You walk up to your favorite barista to place the usual coffee order, swipe your card or tap your phone, grab the cup of joe, and carry on. Within a fraction of a second, a notification pops up on the phone confirming the transaction.
It is easy to overlook the amount of information processing that has taken place between swiping your card and that first sip. An obvious concern for your credit card issuer is whether it is really you who is about to enjoy that coffee. What is the risk of this transaction being illegitimate?
From an analytical perspective, this boils down to a binary classification problem - fraud or not. Numerous analytical methods can be applied to the problem of supervised classification. These range from straightforward (and explainable) regression-based methods to more complex (and obtuse) deep learning methods. The best choice often depends on a variety of factors. This post describes some of the considerations and recent steps forward utilizing Recurrent Neural Network (RNN) deep learning models to the problem of real-time payment fraud detection.
What is involved in payment fraud modeling?
Real-time payment fraud modeling presents two main challenges: analytical and computational performance. Some of the analytical challenges stem from the fact that fraud can be an extremely rare event. Fraudulent transactions that the system misses (false negatives) carry obvious financial costs. However, flagging legitimate payments (false positives) is experienced as “friction” by the customer.
The goal of fraud modeling is to attain high detection rates while minimizing false positives. Achieving both goals requires domain expertise and a robust suite of potentially predictive features calculated from the raw transactional data. This is where computational performance becomes relevant. It’s not uncommon for analysts to derive tens of thousands of candidate predictors. This requires careful screening for redundancy with one another and relevancy for the prediction. This reduction step pays dividends at the model training stage, of course. However, it also speeds model performance at scoring time; in real-time fraud, time is of the essence.
SAS has been delivering software solutions – namely SAS Fraud Management and SAS Fraud Decisioning – to many global financial institutions since the mid-2000s. SAS’ modeling team has developed a well-established approach to building highly predictive analytical models capitalizing on decades of domain experience in real-time transactional fraud detection. This modeling process is analytically intensive. It demands not only a very talented data scientist but also one with extensive experience in the payments domain. It’s also computationally intensive. Each iteration of model building takes a few weeks for feature generation, screening, and final model fitting. The intermediary data sets consume a lot of storage space as well. Though automation of many steps streamlines the process, some manual steps naturally slow the process and introduce opportunities for errors.
How do we detect payment fraud?
Recent advances in machine learning rendered feature engineering unnecessary in many domains. Examples include Convolutional Neural Networks (CNNs) in computer vision and transformers in large language models. However, in many domains analyzing tabular data, simpler architecture Neural Networks and tree-based algorithms such as Gradient Boosting and Random Forests still dominate the machine learning space. In payments fraud problems, the transactions (data) are in tabular form:
- Input is a set of transactional fields such as the date and time of the transaction, payment amount, merchant information, etc.
- Output is whether a given transaction is fraudulent or not.
The transactions are inherently sequential. That is, for a given payment card/account, the transactions take place chronologically. In our more traditional modeling approach, the sequential nature of the data is accounted for by deriving history profiles for each card/account. More recent approaches in AI/ML, such as recurrent neural networks (RNNs)/transformers for natural language processing, have had great success in dealing with sequence data.
With these in mind, we develop the following approach to detect payment fraud:
- First, create sequence data for the deep learning (DL) model. Each row of data is augmented with data from the previous (n-1) transactions, where n is the number of time steps in the depth of history.
- Second, since the DL model only accepts numeric inputs, the next step is to encode categorical variables into numeric ones. If a categorical variable has a small number of distinct values, an approach such as one-hot encoding can handle them; a large number of categories might necessitate a different encoding approach.
