As SAS delivered powerful end-to-end artificial intelligence & machine learning platform SAS® Viya®, more and more SAS users plan to adopt this new platform to produce faster outcomes and invaluable insights. The significant difference between SAS Viya and SAS 9 is, UTF-8 is the default session encoding in SAS Viya, while SAS 9 provides different default session encoding for each operating environment. In other words, many existing SAS 9 code in different file encoding need to work on new platform.
Due to file encoding of SAS code may be inconsistent with SAS session encoding, SAS user may encounter new issue such as garbage text output or transcoding failure in SAS Unicode environment. In fact, both SAS Viya and SAS 9.4 with Unicode support use UTF-8 encoding as session encoding, SAS 9.4 with Unicode support can expose most problems which user may encounter in SAS Viya.
Legacy encoding code in UTF-8 session
Some Asia Pacific SAS users usually use extended ASCII encoding by default (we also call it native encoding or legacy encoding), so the characters in the SAS code file are stored as file encoding such as EUC-CN, MS-950, SHIFT-JIS or EUC-KR etc (The popular word GB2312 is the registered internet name for EUC-CN, and EUC-CN is the usual encoded form of GB2312 standard for Simplified Chinese characters).
When they run these SAS code in SAS with Unicode Support, which means, SAS session encoding is UTF-8, they found the text in the ODS output are changed, and unexpected characters were output. For example, Run the following SAS code with file encoding (EUC-CN) in SAS Unicode session, it will generate garbage text in HTML output and RTF output.
