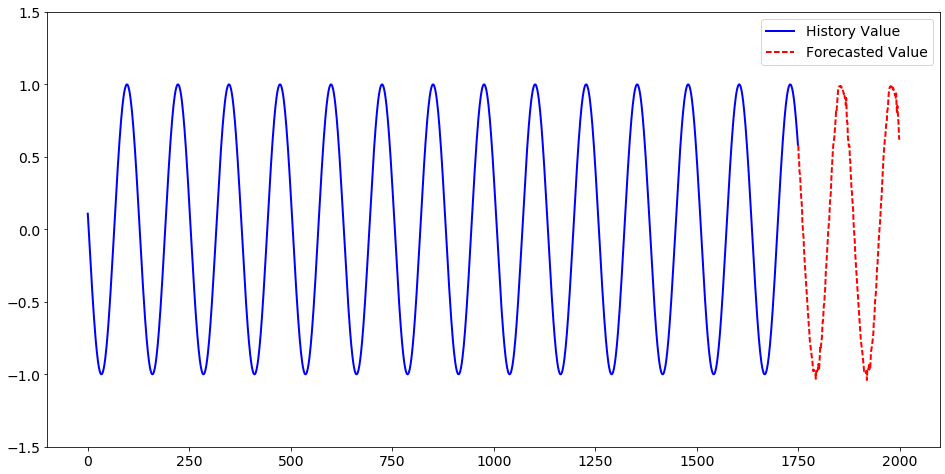
SAS Viya:RNNでsin波を予測してみた

PythonからSAS Viyaの機能を利用するための基本パッケージであるSWATと、よりハイレベルなPython向けAPIパッケージであるDLPyを使用して、Jupyter NotebookからPythonでSAS Viyaのディープラーニング機能を使用した時系列予測を試してみました。 大まかな処理の流れは以下の通りです。 1.必要なパッケージ(ライブラリ)のインポート 2.Sin波データの生成 3.セッションの作成 4.RNN向け時系列データセットの作成 5.モデル構造の定義 6.モデル生成(学習) 7.予測 1.必要なパッケージ(ライブラリ)のインポート swatやdlpyなど、必要なパッケージをインポートします。 import numpy as np import pandas as pd import matplotlib.pyplot as plt import swat.cas.datamsghandlers as dmh from swat import * import dlpy from dlpy import Sequential from dlpy.layers import * from dlpy.model import Optimizer, AdamSolver, Sequence