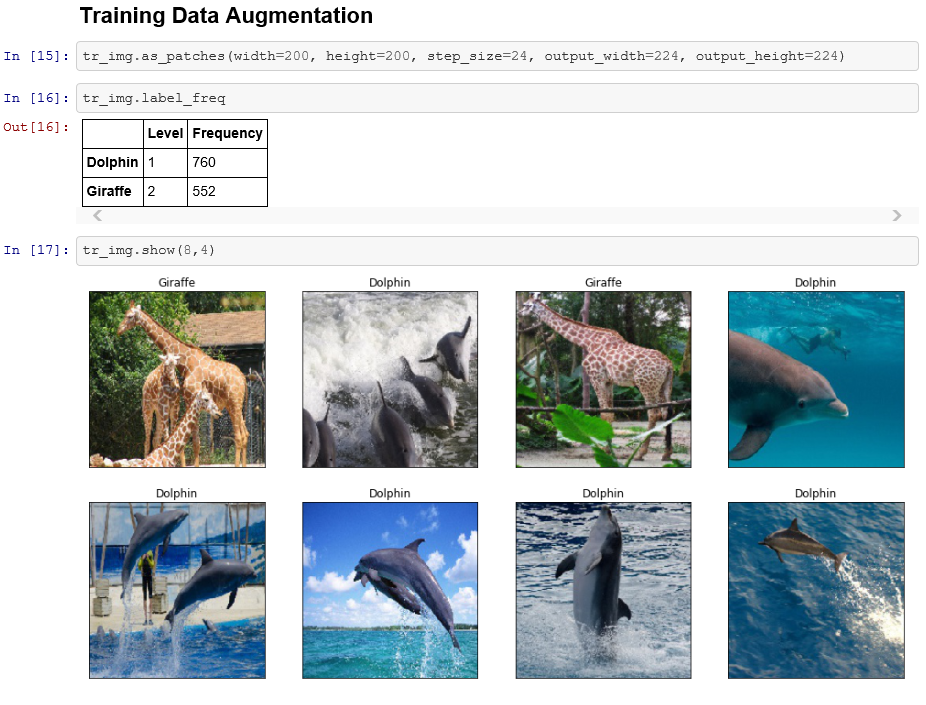
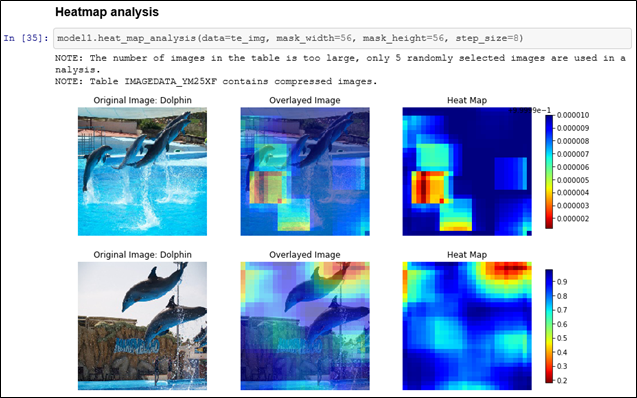
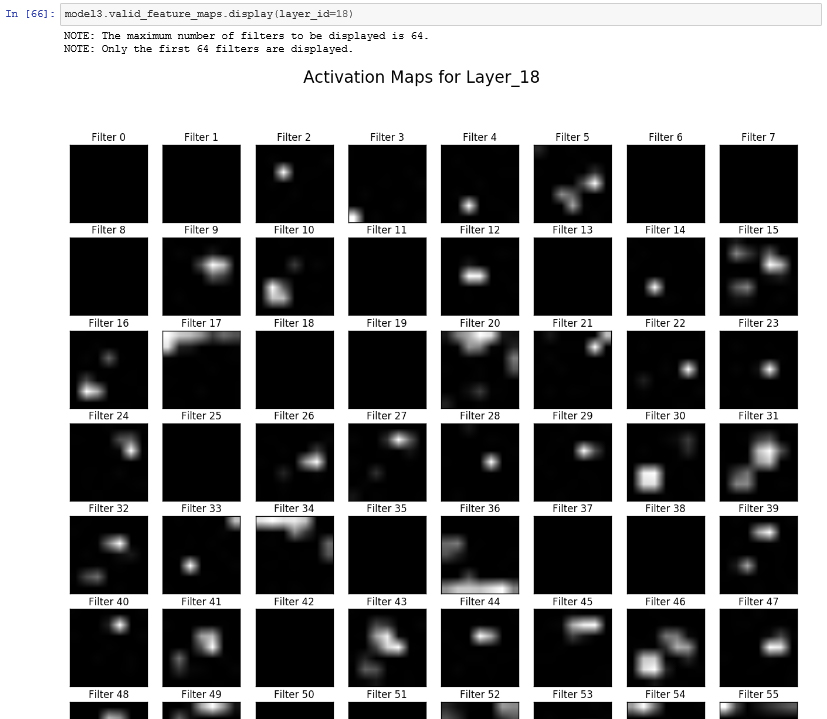
SAS Viya:ディープラーニング&画像処理用Python API向けパッケージ:DLPy
SASでは、従来からSAS Viyaの機能をPythonなど各種汎用プログラミング言語から利用するためのパッケージであるSWATを提供していました。 これに加え、よりハイレベルなPython向けAPIパッケージであるDLPyの提供も開始され、PythonからViyaの機能をより効率的に活用することが可能となっています。 ※DLPyの詳細に関しては以下サイトをご覧ください。 https://github.com/sassoftware/python-dlpy DLPyとは DLPyの機能(一部抜粋) 1.DLPyとは DLPyは、Viya3.3以降のディープラーニングと画像処理(image action set)のために作成された、Python API向けハイレベルパッケージです。DLPyではKerasに似たAPIを提供し、ディープラーニングと画像処理のコーディングの効率化が図られています。既存のKerasのコードをほんの少し書き換えるだけで、SAS Viya上でその処理を実行させることも可能になります。 例えば、以下はCNNの層の定義例です。Kerasに酷似していることがわかります。 DLPyでサポートしているレイヤは、InputLayer, Conv2d, Pooling, Dense, Recurrent, BN, Res, Proj, OutputLayer、です。 以下は学習時の記述例です。 2.DLPyの機能(一部抜粋) 複数のイルカとキリンの画像をCNNによって学習し、そのモデルにテスト画像を当てはめて予測する内容を例に、DLPyの機能(一部抜粋)を紹介します。 