ods rtf file="test.rtf"; ods rtf file="test.rtf"; proc report data=sashelp.class style(report)={pretext="受试对象" posttext="后置文本"} ; column name sex age weight height; define name/display; run; ods rtf close; |
Diagram: MBCS text in SAS code with legacy encoding, output text in HTML and RTF are all garbage.
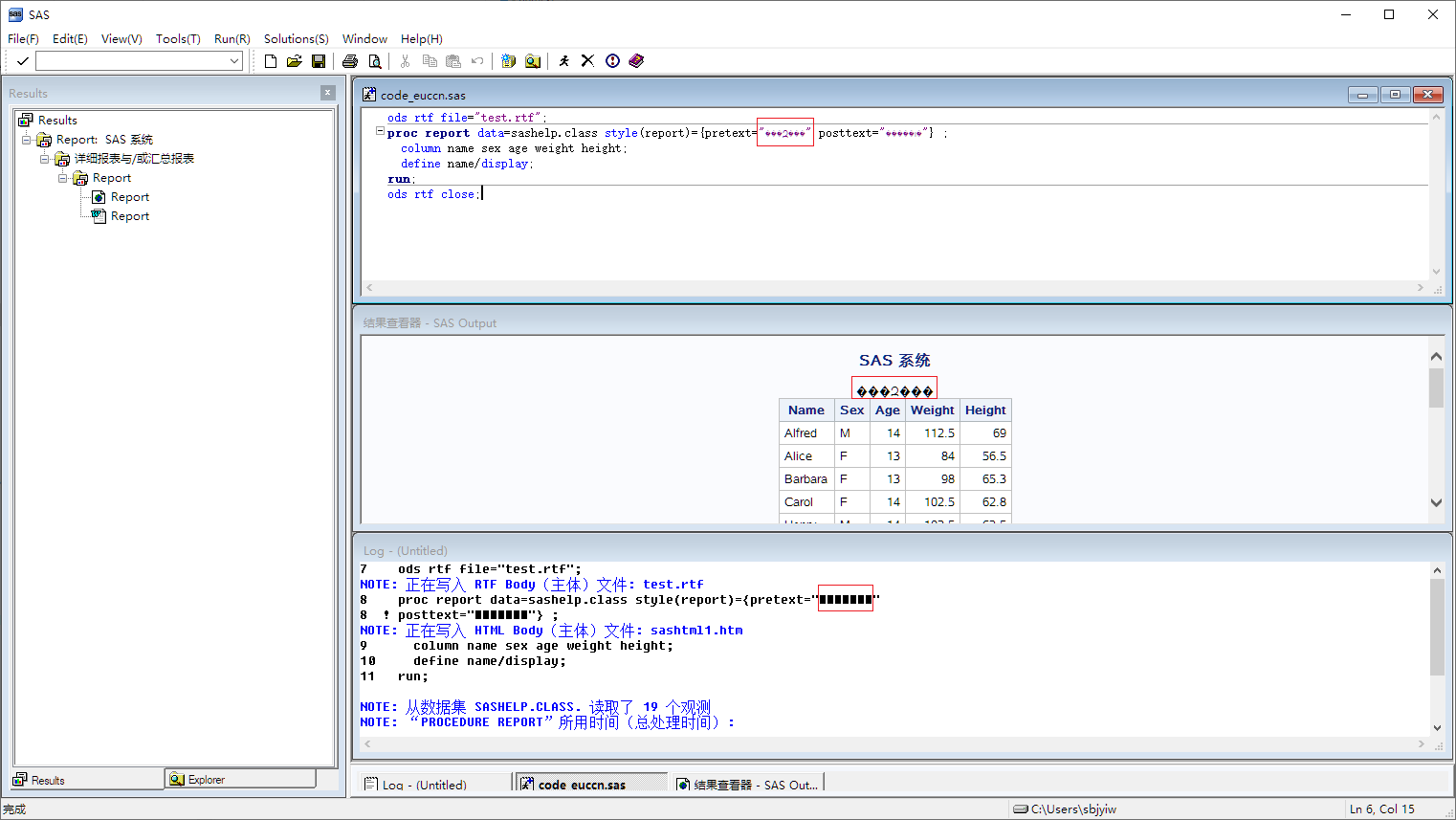
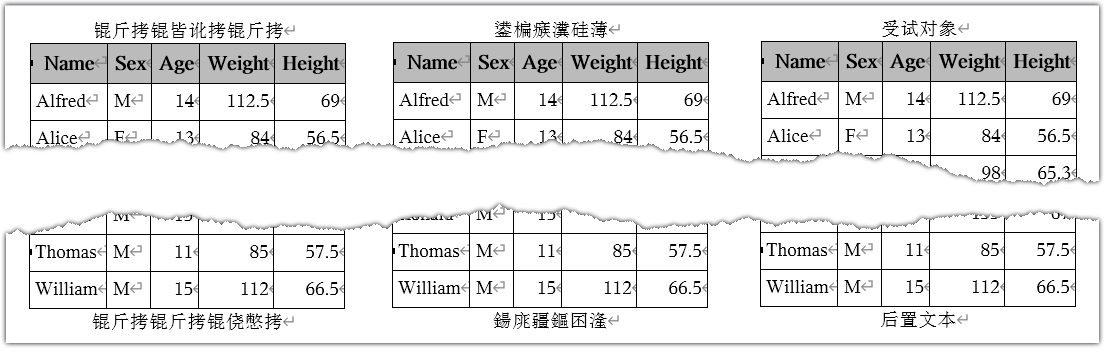
Especially for those users who want to generate RTF documents, they may find their Proc REPORT output has garbage text “锟斤拷锟皆讹拷锟斤拷”, which is specified by PRETEXT and POSTTEXT of STYLE option. Please see text in red rectangle below.
To migrate your original SAS code to Unicode environment, you can open the original SAS code in SAS with native encoding (e.g., SAS Simplified Chinese), then specify the file encoding to “Unicode (UTF-8)” in “Save as” dialog. So, you manually transcode the original SAS code from EUC-CN to UTF-8 file encoding successfully. You also can use other Text Editors or Transcoding Tools to achieve this transcoding goal in batch. Anyway, you keep all information in the new generated SAS code file in UTF-8 without any information lost after this step.
SAS session in native encoding can display and run SAS code file in native encoding and SAS code file in Unicode encoding correctly. But as the upper example indicated, SAS session in Unicode encoding can’t display and run SAS file in native encoding correctly by default. SAS user should specify encoding to “System – Simplified Chinese (EUC)” explicitly in the Open File dialog, then you can use old SAS code with legacy encoding correctly.
