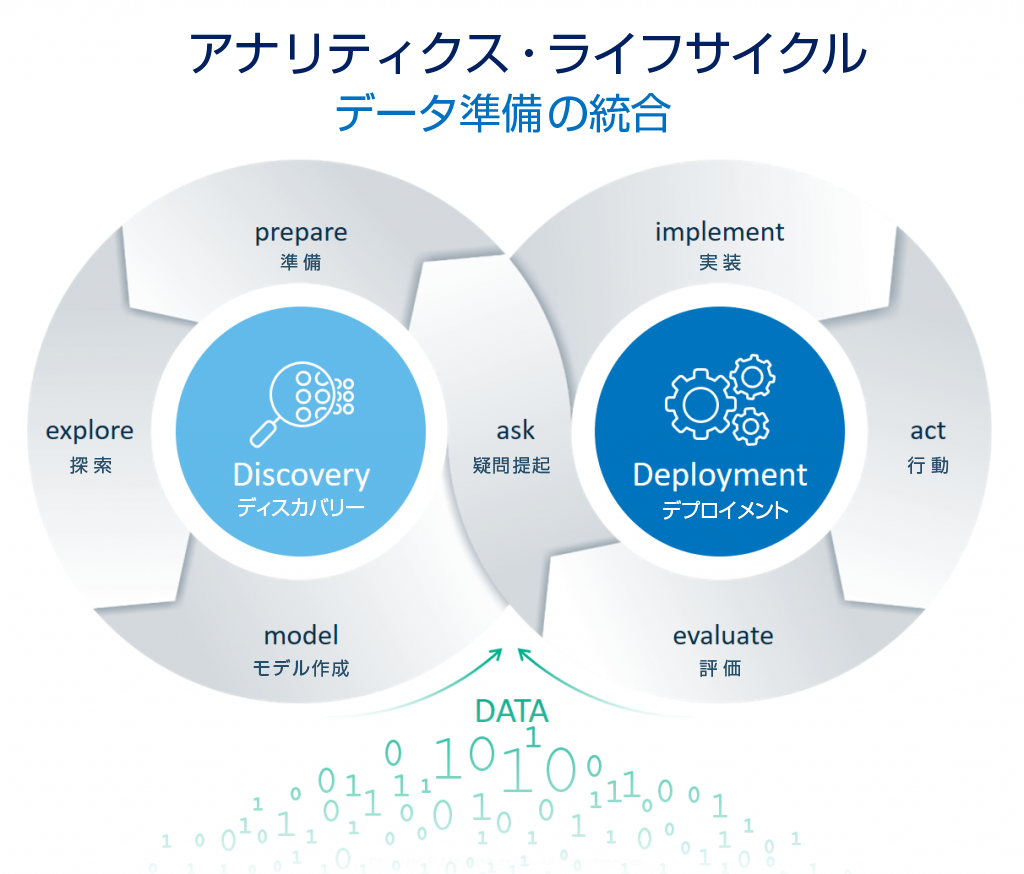
ようこそ古くて新しいデータマネージメントの世界へ 2023年、DMBOK(データマネージメントの知識体系を網羅的にまとめたもの)という用語を改めて聞く機会が多くなりました。おそらくこれはアナリティクス(データ分析に基づくより良い意思決定の実践)の近年のブームで、新たにアナリティクス活用に踏み出し、ようやくビジネスに直結する使い方をするようになった企業・組織があらためてデータマネージメントの重要性に気付き始めたからだろうと推察します。 また一方で、クラウドシフトに伴いクラウドストレージの活用とともに、これまで蓄積していなかったデータを蓄積し始めたり、これまでのデータウェアハウスを一新する形で、データレイク/データウェアハウスを再構築するなど、従来からアナリティクスを活用していた企業もまた同様に、データマネージメントについて改めて考えているようです。 20年以上前からアナリティクスを競争優位の源泉としていた企業では、データマネージメントが大きな一つの関心ごとでした。その後、テクノロジーの進化によって、ソースデータのビッグデータ化(Volume, Variety and Velocity)や、ストレージ技術の進化、そしてアナリティクス・プラットフォームの進化によってITシステムに対するビジネスニーズも変化しました。また、消費者市場の変化や、データサイエンス人材の爆発的な増加といった市場の変化も目覚ましいものがあります。このような変化の中、近年あらたにアナリティクスの活用に踏み出しはじめた多くの企業だけでなく、従来、競争優位の源泉にしてきた高成熟度企業においても、データマネージメントの課題への遭遇と解決にむけて取り組んでいます。 いきなりですが、もっとも頻繁にお伺いする課題について 過去も今もお客様から聞く課題で最も多いのは、「作ったけど使われないデータウェアハウスやデータマート」です。そもそも、使われる/使われないというクライテリアそのものをもう少し注意深く定義する必要はあるとは思いますが、ITシステム部門主導で利用目的をないがしろにしたデータ基盤構築プロジェクトは往々にしてそのような結果になるようです。例えば、ITシステムサイドの都合で蓄積データの種類・期間や粒度を決めてしまうことで、データ分析要件を満たさないという結果になったり、データの出自や性質・品質や使い方のガイドがないために、データはそこにちゃんとあるのにユーザーから利用を敬遠され、別の独自のデータが作り出されたり、作成の要求が来たりしてしまいます。本ブログでは、このような結果に陥らないために意識すると良いと思われることをお伝えしていきます。 もっとも簡略化したデータマネージメントの歴史 アナリティクスに特化したデータマネージメント考察の第一期ーHadoopの到来 2015年以前はダッシュボードや定型レポート、一部の大規模なデータ分析処理用にRDBMSやデータベースアプライアンスが構えられるのみで、アナリティクス用途としてはSASデータセットやフラットファイルでの運用が主でした。これはアナリティクス的なデータ加工および統計解析・機械学習ワークロードに適したテクノロジーが世のなかにはあまりなかったからです。Hadoopの登場により、アナリティクス用途でのデータ活用が一気に拡大し、パフォーマンスやスケーラビリティの制約から解放されました。一方で、従来のように目的を先に決めてデータマートを先に設計してという方法では、アナリティクスによる効果創出が最大化されないという課題も見えてきました。このHadoopの登場は、アナリティクスのためのデータマネージメントの変革の最初のタイミングだったと思います。詳しくは2015の筆者のブログをご興味があればご参照ください。 