2-1.メジャーなディープラーニング・ネットワークの実装 DLPyでは、事前に構築された以下のディープラーニングモデルを提供しています。 VGG11/13/16/19、 ResNet34/50/101/152、 wide_resnet、 dense_net また、以下のモデルでは、ImageNetのデータを使用した事前学習済みのweightsも提供(このweightsは転移学習によって独自のタスクに利用可能)しています。 VGG16、VGG19、ResNet50、ResNet101、ResNet152 以下は、ResNet50の事前学習済みのweightsを転移している例です。 2-2.CNNの判断根拠情報 heat_map_analysis()メソッドを使用し、画像の何処に着目したのかをカラフルなヒートマップとして出力し、確認することができます。 また、get_feature_maps()メソッドを使用し、CNNの各層の特徴マップ(feature map)を取得し、feature_maps.display()メソッドを使用し、取得されたfeature mapの層を指定して表示し、確認することもできます。 以下は、レイヤー1のfeature mapの出力結果です。 以下は、レイヤー18のfeature mapの出力結果です。 2-3.ディープラーニング&画像処理関連タスク支援機能 2-3-1.resize()メソッド:画像データのリサイズ 2-3-2.as_patches()メソッド:画像データ拡張(元画像からパッチを生成) 2-3-3.two_way_split()メソッド:データ分割(学習、テスト) 2-3-4.plot_network()メソッド:定義したディープラーニングの層(ネットワーク)の構造をグラフィカルな図として描画 2-3-5.plot_training_history()メソッド:反復学習の履歴表示