To optimize a Structured Query Language (SQL), the database professional must befriend this order and perhaps even embrace it.
Who is your best friend? I’m talking about the order in which SQL processes your statements. Simply put, in what order does SQL do your work? (From my previous post you know another SQL rule, the order in which YOU submit statements to SQL.) I just want us to be clear that these are two very different orders.
First up, what makes SQL different from other programming languages? It’s the way SQL processes code. Most programming languages including SAS start at the top of your code and make their way to the bottom. However, SQL processes them in a unique order, known as Logical Query Processing Phase. This phase (also referred to as a clause) generates a series of virtual tables with each virtual table feeding into the next clause or phase. And no, we can’t view these virtual tables, sorry about that. That’s just the way SQL works!
When I shared the processing order with my recent SQL1 class, Lindsay Jacks of Cancer Care Ontario asked if I would blog about it. I hope this sharing will help breakdown any surprises you may expect to see when you submit SAS code. And in turn help in understanding how to optimize SQL queries.
Here then is the logical query processing phase order.
1. FROM
The 1st clause SQL processes is the FROM. It tells SQL where to grab your tables from. Given that this clause is the first to execute, it’s also our first chance to boil down your table sizes. From an efficiency perspective, this is why we may need to think about putting as many ON clauses as possible on JOINs versus putting them on the WHERE clause.
2. WHERE
The 2nd clause SQL processes is the WHERE. The WHERE clause pre-processes data. It selects just the rows that meet the WHERE criteria. The results of WHERE clause processing are stored in an intermediate table.
SQL coders who have sometimes been surprised to see the WHERE clause fail may now have their answer. In the example that follows, the WHERE has no idea how to filter Bonus and doesn’t know what Bonus means. Just because we constructed Bonus on the SELECT doesn’t mean anything to the WHERE as the SELECT is one of the last clauses in the processing order & yet to be looked at by SQL. Consider the following example where the Log rightly complains:
43 /* Try to subset by referencing a new column with its alias */ 44 proc sql; 45 select Employee_ID, Employee_Gender, Salary, 46 Salary * .10 as Bonus 47 from orion.Employee_payroll 48 where Bonus < 3000; ERROR: The following columns were not found in the contributing tables: Bonus. 49 quit; NOTE: The SAS System stopped processing this step because of errors. NOTE: PROCEDURE SQL used (Total process time): real time 0.01 seconds cpu time 0.01 seconds |
3. GROUP BY
The 3rd clause SQL processes is the GROUP BY. The role of the GROUP BY is to get your data into groups. To do this grouping, sometimes SQL may need to order your data, but there’s no guarantee that data will be in ascending or descending order. Explicitly placing an ORDER BY clause is our only guarantee that data will be in order.
4. HAVING
The 4th clause SQL processes is the HAVING. This clause subsets the groups created by the GROUP BY clause based on the HAVING clause predicates, and, like the WHERE clause, builds an intermediate table.
5. SELECT
The 5th clause SQL processes is the SELECT. This is what tells SQL what columns to pull into the query, existing or calculated. Note: Columns are calculated on the SELECT only one time regardless of how often they are referenced, whether on the WHERE (with the calculated keyword) or the ORDER BY (without the calculated keyword). The SELECT statement is able to use the results of anything it calculated in other instances using the same calculation.
6. ORDER BY
The 6th clause SQL processes is the ORDER BY. By now it should come as no surprise that the ORDER BY has access to columns created on the SELECT but the WHERE doesn’t (see 2 above to as a reminder).
Any earlier confusion about the calculated SELECT columns (see 2 again) not being available in the WHERE clause, but available in the ORDER BY clause would now make perfect sense. Because the SELECT is executed before the ORDER BY, all columns in the SELECT will be available at the time of ORDER BY execution. So the following code works perfectly:
68 proc sql; 69 select Employee_ID, Employee_Gender, salary, 70 Salary * .10 as Bonus 71 from orion.Employee_payroll 72 order by 4; 73 quit; NOTE: PROCEDURE SQL used (Total process time): real time 0.03 seconds cpu time 0.03 seconds |
Itzik Ben-Gan makes a good point with a poster that captures the processing order.