Thanks to the SAS Macro %INCLUDE and filename statement, User also can submit and run old SAS code in native encoding in SAS Unicode environment correctly with appropriate encoding of filename statement. See the example below:
filename eucfile "C:\Temp\code_euccn.sas" encoding="euc-cn"; %include eucfile; |
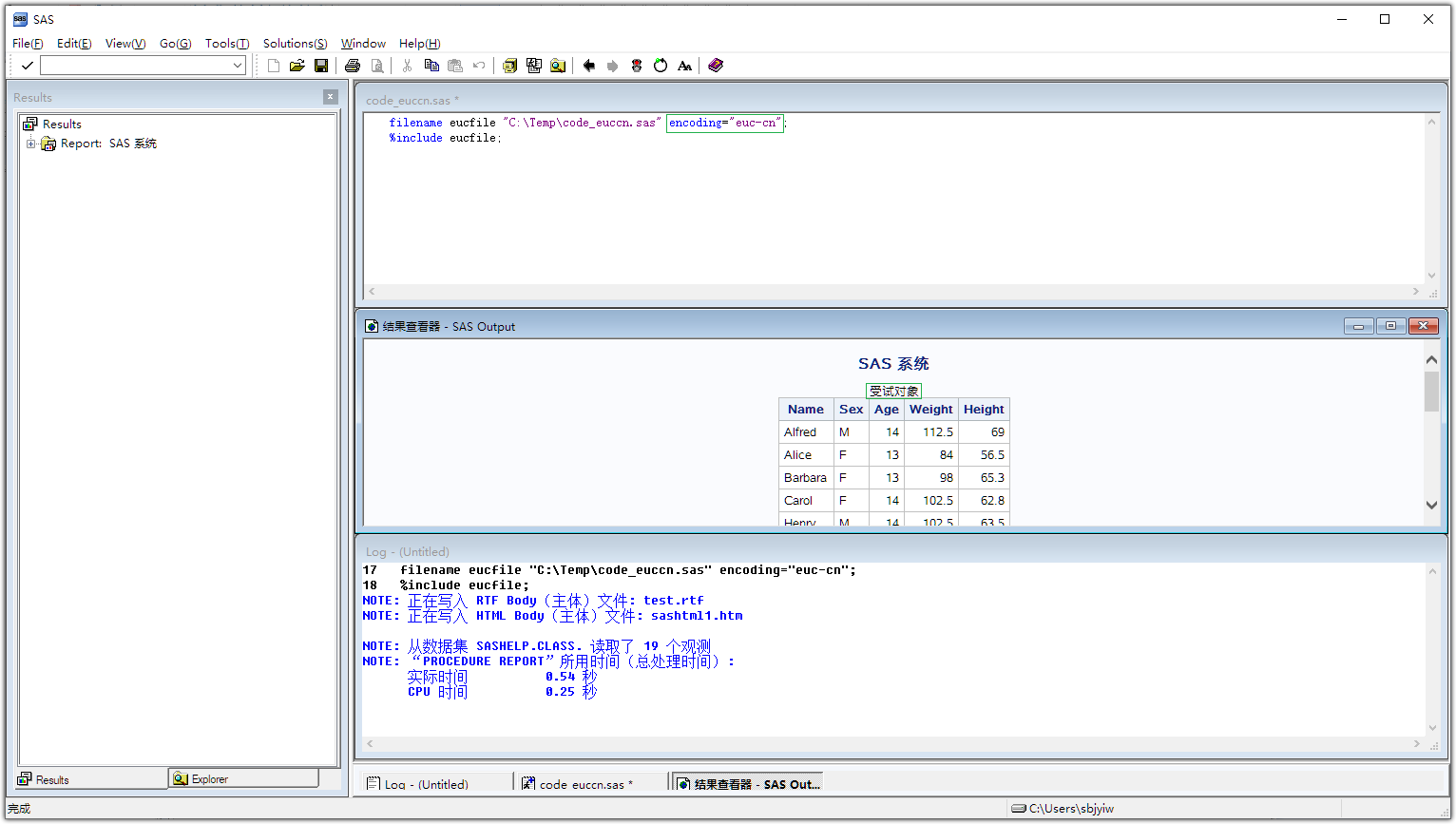
Now we get expected output in HTML (See below), but we still encounter different kinds of garbage text “鍙楄瘯瀵硅薄” in RTF output.
