 In the first three articles of the series we drilled down to Data Management and Data Quality as the basis for fraud detection analytics, to Business Rules and Watch lists techniques that play always a crucial role for claim handlers and fraud investigators and to Advanced Analytics which add a layer of defensed towards the unknown fraud typologies that more experienced and organized fraudsters utilize.
In the first three articles of the series we drilled down to Data Management and Data Quality as the basis for fraud detection analytics, to Business Rules and Watch lists techniques that play always a crucial role for claim handlers and fraud investigators and to Advanced Analytics which add a layer of defensed towards the unknown fraud typologies that more experienced and organized fraudsters utilize.
This 4th article of the series analyses the most powerful of the advanced analytics technique, the Social Network Analysis, for uncovering current of past, hidden relationships between all involved parties and entities in a claims and not only process.
What is Social Network Analysis?
Many times Social Network Analysis is understood wrongly like relations in social media, in Facebook, LinkedIn, Twitter etc. between individuals. This is not the case or better this is not only the case, meaning that Social Media Analysis can constitute only a subset of Social Network Analysis, providing some more information that can be utilized for tackling insurance fraud. The main focus of the current article is not on Social Media, but on links and hidden connections between claimants, policy holders, drivers, service providers, investigators, agents, lawyers and others.
But let’s start with a definition of Social Network Analysis by Wikipedia:
“Social network analysis (SNA) is the process of investigating social structures through the use of network and graph theories. It characterizes networked structures in terms of nodes (individual actors, people, or things within the network) and the ties, edges, or links (relationships or interactions) that connect them.”
In the area of auto insurance fraud the nodes can be the individuals associated with a claim, e.g. the claimant, the driver and the link can be that they share a shame home address which triggers suspicion for a staged crash accident as at least it is obvious that they know each other.
There are two main areas relevant to the Graph Theory that have very unique value for tackling Insurance Fraud: the Bipartite graphs and the Homophily in Social Networks.
The first relates to the technique of representing the network, not only by individuals, which we need to identify who is fraudster and who is not, but also to include other related characteristics/resources like telephone numbers, addresses, bank accounts etc., and this can be achieved via introducing new type of nodes based on the Bipartite graphs theory.
The Homophily (from sociology) is the "love of the same", is the tendency of individuals to associate and bond with similar others. This is more than true also in fraud networks, as fraudulent people have a high probability to be connected to other fraudulent people, and legitimate people have a high probability to connect to legitimate people.
Now let’s define of what a Social Network Analysis can consist of in the auto insurance industry.
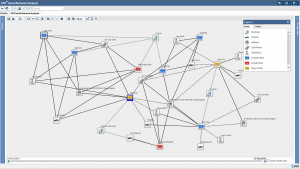
Entity Resolution
A list of entities that relate to an insurance claims process is as below, but not limited to:
|
Claimant |
Lawyers | Telephone numbers |
| Policy Holder | Investigators |
Addresses |
|
Drivers |
Suppliers/Body shops |
Bank accounts |
| Participants | Body Shops |
Citizen IDs / Tax IDs |
| Witnesses | Claims Officer/Adjuster |
Vehicles |
At the same time Social Network Analysis does not analyze only the data relations between all the above entities in a specific claim process, but also the relations with past transactions, with claims that happened in the past, past data which hold significant information for the claims fraud detection process. If a new claim looks high legitimate and everything is normal, this does not mean that actually it is! We have to apply Social Network Analytics in all the history of our claims and data, if there is a relation of a claims entity (e.g. a telephone number or address) with a past fraud case of an identified fraud ring, then this triggers high suspicious for fraud risk even in this new initial legitimate claim, so thorough review has to be made and possible the claim has to be assigned to a fraud squad for drilling down to every detail. The “devil is in the details” and this is more than true for insurance fraud detection!
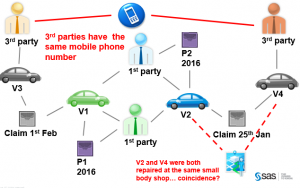
Network Identification
What we have to watch out in order we proceed to robust Network Structures that will assist us the most in fraud detection, is:
- 1st Data Management and Data Quality that we covered in the 1st Blog Post Series article (so we have cleansed and standardized data for names, surnames, IDs, telephone numbers, addresses, VINs etc.) and
- 2nd is to avoid mega clusters meaning huge networks either due to poor data inputs (e.g. the telephone number of a broker instead the policy holder number for 1000 customers) or creation of links that causes such case (e.g. network links based on lawyer or auto body shop or broker or investigator etc.).
For resolving the 1st case we have to analyze the data prior to the network generation process and the insurer to proceed to corrective actions or decide to the exclusion of specific data entities that trigger more issues than they resolve. For the 2nd case we can utilize the visualization of such generic entities in our Networks and visualize even the links, but only for visualization purposes (e.g. doted lines like “soft links”) and not for network generation (“hard links”).
Key message
Tackling unknown fraud with Social Network Analytics is the most important advanced analytics technique in a fraud analytics journey in order to tackle organized fraud gangs. Specialized fraud prevention software needs to include a powerful Network Analytics solution. The insurer should be aware that Network Analytics without the combination of a powerful Data Quality and Data Management software cannot bring value and may cause more issues than resolves. Network entities and links need massive cleansing, standardization, matching and process automation mechanisms before properly utilized. While Anomaly detection can be the first advanced analytics technique for the insurer, the Social Network Analysis can bring more value and has to be the second.
This is the 4th post in a 7-post series, “A practical guide to tackle auto insurance fraud”. This series explores 7 analytics best practices techniques that insurers need to follow for tackling auto insurance claims fraud. Next post deals with the Hybrid Scoring technique, a technique based on business expertise and analytics, in order to combine the fraud risk score from each one of the fraud detection techniques that we analyzed in previous articles and produce an overall fraud risk score for every claim and every network.
For a deeper insight, don’t miss to watch the on-demand Insurance Fraud webinar series that were completed on September.

1 Comment
Pingback: A practical guide for auto insurance fraud – Opening Welcome - Bright Da