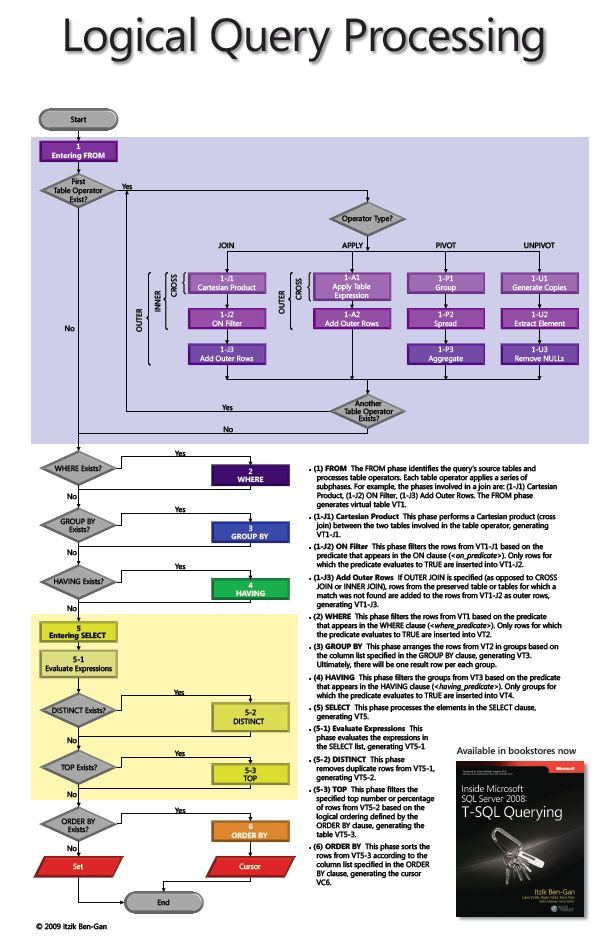
Why do I call this processing order your best friend in the database world? Because we have likely at some time come across never ending queries and not known how to optimize. Here then is a starting point for us to try to keep in mind next time we submit a query, so we can modify the way we optimize SQL queries.
As I wrap up this post, I realized I sort of exhausted my creativity in writing this actual post J and didn’t have the energy to think up a mnemonic like the earlier one of So Few Workers Go Home On Time. Can you think up one for the processing order? I’d love to hear your thoughts.



11 Comments
Hi Charu,
Thanks for the info,
I have a doubt regarding Where clause vs Where option used with From clause. I tried implementing this and found the later one is much faster compared to Where clause.
Example:
Proc sql;
Create table a as select age from sasuser.admit where age gt 30;
create table b as select age from sasuser.admit(where= (age gt 30));
quit;
What u say- which one is more efficient? What's the diff between the two queries in terms of processing?
Hi Charu,
thank you for an informative article. A small hint, to clarify your point, why not use this sql in your ex:
proc sql;
select Employee_ID, Employee_Gender, salary,
Salary * .10 as Bonus
from orion.Employee_payroll
order by Bonus;
quit;
(Bonus in stead of '4')
thanks Claus for the optional method. We can certainly say order by Bonus. But since I'm a lazy programmer & keep looking for ways & means to reduce typing.. I used the column position way.. instead :)
Fired
Workers
Go
Home
So
Outraged
Haha! thanks Alan..
Hi,
I think this summary is not complete.
What about joins and the "on"-clauses?
As far as I know the "on"-clauses and the joins are processed before the "where"-clauses.
When performing outer joins you might get unexpected results if you have a "where"-clause that refers to a variable of the non outer table and there is no matching with the joined tables.
Regards
Andreas
you're right about the ON Andreas.. that's why you;ll notice I put that down in the 1st clause, the FROM in this blog post. "From an efficiency perspective, this is why we may need to think about putting as many ON clauses as possible on JOINs versus putting them on the WHERE clause.". To your 2nd point, as you might appreciate it would be quite challenging to address every single user's query in a single post..so this post focuses on the default processing order. Stay tuned for follow up posts.
hi.
there is something i can't understand from your explanation.
suppose you have a Case When sentence in the Select clause with an alias.
if i repeat the Case When sentence in the Group By clause, the Group By clause has no effect and i got as many registers as without the Group By.
in the other hand, if i use the alias in the Group By clause, i have the desired results.
but, at the Group By processing time the Case When alias is not known ...
i can't understand this behavior :-(
Hi Juan, thanks for your comment. Yes, SQL can be puzzling behind the covers. The logical processing order provided in this post is the default order. Here's a tip from my fellow instructor Linda Jolley: When there are calculated columns used on WHERE, HAVING, or GROUP BY clauses, that changes the default order.
So for your query, the order would be:
proc sql;
select ...2
from ...1
group ... 3
The SQL planner takes care of all that under the covers. You should be able to see what gets done with the _method option on your PROC SQL statement. I'm not sure that it will give you the full level of detail, but it does help,to figure out how things get processed. :-)
Favorite
Words
Give
Highly
Simple
Output
Thanks Jerry for a great acronym. I might share that with my next class if that's ok with you..