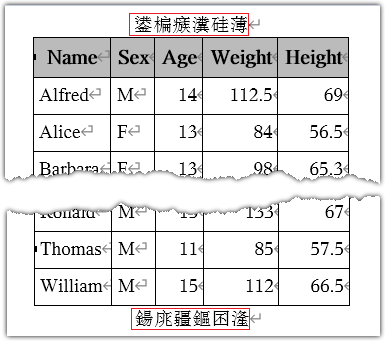
Why did user still get garbage text for the PRETEXT and POSTTEXT argument in PROC REPORT? and how can we fix it with SAS Code? In the ODS RTF output, we got “鍙楄瘯瀵硅薄” for the PRETEXT argument. They are not the expected Chinese characters ”受试对象” in SAS Code. Why user enter 4 Chinese characters but SAS output 6 unexpected Chinese characters in RTF document?
Open the RTF document in Text file editor, you may see the following control sequence:
\cf1\'E5\'8F\'97\'E8\'AF\'95\'E5\'AF\'B9\'E8\'B1\'A1{}\cf0 |
It means the user entered text are processed and output as 12 bytes, the intuition tells us each three bytes for one MBCS character. So three bytes E5 8F 97 are for first Chinese character “受“. Check the characters encoding via Online website, we found 0xE5 0x8F 0x97 is actually the UTF-8 encoding of the first characters “受“.
The reason we got incorrect Simplified Chinese character“鍙” in RTF output is because the EUC-CN code point of “鍙” is E5 8F, the first 2 bytes from the 3 bytes UTF-8 code for “受“. It indicates why the 4 Simplified Chinese characters (3-bytes each for UTF-8) are displayed as 6 Simplified Chinese characters (2-bytes each for EUC-CN).
Now we can answer upper questions now: the reason we got this output as PRETEXT / POSTTEXT use its text as “RAW” text, so \’HH code points are output directly. It means there is no transcoding lost in the output RTF, and it’s reversable to get the right character from those code points. What we need to do is to feed RTF interpreter with three bytes a char.
By the way, we also can use ODS TAGSETS.RTF as the workaround for this case (See below). It would generate expected output for both HTML and RTF. Furthermore, ODS RTF TEXT=“…” doesn’t have the same problem as PRETEXT/POSTTEXT.
ods tagsets.rtf file="test.rtf"; proc report data=sashelp.class style(report)={pretext="受试对象" posttext="后置文本"} ; column name sex age weight height; define name/display; run; ods tagsets.rtf close; |
RTF specification & Unicode encoding
According to the RTF specification, \’HH control sequence use a backslash and single quote, followed by an 8-bit hexadecimal value. The value is interpreted as a code point in local OS code page. It means this approach depends on the local OS codepage, and it decreases the portability of the output RTF, so we should find a better way to solve upper problem.
The second choice is to use \uN? control sequence (since RTF spec 1.5 revision, 1997). A backslash ‘u’ followed by a signed 16-bit integer value in decimal and a correspondence character(here is a question mark). The signed 16-bit integer number value ranges from -32768 to +32767 which is consistent with RTF standard for control characters. This sequence can represent at least U+0000 through to U+FFFF codepoints.
In fact, the code points U+0000 thru to U+FFFF, UTF-16 and UCS2 share same code points in Basic Multilingual Plane (BMP: 0x0000–0xD7FF, 0xE000–0xFFFF), and range U+D800 to U+DFFF (Total 2048, 2^11) are reserved by UCS2 for special purpose to encode non-BMP code points.
