
Authors: William Nadolski and David Weik
Although large language models (LLMs) dominated the spotlight in 2024, this post aims to shed light on other exciting developments that have largely flown under the radar. We'll explore what makes transformers so unique. We'll also share how they've become the go-to tool for almost any type of data and why they are preferred over other model architectures. In future posts, we'll delve into various task-specific transformer and foundation models that extend beyond the well-known LLM applications.
What is a Transformer Model?
You’ve likely heard the buzz around transformer models if you're into AI. They’re the rock stars of machine learning right now, powering large language models such as ChatGPT. These models, built initially to handle text, are now flexing their muscles across various data types. Think images, audio, time series, and even more complex, mixed data types. They're so versatile that they can handle nearly anything you throw at them, and that’s precisely why they're everywhere today.
We’ll start with a brief technical explanation before providing more intuitive examples. At a basic level, transformers take an input sequence; let’s use an example of a string of words, such as a sentence. The model takes that sentence and first tokenizes the words by splitting them into sub-word groups of characters known as tokens. Those tokens are then converted into numeric vectors by using a process known as embedding. Those input embeddings are then used to recursively predict the next most likely set of tokens based on the knowledge the model has been pre-trained against. A visual representation of the transformer model architecture is provided in Figure 1 (Image source: Vaswani et al., 2017).
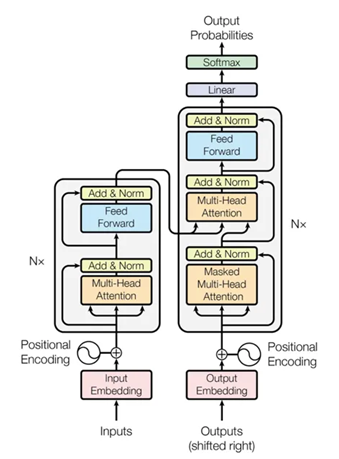
What’s the big deal with transformers?
The transformer model started as a solution to a problem that every machine learning enthusiast faces, prediction. However, unlike traditional machine learning models, which focus on predicting an individual data point, researchers were instead interested in predicting sequences of data points. You see, sequences—like words in a sentence or pixels in an image—are tricky. How does a model know the appropriate length of an input sequence? Which specific subsequences within that input sequence are relevant, and which are not? How does it correlate subsequences from one input against subsequences from another input with differing offsets?
Models like recurrent neural networks (RNNs) tried to process sequences one step at a time. However, they were slow (due to sequential processing) and struggled to capture long-range dependencies (due to vanishing gradients). Think of trying to remember the beginning of a sentence after reading a long paragraph.
Enter the transformer. Imagine trying to read a whole book at once and picking out all the connections between paragraphs, sentences, and words in one go. It would be difficult, to say the least. That’s where self-attention comes into play, the mechanism within the transformer model architecture that allows it to understand what is essential and what is not. This enables the model to discern significant patterns (signals) from unhelpful details (noise) on its own without being instructed on what is relevant to the task at hand.
Self-attention is the secret sauce that differentiates transformer models from the other available deep learning architectures. At the risk of oversimplifying things, it takes as input token embeddings and computes a Query-Key-Value (QKV) cache, which is learned during model training. This QKV cache is then used as a sort of quasi-lookup table during processing where Q is the input token embedding vector, K is a measure of relevancy, and V is the value to be passed to the next layer of the model. For a more in-depth explanation, please refer to this excellent 3Blue1Brown: Attention in Transformers video.
How transformers became masters of text
It all started with text. When transformers entered the scene, they blew existing approaches, such as RNNs and Long Short-Term Memory (LSTMs), out of the water. Instead of processing words one at a time (like the aforementioned models), transformers look at the whole input sequence at once. As a result, they can capture long-range dependencies and context. For example, understanding how the word “bank” in the sentence “I went to the bank to deposit money” might be different from “I went to the bank to fish.”
Imagine reading a book with multiple storylines running in parallel. So, instead of going back to the beginning of each chapter to understand the context, transformers can effortlessly track all storylines at once and weave them together. They track and “know” whether specific tokens (words) attend to entities at the input sequence's beginning, middle, or end and can infer context based on that relative position. This ability has made transformers the backbone of natural language processing (NLP) tasks like translation and summarization and even more complex tasks like generative writing.
Transformers: The multimodal magic trick
Here’s the kicker: transformers don’t just process one type of data—they can work with anything. Text? Sure. Images? You bet. Audio? Absolutely. Time series data? You’re in luck. Transformers are flexible like a Swiss army knife, capable of handling any challenge that comes their way.
