 This is the third of the seven parts of blog post series “A practical guide to tackle auto insurance fraud”.
This is the third of the seven parts of blog post series “A practical guide to tackle auto insurance fraud”.
In the first two articles of the series we drilled down to Data Management and Data Quality as the basis for insurance fraud detection analytics and also to the Business Rules and Watch lists techniques that play always a crucial role for claim handlers and fraud investigators. This 3rd article of the series analyses the basic concepts of advanced analytics methodologies and techniques, for tackling the “unknown” fraud, the fraud patterns & details that are not yet known, but fraudsters are utilizing to maximize their success rates.
Why tackling the “unknown” fraud is important
In order we define the scope and the value of the advanced analytics in a fraud detection process, we first need a common understanding of what is “unknown” fraud.
In the previous blog post series article Business Rules and Watch lists we analyzed analytics techniques for tackling the “known” fraud, meaning the fraud patterns and indicators that are already known to the investigators as suspicious fraud behavior. A classic example of “known” fraud patterns is watch lists of known fraudsters or a high claim value for car damages with a contradictory very clean accident scene. However the organized and experienced fraudsters and fraud gangs usually know the “rules of the game”, they are aware that investigators are looking to this known fraud indicators and typologies. So, although the Business Rules and Watchlists analytics techniques bring high value returns in “junior” or “starter” fraudsters, they do not have the same success to experienced insurance scammers and organized fraud rings.
How insurers can fight back? Via embracing advanced analytics to fight the “unknown” fraud, to fight the fraud typologies that are out of our radar, the typologies that are not yet known to the investigators and that will drain our savings before we find out what is going on.
First stop in the advanced analytics techniques is:
Anomaly Detection
For a common understanding lets first define what is Anomaly Detection (source Wikipedia):
“In data mining, anomaly detection (also outlier detection) is the identification of items, events or observations which do not conform to an expected pattern or other items in a dataset.”
As an example in the auto insurance claims fraud area, anomaly detection can be used for identify loss padding in similar insurance claims or identify suspicious claims with high abnormal ratio of body injuries vs car damages.
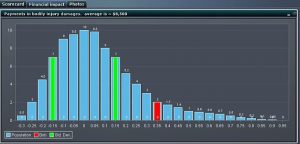
With anomaly detection, specific measures associated with a claim event are baselined, and thresholds are set. When a submitted claim has a specific measure that exceeds the threshold then this anomaly is highlighted, reported and added up to a fraud risk score, taking into account and other kind of violations in additional fraud detection techniques (e.g. like violations in business rules, watch lists etc.).
Second stop in the advanced analytics techniques is:
Clustering and Segmentation
Clustering technique is utilized in order we isolate and identify group of claims with specific characteristics that are highly suspicious for fraud (e.g. via k-means algorithm with hierarchical clustering or other). For profiling the clustering outcome and a more thorough understanding of the differences between the clustered groups, decision trees or logistic regression can be utilized.
The clustering identifies abnormal groups of claims, either in every aspect and this can be a fraud indicator by it’s own, or abnormal groups compared to a investigated customer base or segment or even contain values that are abnormal in relation to each other, e.g. a 20 year-old driver with a Porsche might warrant a closer look.
The principle is that fraudulent claims when visualized in cluster analysis will group together in unforeseen ways much different to the norm.
Third stop in the advanced analytics techniques is:
Text Mining
Unstructured data, data in free text format can be found in many areas and processes in the insurance industry. It is estimated that 80% of the available data is unstructured and currently not utilized by insurers. Such data are emails, social media, call center notes, adjuster notes, police reports and other.
This is true also for fraudsters, who interact with the call center, can send an email for requesting a fast pay out and they have a social media account. Insurers are used to track and store a lot of information for every claim or every customer or claimant interaction in various forms (notes, comments in applications, free text description of the accident scene etc.). So, lots of unstructured data are stored that include interactions with fraudsters and possible evidence and indicators of their acts.
These unstructured data can bring high value in the fraud detection process and the insurer can identify new fraud patterns and typologies via applying Text Analytics / Text Mining techniques to free text data.
Text mining parses free text data in large volumes and identifies common topics of meaningful data (e.g. with singular value decomposition analysis) in specific customer or claim segments, e.g. it can be suspicious many unrelated claims to have a common topic (all say the same thing) and at the same time belong to a same cluster of other characteristics. With such a technique a fraud gang that was setting up staged car accidents in unsupervised parking areas has been detecting and tackled, the common topic was related with the “parking area” and the staged accidents were reported to happen in overnight hours.
Fourth stop in the advanced analytics techniques is:
Predictive Modeling
Based on Wikipedia: “Predictive modeling uses statistics to predict outcomes. Most often the event one wants to predict is in the future, but predictive modelling can be applied to any type of unknown event, regardless of when it occurred. For example, predictive models are often used to detect crimes and identify suspects, after the crime has taken place. Depending on definitional boundaries, predictive modelling is synonymous with, or largely overlapping with, the field of machine learning.”
In insurance fraud predictive modeling (e.g. multivariate logistic regression, machine learning for supervised models) is utilized in the basis of the detection theory to try to guess the probability of an outcome (e.g. claims fraud) given a set amount of input data (e.g. claims data, policy holder data, policy etc. that have been analyzed in the blog post series 1st article for Data Management and Data Quality). Claims adjusters simple enter data and claims are automatically scored, even in real time, for their likelihood to be fraudulent.
However, although that this technique is powerful, an insurer has to take into consideration the following:
- Requires a mature insurer in matter of fraud analytics, plenty of historical data are needed available with identified fraudulent claims, so the model to be able to produce high value and prediction accuracy.
- The predictive model success rate decreases with age, as criminals adopt new approaches, models needs calibration and must be updated to reflect new patterns. The monitoring of the model stability and accuracy metrics (e.g. Lift, ROC, KS) should be on a frequent basis, e.g. monthly.
Fifth stop in the advanced analytics techniques is Social Network Analysis, the most powerful advanced analytics technique that can detect organized fraud rings and gangs. Due it’s importance we will analyze it thoroughly in the next blog post series article.
Key message
Tackling unknown fraud with advanced analytics is a must do step for every insurer in a fraud analytics journey in order to tackle organized fraud gangs. Specialized fraud prevention software needs to include powerful Big Data Analytics components. An insurer is not needed to start via putting in action all advanced analytics techniques at once, anomaly detection can be a 1st step and then clustering, predictive modeling and text mining can follow via a phased approach.
This is the 3rd post in a 7-post series, “A practical guide to tackle auto insurance fraud”. This series explores 7 analytics best practices techniques that insurers need to follow for tackling auto insurance claims fraud. Next post deals with the most powerful technique of Social Network Analysis, for tackling organized fraud gangs and uncovering hidden relations between various claim entities.
For a deeper insight, don’t miss to watch the on-demand Insurance Fraud webinar series that were completed on September.

2 Comments
Pingback: A practical guide for auto insurance fraud – Opening Welcome - Bright Da
Pingback: A practical guide to tackle auto insurance fraud - Social Network Analytics