Nearly every organization has to deal with big data, and that often means dealing with big data problems. For some organizations, especially government agencies, addressing these problems provides more than a competitive advantage, it helps them ensure public confidence in their work or meet standards mandated by law. In this blog I wanted to share with you how SAS worked with a government revenue collection agency to successfully manage their big data issues and seamlessly integrate with Hadoop and other technologies.
Hadoop Security
We all know Hadoop pretty well, and if you haven’t heard of Hadoop yet, it is about time you invest some resources to learn more about this upcoming defacto standard for storage and compute. The core of Apache Hadoop consist of a storage part known as HDFS (Hadoop Distributed File System) and a processing part (called MapReduce). Hadoop splits large files into large blocks and distributes them across the nodes of a cluster.
Hadoop was initially developed to solve web-scale problems like webpage search and indexing at Yahoo. However, the potential of the platform to handle big data and analytics caught the attention of a number of industries. Since the initial used of Hadoop was to count webpages and implement algorithms like page-rank, security was never considered a major requirement, until it started getting used by enterprises across the world.
Security incidents and massive fines have become commonplace and financial institutions, in particular, are doing everything to avoid such incidents. Security should never be an afterthought and should be considered in the initial design of the system. The five core pillars of Enterprise Security are as follows:
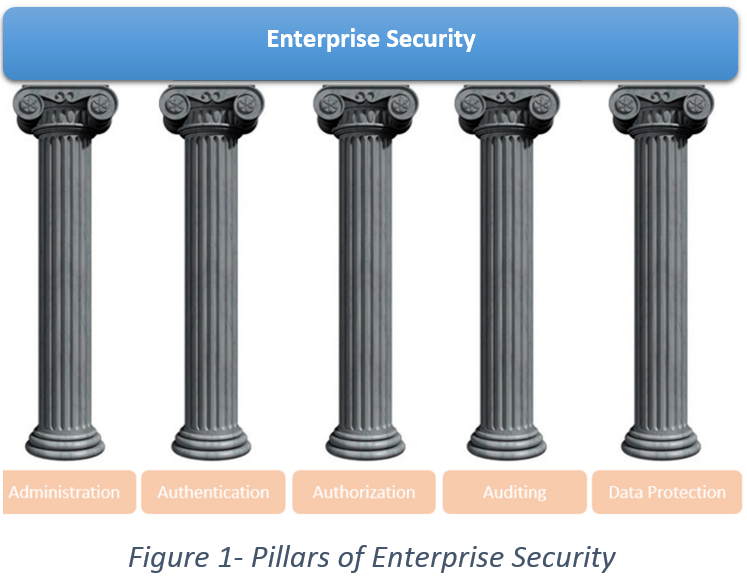
Our customer had the four core pillars covered from Administration to Auditing using tools provided by their Hadoop vendor. While there are options in the open-source community that provide data protection, in this case the organization decided to use a data security company to protect data at rest on top of Cloudera Navigator Encryption. They refer to it as “Double Encryption.”
The challenge
SAS has multiple products around the Hadoop ecosystem to provide the best support for customers. The traditional way of working with Hadoop involves SAS/ACCESS which can involve pulling the data from Hadoop using Hive. However for larger installations, where data movement is a concern, SAS provides Embedded Process technology, which allows you to push SAS code inside of a Hadoop cluster and run it alongside the data blocks. This is a super-efficient way to access large data sets inside of Hadoop by pushing the compute to the data.
Our customer's data security vendor’s product supports access via Hive UDF’s which means you can tokenize/detokenize when working with SAS/ACCESS Interface to Hadoop using PROC SQL and other options, relatively out of the box. In addition, the SAS language (BASE SAS) can be added using the security company’s API (and PROC FMCP and PROC PROTO) to add additional new SAS language functions for the de/tokenisation of data inside BASE SAS already.
However, SAS Embedded Process has no default support for our customer's security vendor and SAS products which utilize SAS EP include SAS Code Accelerator, SAS Scoring Accelerator and LASR-based products and cannot work with data tokenized by the vendor. This was a major challenge for our customer who wanted to use SAS products like SAS Visual Analytics and SAS Visual Statistics on large volumes of data stored on Hadoop.