For the characters beyond upper range, the code points is from U+010000 to U+10FFFF (Total 1048576, 2^20), we call Supplementary Multilingual Plane (SMP). They are encoded as two 16-bit code units called Surrogate Pair. It contains two code unit called high surrogates (0xD800–xDBFF) and low surrogates (0xDC00–0xDFFF), the actual value is code point (>U+10000) subtract 0x10000 and get a 20-bit number (0x00000-0xFFFFF), then the high 10 bits (range from 0x000-0x3FF) are added to 0xD800 to give high surrogate, and the low 10 bits (range from 0x000-0x3FF) are added to 0xDC00 to give low surrogate. E.g. The surrogate pair for code point U+10000 is 0xD800 0xDC00, the surrogate pair for code point U+10FFFF is 0xDBFF 0xDFFF, they are same as the UTF-16 encoding values. You also can look for the Noto Sans glyph of that char here (Linear B Syllable B008 A).
Solution
With the upper knowledge in mind, we know we should feed RTF interpreter with an escape sequence of \uN?. Please note that N must be a signed 16-bit integer value in decimal.
SAS provide functions like UNICODE and UNICODEC to handle Unicode chars. UNICODE function converts Unicode chars to current session encoding, while UNICODEC converts characters in current session encoding to Unicode chars. Here we need to call UNICODEC to get the escape sequence of user input characters, and Unicode type must be the “NCR”.
NCR means Numeric Character Presentation, for example, the SAS UNICODEC function with “NCR” Unicode type return “受试对象”.What we need to do is to replace the prefix “&#” with new prefix “\u”, and leave the “;” as the default correspondence character. You can see the full logic as below:
data _null_; length utf8 $ 12; utf8=unicodec("受试对象","UTF8"); /*E58F97E8AF95E5AFB9E8B1A1*/ ncr=unicodec("受试对象","NCR"); /*受试对象*/ ncrx=tranwrd(ncr,'&#','\u'); /*\u21463;\u35797;\u23545;\u35937;*/ put utf8 hex. / ncr / ncrx; run; |
Accordingly, I wrap a reusable macro below to handle this kind of problem. We just call system function directly, so the macro can be used anywhere in SAS code. To avoid some potential negative impact, we also limit the logic to UTF-8 session encoding for SAS or Viya. Please note that SAS 9 uses “UTF-8” while SAS Viya uses “UTF8” for the Unicode session encoding.
/*ESCAPE MULTIPLE BYTES STRING FOR ODS RTF OUTPUT TO AVOID GARBAGE TEXT*/ %macro ESC4RTF(str); %if %quote(%substr(%sysfunc(getoption(ENCODING)),1,3)) = %quote(UTF) %then %nrquote(%sysfunc(tranwrd( %nrquote(%sysfunc(UNICODEC(%str(&str),%str(NCR)))), %NRQUOTE(&#), %NRQUOTE(\u) ))); %mend; |
To use the upper macro, we just need to change PRETEXT= and POSTTEXT= value as below. It’s most efficient and reusable fix for this kind of garbage issue for customers:
ods rtf file="test.rtf"; proc report data=sashelp.class style(report)={pretext="%ESC4RTF(受试对象)" posttext="%ESC4RTF(后置文本)"} ; column name sex age weight height; define name/display; run; ods rtf close; |
Now you can see the output result as picture below, the PRETEXT/POSTTEXT output on the left and middle are not expected but adding %ECS4RTF macro to the code generate expected result on the right. We get the expected text “受试对象” in RTF output successfully in SAS Unicode Session.
Summary
ODS RTF is very powerful for SAS user to generate fine-tuned RTF output. Due to RTF file is a plain text file, user can fully control the content with control sequence, handle text transcoding with SAS function or SAS macros. SAS user can migrate their code from legacy encoding working environment to Unicode encoding environment smoothly. SAS user also can inject the SAS Macro %ESC4RTF() described here to keep one version SAS code which need to be run in both legacy and Unicode environment. Even putting escape characters in SAS code directly is possible, it’s not easy to read and maintain. So, using the %ESC4RTF() macro is a good choice for SAS programmers.
