system as logic can be virtualized
- We can maintain data quality and consolidation in virtualized layers
Normalized data
By facilitating data this way we can also control the data flow to the providers, meaning that this is our key to provide Master Data, as facilitated with Master Data Management and Data Quality solutions. Thus, we can normalize data that come from different sources and provide the same information and add to it quality/golden data.
Cached (fast) reads
One very important aspect is that as the service layer can be used from operational systems, it needs to be able to provide near real-time information without having to run large queries against source systems. In a virtualized or federated platform, this is normally achieved by caching queries or data in the federated layer (either static or dynamically). Thereby essentially moving the data closer to the requester.
Can I Virtualize my Data Warehouse?
Then the big question; is it possible to virtualize an entire data warehouse? Yes, with current technology, it is possible, but it would be very expensive and complex and need to balance the ratio between the rapid expansion/explosion of data vs. rate of growth of processing power.
Ion Stoica of Berkeley states the following “While making decisions based on this huge volume of data is a big challenge in itself, even more challenging is the fact that the data grows faster than the Moore’s law. According to one recent report, data is expected to grow 64% every year, and some categories of data, such as the data produced by particle accelerators and DNA Sequencers, grow much faster.# This means that, in the future, we will need more resources (e.g., servers) just to make the same decision!”[2]. Meaning that to fit and continue growing all current data into this “new” technology, we would need to horizontally grow processing power, memory and network etc. Hence, the cost of operation would just continue to grow.
Thus my opinion is that within 5 years, storage and network technologies will have become so fast that we can start to build one big virtualized Data Access point for all our data, where everything is accessible in real-time and automatically cached from underlying “old fashioned” storage solution. We are already seeing the outline of this technologies with intelligent near data processing like Hadoop in-database Analytics procedures that runs everything close to data and in memory.
The future is fantastic; the technology that is available today is lightyears beyond what it was 5-10 years ago. Meaning that there is no reason to wait with starting to adopt virtualization techniques, as it will give huge benefits today. For now, it should complement your data warehouse strategies as stated above, but not replace them.
Further as data is becoming one of the highest valued assets of modern companies, utilizing DaaS aligns Data Warehouse against a SOA (Service Orient Architecture), meaning that data can much easier be integrated into any type of system and making data the heart of your company.
However, in 5 years who knows?
SAS® Technologies
SAS® Federation Server provides data virtualization, security, traceability, data federation, data services etc. See http://www.sas.com/en_us/software/data-management.html for more information on SAS Data Management, Data Quality and Data Federation Solutions.
-----------------------------------------------------------------------
[1] https://en.wikipedia.org/wiki/Data_virtualization
[2] https://amplab.cs.berkeley.edu/for-big-data-moores-law-means-better-decisions/
