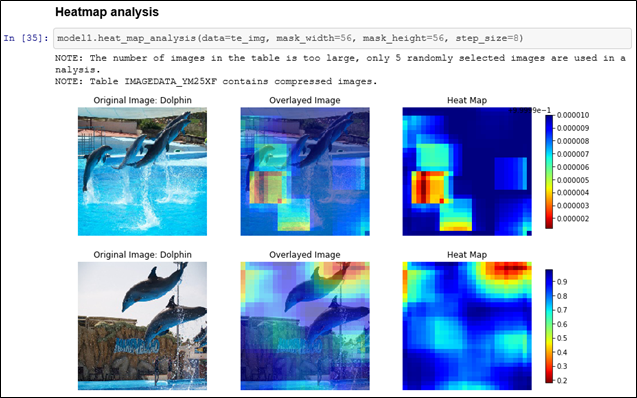
ディープラーニング&画像処理用Python API向けパッケージ:DLPyでは、DLPyの基本的な機能を紹介しました。その中で、ディープラーニングの判断根拠となり得る情報、つまり入力画像のどこに着目しているのかをカラフルなヒートマップとして出力することができるheat_map_analysis()メソッドに触れました。 今回は、heat_map_analysis()メソッドを使用して、ヒートマップを出力する際に指定可能な有効なオプションに関していくつか紹介します。 GPU活用 ヒートマップ解析時の判別(予測)処理再実行回避 ヒートマップ出力対象画像タイプ(正・誤判別)指定 ヒートマップ出力対象画像指定 1.GPU活用 SAS Viyaのディープラーニングでは、ネットワークの層ごとにGPUを使用するかどうかの指定が可能ですが、ヒートマップを出力する際にも、指定したテストデータをモデルに当てはめての予測処理は実行されることになるので、同様にGPUを使用することが可能です。 GPUを使用することで、ヒートマップ出力の時間を短縮することができます。 2.ヒートマップ解析時の判別(予測)処理再実行回避 最初にheat_map_analysis()メソッドを実行する際には、モデルにテストデータを当てはめて判別(予測)処理が行われますが、以降、heat_map_analysis()メソッドを使用して、必要な判断根拠情報を再出力する際には、最初の実行時に計算された値を再利用するので、都度再計算(判別・予測処理)は行わず、より効率的、迅速に、ヒートマップを出力することができます。 「1.GPU活用」でのheat_map_analysis()メソッドではパラメータとして「data=te_img」が指定され、モデルにテストデータを当てはめていましたが、下記の再実行の例では、このパラメータは指定されず、結果のメッセージにも「Using results from model.predict()」と、実行済みの計算結果が使用されている旨が表示されています。 3.ヒートマップ出力対象画像タイプ(正・誤判別)指定 ディープラーニングのモデルにテストデータを当てはめて判別(予測)した結果として、正しく判定された画像と間違った判定が下された画像があります。 heat_map_analysis()メソッドの「img_type」パラメータを使用し、正:”C”(Correct Classification), 誤:“M”(Miss Classified), すべて:“A”(All)、を指定して該当画像の判断根拠情報を出力することが可能です。 以下は、誤判別された画像(img_type=‘M’)の判断根拠情報出力例です。 画像のどの部分に着目して、間違った判断に至ったのかを確認することができるので、モデル精度を改善するためには、学習用にどのような画像が必要なのかといった、示唆も与えてくれます。 4.ヒートマップ出力対象画像指定 heat_map_analysis()メソッドの「filename / image_id」パラメータを使用し、特定の画像を指定して、出力することも可能です。 以下は、画像ファイルリストの上位2つの画像のヒートマップをファイル名指定で出力している例です。 以下は、画像ファイルリストの先頭の画像のヒートマップをID指定で出力している例です。 上記例の詳細に関しては、こちらのGitfubサイトをご覧ください。 DLPyの詳細に関しては、こちらのGithubサイトをご覧ください。