Even though it sounds like something you hear on a Montessori school playground, this theme “Share your cluster” echoes across many modern Apache Hadoop deployments.
Data architects are plotting to assemble all their big data in one system – something that is now achievable thanks to the economics of modern Apache Hadoop systems. Once assembled, this collection of data now has sufficient gravity to attract the application processing towards it – and people are increasingly becoming intolerant of the idea that we should make another copy (and have to reconcile, secure and govern that copy) to facilitate processing.
Move the Work to the Data
One of the original themes in Hadoop is to move the work to the data. MapReduce is a beautiful expression of this – the work is expressed in Java classes, and these classes are literally copied and executed across all the data nodes that participate in processing the data.
Apache Hadoop YARN takes this idea to the next level. YARN allows for users to move different kinds of computation to the data while sharing both the data and the resources of the cluster – allowing newer applications to run alongside traditional MapReduce workloads.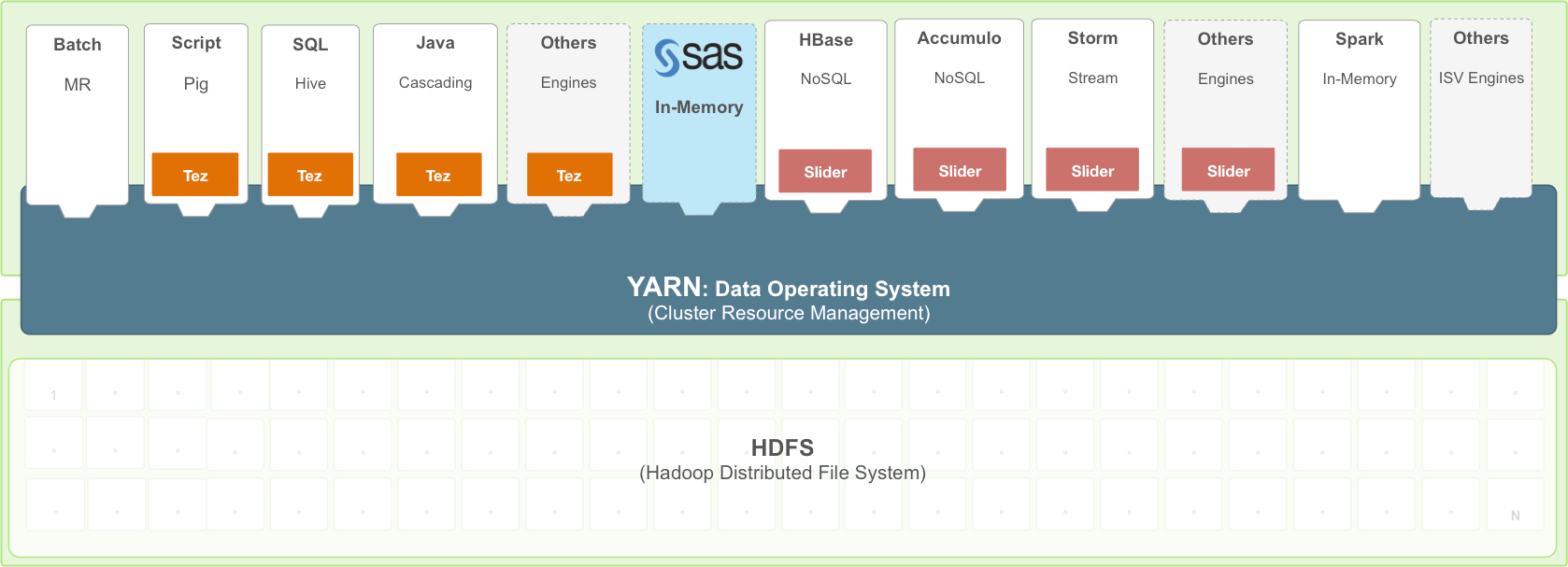
The SAS approach to YARN integration
SAS High-Performance Analytics (HPA) products and SAS LASR Analytic Server-based products are both based on classical high-performance computing methods, and they both began life as a traditional MPI application. The “mpirun” command launches an instance of the application on each host in the host list. These instances are bound together by infrastructure so that they can communicate easily with one another. SSH is used to create processes on the cluster, and as a practical matter, we use password-free SSH or Kerberos keys to save from having to repeat passwords over and over.
For SAS workloads, the ability for worker tasks to communicate with each other to solve the problem "team-style" is preferred to the MapReduce model. In MapReduce, each worker is assigned a slice of the dataset and must process that slice in relative isolation, handing off the results to a downstream task without learning anything from other workers doing the same processing on their slice.
Adopting YARN allows us to use the YARN infrastructure to set the boundaries for the processes needed to run SAS HPA products and SAS LASR Analytic Server products. CPU and memory can be capped, facilitating a better sharing model for the cluster. Our early adoption and expanded integration with YARN positions SAS as a good citizen at the center of shared Hadoop clusters. Our engineers have been working with Hortonworks engineers on the best way to integrate SAS HPA and SAS LASR Analytic Server with Hadoop YARN. The result of these efforts means that customers will get the maximum benefits from their Hadoop clusters.
This is an exciting development for us. SAS applications bring advanced, in-memory analytic processing to the data in Hadoop. Working with Hortonworks, our combined technologies offer customers more flexibility to choose best of breed SAS High-Performance Analytics and LASR analytic applications in conjunction with their trusted Hadoop workloads as they build and deploy bigger Hadoop clusters.
Get more information on how Hortonworks and SAS work together to turn big data into a business advantage.

1 Comment
Pingback: SAS scalability: 4 concepts you should know - SAS Users