アナリティクスの効果を最大化するデータマネージメント勘所 Hadoopだからこそ必要なセルフサービス-そしてアダプティブ・データマネジメントの時代へ データマネージメント第二期ークラウドデータベースへのシフト 2015年以降のAIブームによりアナリティクス市場が一気に拡大するとともに、アナリティクスをビジネス上の収益向上、コスト削減、リスク管理に役立てている企業では、データマネージメントの話題が再熱しています。不思議なのは、いや、多くの企業の機能別組織構造では仕方ないのですが、アナリティクスのために良かれと思って取り組んでいるデータマネージメントの課題は、多くのケースで、最終的にアナリティクスを活用して企業の経営に役立てるという目的が忘れ去られてしまいます。 そもそも、アナリティクスのためのデータマネージメントの目的 ともすると手段が目的化しがちなのがITシステムのプロジェクトです。まず、アナリティクスのためのデータマネージメントに何が求められているかを改めて掲げてみますが、そのまえに、そもそもデータマネージメントが課題になるのは、なぜでしょうか? ここでは昔も今もその構図が変わっていない世のなかの状況について共有します。 なぜ、データマネージメントタスクに80%も費やしていのでしょうか。ビジネスにおけるデータ分析の多くは、そもそも実験計画やマーケティング調査とは異なり目的に対してデータを生成・収集しているわけではありません。多くのケースでは、目的に対してそもそもその目的用に計画したわけではないが入手可能なデータを無理やり当てはめています。この目的と手段のギャップを埋める作業が非常に多くの時間とコストを要します。たとえば以下の例で考えてみてください。 製造業において生産設備の中の状態を正確に理解したいが、技術的・コスト的な制約で限定的な精度のセンサーを限定的な場所に設置して、状態の一部を前提条件付きで収集したデータを使うしかない 顧客の購買ニーズを知りたいのだが、店舗ごとの実験は難しいので、欠品情報や潜在的なニーズが表現されていない、過去の活動の結果というバイアス付きのPOSデータを使うしかない このように目的外で収集されたデータを、ある特定の目的のために使えるように評価・加工しなければいけないので、多くの時間をこのデータ準備に割く必要が生じてきます。 では、データマネージメントの取り組みはどこを目指せば良いでしょうか?データ分析者のため、を考えると必然的に以下のポイントが浮かび上がります。 目的に沿ったデータを準備すること データ分析による意思決定において、社会的責任とビジネス上の意思決定の精度を高めるため、品質を担保し、バイアスを理解し、データの生成過程(入力バイアスや基幹システム仕様と業務ルール)を理解し、適切な利用方法を確認する SQLだけでは非生産的な自由自在なデータ加工 データはその利用手法すなわち、統計解析、機械学習、ディープラーニング、自然言語解析、画像解析などによって、手法や使用ツールの仕様に応じて、また、処理パフォーマンスの観点も含めて、自由自在に加工する必要がある ビジネススピードを阻害しないパフォーマンスや処理時間 アナリティクスを競争優位に活用している企業では、24/365常に様々なデータ加工処理が、バッチ、リアルタイム、オンラインで実行されている。これら様々なワークロードを優先度とコスト効率よく、ITシステム部門が特別なチューニングやスケジューリングや、エラーによる再実行をしなくとも、業務スピードに合わせたパフォーマンスで、安定して実行可能な基盤が不可欠 データマネージメントの取り組みで失敗に陥りやすい行動 前述の目的を簡単に言い換えると、データ分析者が何か課題を解決したいと思ってからがスタートで、そこからいかに短時間で正しいデータを特定し、評価し、加工して目的の形に持っていくかが大事であるということになります。