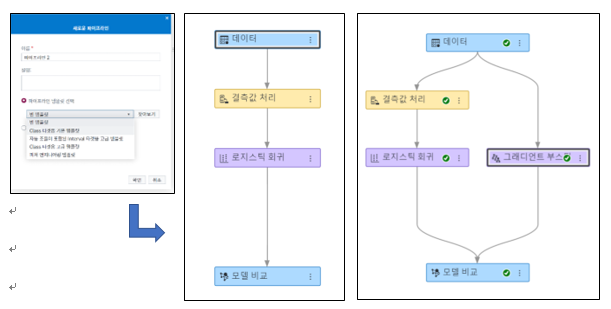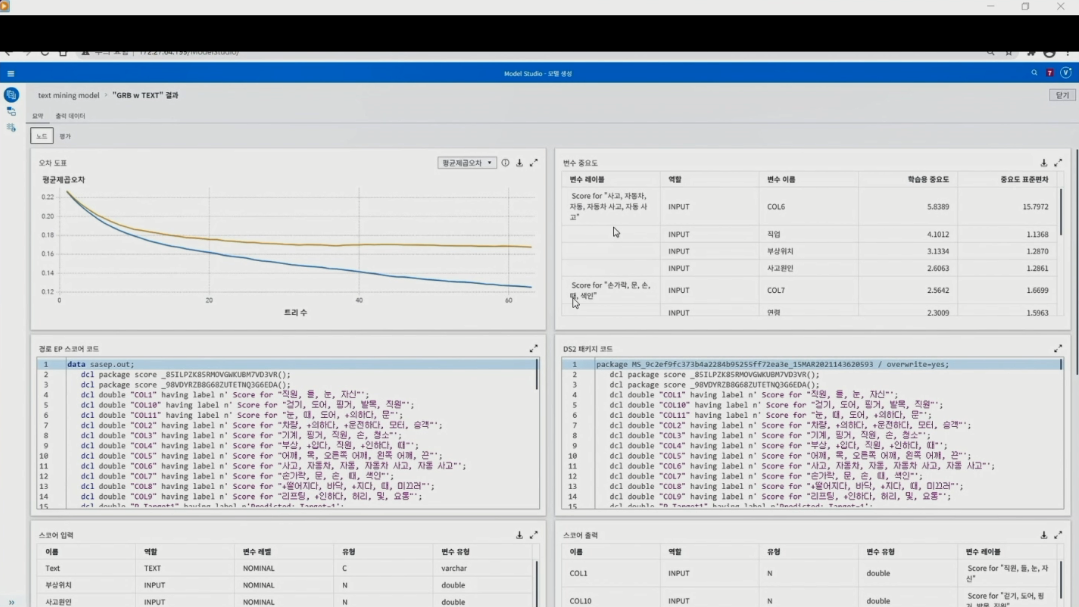
텍스트 데이터로 모델 성능 높이는 꿀팁

최근 화두가 되는 빅데이터와 머신 러닝은 예측 모델의 성능을 올리기 위한 방안으로 시작된 것입니다. SAS VDMML(Visual Data Mining and Machine Learning)은 예측 모델 개발 시 텍스트 데이터를 이용하여 모델의 성능을 높여주는 텍스트 분석 툴로, 비즈니스 사용자와 데이터 사이언티스트, 예측 모델 개발자 모두가 활용할 수 있습니다. 텍스트 분석은 자연어 처리 과정이