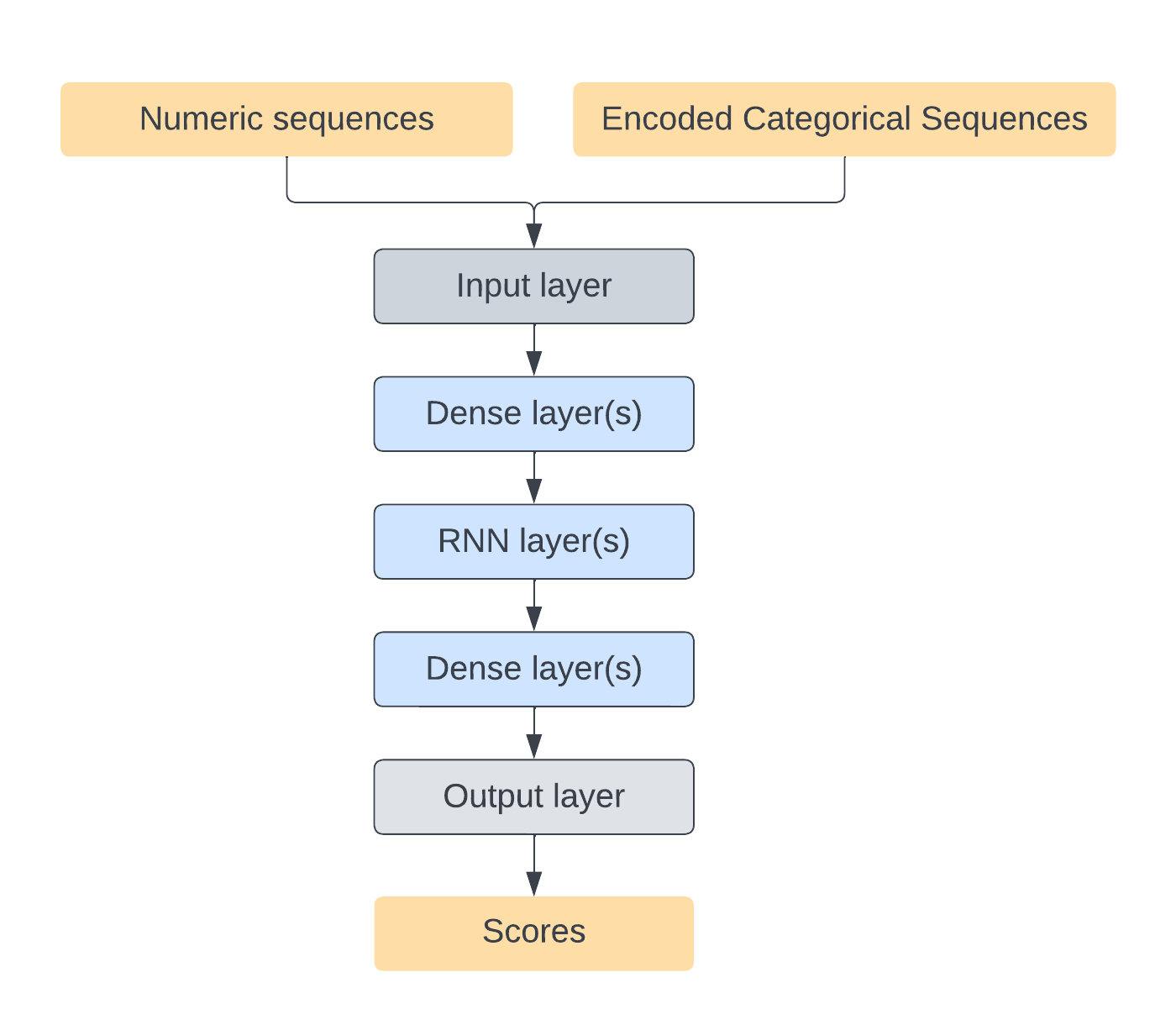
- Lastly, train a DL model using the encoded sequence data. We use the following network architecture. The DL model starts with an input layer that reads from encoded sequence data, followed by one or more dense layers, one or more RNN layers, one or more dense layers, and finally, an output layer. The number of layers and nodes in each layer are flexible and can be tuned for a given model.
Real-life examples and results
We recently applied the DL modeling approach to data from a large US bank. We used ten time-steps, meaning a history depth of ten transactions including the current transaction. The DL model had:
- Two dense layers (with 128 nodes and 64 nodes, respectively) before the RNN layer
- One RNN layer with 32 GRU units
- One dense layer with 8 nodes after the RNN layer
All programs are in SAS and extensively utilize parallel processing in SAS Viya’s Cloud Analytics Service (CAS) engine. Tests were run in a CAS environment that had eight worker nodes. Analytically, the proposed approach had better fraud detection performance than the traditional approach. In addition to superior scoring accuracy, the DL modeling approach has computational (and other) advantages over the traditional approach:
- It takes much less time to build the model and uses a fraction of the storage space.
- Since the DL model automatically generates features during training instead of requiring manual feature creation, there is a significant reduction in time for modeling efforts and domain knowledge required.
- Furthermore, the whole process is fully automated and requires minimal manual intervention from modelers, which reduces opportunities for human error.
Of course, there is no such thing as a free lunch. Given the strict regulations and oversight in the banking space, this proposed approach will encounter challenges beyond the analytical and computational difficulties described above. Even though it comes at the cost of increased effort in satisfying explainability and transparency requirements, the DL approach outlined above solves several problems in the real-time payment fraud space in a thorough and satisfying way.
Conclusion
For decades, state-of-the-art approaches in supervised classification depended on the labor-intensive feature creation process. And the computationally intensive process of eliminating features that did not provide value. This example shows that there is promise in the RNN DL modeling approach, which generates reliable predictions without generating a catalog of features first.
LEARN MORE | Discover how these models work in similar industry-specific offerings.Authors: Yi Liao, Artin Armagan, and Dan Kelly
Artin Armagan is a statistician working with a brilliant team of data scientists who are building real-time transactional fraud detection models for financial institutions in the SAS Applied AI and Modeling division. Throughout his tenure at SAS, he has worked on analytical modeling across various business domains, including banking, insurance, and healthcare. Previously, he held postdoctoral positions at Duke University after completing his graduate studies at the University of Tennessee.
Dan Kelly is an analyst and manager in the SAS Applied AI and Modeling division. His experience covers consulting (mainly in government and financial services), software development, and professional education. He has been solving customer business problems using SAS his whole career.