Transformers can even juggle different types of input data at the same time. It's like watching someone read a book, listen to music, and process images simultaneously. There is no need to limit yourself to just one type of input data. The possibilities unlocked by this capability are tremendous. A data scientist no longer needs to determine which specific data format is most relevant. Now, they can feed the transformer multiple input data streams (images, text, audio, etc.) and allow it to determine which type is most important. It can also figure out the significant inter-dependencies between these various data modalities.
Transformers may have been initially created to process text data, but they are now proving their usefulness across a wide range of applications and use cases.
What is a “foundation model”?
Before we conclude, let’s return to the term “foundation model.” It is essentially a large-scale, pre-trained model that serves as a general-purpose basis for various downstream tasks. These models are typically trained on vast amounts of data by using self-supervised learning. They can also be fine-tuned or adapted for specific applications.
For example, think of LLMs. To utilize an LLM like ChatGPT, you don’t need to train the model on its specific task or use case. It can simply use the existing model and get relatively good results “out of the box.” This contrasts with traditional machine learning models, which almost always need to be initially tuned against training data to produce useful and accurate results. The act of tuning a model is often a difficult and expensive endeavor. It requires skilled users not only to collect or generate large amounts of data but also to annotate it and curate a set of training and validation data, which is then used to calibrate the model.
That’s not to say that retraining a model (even a foundation model) is not valuable. Properly fine-tuning a model can help significantly with instructing it on handling edge cases unique to your specific task and tailoring the output to your specific needs. This often results in better accuracy and reliability. However, the emergence of foundation models offers a sort of middle-ground option in the form of “few-shot” and “zero-shot” learning.
“Few-shot” learning refers to the practice of providing the model with a small number of examples in addition to the query prompt to be evaluated. It basically helps to guide the model in producing a response that adheres to the examples provided. The benefit is that it provides the ability to influence model output without having to undertake the efforts needed to fine-tune or retrain the model formally.
What about "zero-shot" models?
Additionally, a new type of model has recently emerged, known as a “zero-shot” model. Zero-shot models allow you to define your target outcome labels on the fly dynamically. Users are no longer constrained to only the set of labels the model was trained on. They are free to specify their desired labels while scoring without additional training! This is equivalent to an archer hitting a target while blindfolded and placed in an entirely new environment.

In machine learning, the term "zero-shot" refers to a model’s ability to perform a task without having been explicitly trained for that exact task. Machine learning models are typically trained on vast amounts of data labeled for specific tasks by using pre-defined labels. For example, imagine if you were to try to identify the presence of turtles by using a traditional computer vision model that was only trained to recognize dogs and cats. It would, at best, fail miserably (producing predictions with low accuracy) if not refuse to try completely (produce errors). In contrast, zero-shot learning allows a model to generalize from knowledge gained during training to handle tasks and outcomes never explicitly seen before. This is based solely on the internal understanding it’s developed between terms and concepts during its pre-training phase.
Imagine if you were handed a new kind of problem at work, one that you had never encountered before. You may not have filled out a 1090 tax form before, but you could apply your pre-existing knowledge and skills from filling out 1040 tax forms to complete the task without much trouble. That’s essentially what zero-shot learning allows models to do. They don’t need specific training on every variation of a task. Instead, they can leverage prior knowledge to adapt to new, unseen situations with impressive accuracy.
This ability makes zero-shot learning incredibly powerful and flexible. It allows models to adapt to a broad range of real-world scenarios with minimal additional data or retraining required.
It is important to note that not all transformer models are zero-shot foundation models, and not all zero-shot foundation models are necessarily transformers. Diffusion models are one example of a non-transformer foundation model. However, foundational models are promising because they can be used as the building block for building entirely new AI-powered applications with minimal calibration required. By using techniques such as transfer learning, prompt engineering, and other sources of feedback, they can be further tweaked and improved with minimal effort. In general, you would also want to embed these models within a process that performs pre- and post-processing. It also adds a layer of business validation to ensure reliable results and conform to best practices.
Summary
This post was the first in a series that will provide an overview of cutting-edge foundation models. It explored the basics of transformer model architecture. It also covered why transformers have become the go-to approach for building capable multi-modal AI models. The next entry in our series will feature William Nadolski. He will provide a practical overview of the Zero-Shot GLiNER model. This model can perform a host of NLP tasks. Tasks include Named Entity Recognition (NER), text classification, and topic extraction without needing pre-training or fine-tuning of the model. Then, David Weik will provide details and examples of using the Segment Anything Model (SAM) model to perform Zero-Shot image segmentation.
If you want to contribute to this series, please get in touch with William Nadolski and David Weik.