つまり、データを物理的にどこに配置されているかに関わらず、データへのアクセス性、評価や加工の俊敏性などが需要であることになります。また、その理解に基づくと、以下のような取り組みはデータマネージメントの目的に沿っておらず、俊敏性や正確性、拡張性を損なう「硬直化」の原因になっていることが多く見うけられます。 「データ統合」を目的化してしまう 1つのデータベースに格納するデータの範囲を決めようとする 汎用的なデータモデルを設計しようとする 変化を前提としないマスタデータ統合をしようとする 変化し続けるビジネス状況のなか、管理対象のデータは常に変化し続けるため、これが「完成」というゴール設定での取り組みは、破綻します。ある大手製造業では何十年にもわたり「ある一つの固定的なゴール」を目指したマスタデータの整備を続けた結果ようやく「マスタデータは時代とビジネスに合わせて常に変化する」と気づき、当初のプロジェクトをストップさせた、という事例もあります。また、取得可能なデータはテクノロジーの進化によって変わります。後で使うかもしれないからと「念のため」蓄積を開始したデータであっても、5年後には使い物にならないデータかもしれません。 「データマートを整備」しようとする スナップショット的なニーズに対応するデータマートを作ろうとする 目的別データマートは目的ごとに存在するにもかかわらず、データマートが多数あることを問題視してしまう データマートの品質(正確性、一貫性、説明性)を気にしていない データマートを固定化するということは目的を固定化することに他なりません。一方でデータ分析を広めるということは、より多くの異なる目的に対してデータ分析を実践することで、矛盾しています。データマートが散在しているという課題感は、本質的にはデータマートがたくさんあることが問題なのではなく、そこでどのようなデータ分析が行われているのか、その品質すなわち、正確性・一貫性・説明性のガバナンスが効いてないことにあります。この本質的な課題解決は別の手段で解決すべきです。 「データ・ディクショナリを整備」しようとする データ分析者にとって良かれと思いITシステム側でスナップショット的なメタデータを定義する データ基盤開発初期にのみ、データ分析者からヒアリングしてメタデータを定義する データの出自、仕様、生成元の情報、使い方、品質、評価などの情報が管理されていない データ・ディクショナリを作ったけどデータ分析者にとって有用な情報が定義されていなかったり、継続的なメンテナンスがされなかったりすることがほとんどです。データ・ディクショナリの目的は、データ分析者により迅速にデータを特定・評価・利用してもらうことなので、その目的達成のためには、より有用な情報を異なる方法で蓄積・管理するべきです。 データマネージメント課題の解決の視点は、自由と統制 原理・原則および、網羅的な知識体系はDMBOKに体系的にまとめられているのでそれは頭に入れてください。そのうえで、データ分析によるビジネス価値創出のための、筆者の経験に基づくデータマネージメント課題の解決のためには、自由と統制のバランスをとることだと考えます。これにより、従来、繰り返しているデータマネージメントの失敗を乗り越え、自己組織的に育つ企業・組織のデータ分析文化の醸成にようやく一歩を踏み出せることになります。 データ分析者の自由度を最大化する(ITシステム部門がボトルネックにならないようにする) あらゆるデータソースに自由にアクセスできるようにする。データの種類や利用目的によって最適なデータ格納方法は変わる。どのような形式でデータが格納されていてもデータ分析ツールから自由にアクセスできるようにすることが重要