 Editor's note: The following post is from Xiaoyuan Zhang, presenter at an upcoming Insurance and Finance User Group (IFSUG) webinar.
Editor's note: The following post is from Xiaoyuan Zhang, presenter at an upcoming Insurance and Finance User Group (IFSUG) webinar.
Learn more about Xiaoyuan Zhang.
As a business user with limited statistical skills, I don’t think I could build a credit scorecard without the help of SAS Enterprise Miner. As you can see from the flow chart, SAS Enterprise Miner, a descriptive and predictive modeling software, does an amazing job in model developing and streamlining.
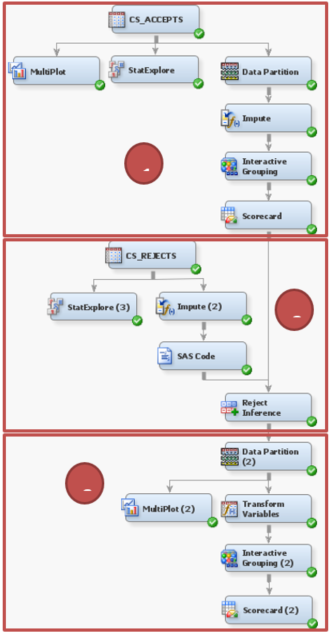 The flow chart presents my whole credit score modeling process, which is divided into three parts: creating the preliminary scorecard, performing reject inference, and building the final scorecard. I will cover the whole process in the Insurance and Finance Users Group (IFSUG) virtual session on Feb 3, 2017. In this blog I wanted to emphasize the second part, which is sometimes easy to ignore.
The flow chart presents my whole credit score modeling process, which is divided into three parts: creating the preliminary scorecard, performing reject inference, and building the final scorecard. I will cover the whole process in the Insurance and Finance Users Group (IFSUG) virtual session on Feb 3, 2017. In this blog I wanted to emphasize the second part, which is sometimes easy to ignore.
The data for preliminary scorecard is from only accepted loan applications. However, the scorecard modeler needs to apply the scorecard to all applicants, both accepted and rejected. To solve the sample bias problem reject inference is performed.
Before inferring the behavior (good or bad) of the rejected applicants, data examination is needed. I used StatExplore node to explore the data and found out that there were a significant number of missing values, which is problematic. Because in SAS Enterprise Miner regression model, the model that is used here for scorecard creation and reject inference, ignores observations that contain missing values, which reduces the size of the training data set. Less training data can substantially weaken the predictive power of the model.
To help with this problem, Impute Node is used to impute the missing values. In the Properties Panel of the node, there are a variety of choices from which the modeler could choose for the imputation. In this model, Tree surrogate is selected for class variables and Median is selected for interval variables.
However, in Impute Node data role is set as Train. In order to use the data in Reject Inference Node, data role needs to be changed into Score. A SAS Code node is put in between for this purpose, which writes as:

Last but not least, Reject Inference Node is used to infer the performance of the rejected loan applicant data. SAS Enterprise Miner offers three standard, industry-accepted methods for inferring the performance of the rejected applicant data by the use of a model that is built on the accepted applicants. We won’t explore the three methods in detail here, as the emphasis of the blog is on the process.
To hear more on this topic, please register for the IFSUG virtual session, Credit Score Modeling in SAS Enterprise Miner on February 3rd from 11am-12pm ET.
About Xiaoyuan Zhang
Xiaoyuan Zhang grew up in Zhaoyuan China on the coast of the Bohai sea. Her town is famous for its ancient gold mine, hot springs and its unusual and tasty seafood. Her undergraduate degree is from China Agricultural University in Bejing, where she majored in Marketing Intelligence and graduated with honors. She graduated, with honors, from Drexel University with a Master Degree in Finance. She has passed two CFA exams and learned Enterprise Miner in one of her courses. She specializes in efficient credit score modeling with unutilized SAS Enterprise Minor. She is using some of her post-graduation free time to study "regular SAS", to tutor and to volunteer.