The challenge hence was to make SAS Embedded Process work with their data security vendor’s software to perform detokenization before passing the data to SAS procedures.
The possible solutions
We considered various solutions before agreeing on a solution that satisfies all current requirements and could be extended to meet the future needs of our customer. Let’s discuss the top two solutions and the final implementation.
Solution 1: SERDE approach
Our first approach was to create a custom Hive SERDE that wraps the data security company’s APIs. With 9.4M3 the SAS Embedded Process (EP) can read & write via SERDE APIs with some possible constraints and limitations including DS2’s SET/MERGE capabilities and potential identity credentials being passed on from SAS to the company’s APIs.
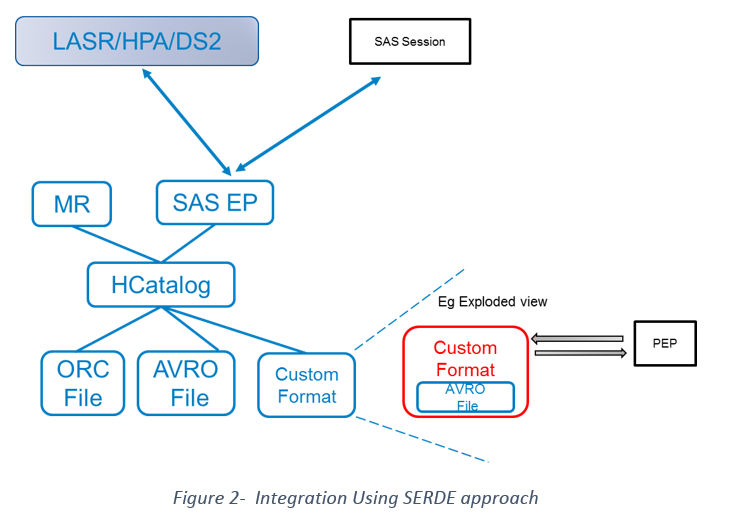
The approach had various drawbacks but the top drawback was in working with various file formats. This approach was discarded because it would have meant lots of rework with every new data format being released by the Hadoop community. While it is true that generally an organization would standardize a few formats to be used for its use cases, it is nonetheless a limiting factor.
Solution 2: Use HDMD with Custom Input Formats
The second approach was to use HDMD with custom input formats. SAS HDMD supports custom input formats which will allow you to plug in your custom input format. A high-level architectural diagram looks something like Figure 2. This approach works with a variety of file formats, and we have tested it with Parquet, Avro and ORC with good results. The objective is to load a dataset onto Hadoop or use an existing data set and generate an HDMD file for the dataset. We plug in our custom reader in the HDMD file and as a part of the custom reader we make a number of API calls to the data security company’s API. The API will call on the specific protect and unprotect procedures of the security vendor to protect and/or unprotect the data depending on the requirements and pass the results back to the client.
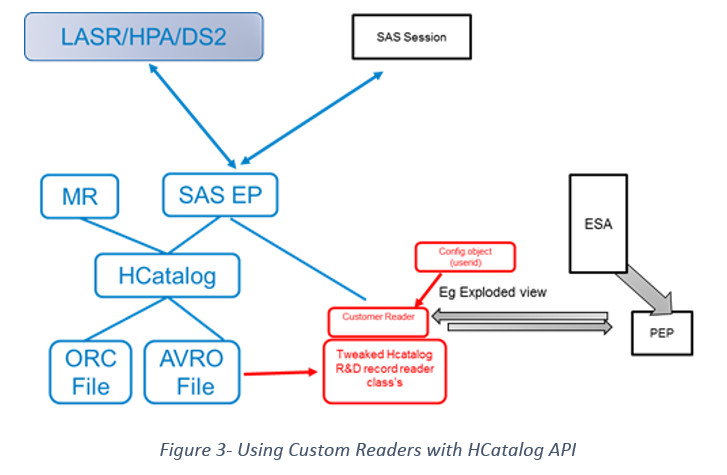
What is an Input/Custom input format BTW?
Data inside Hadoop is typically stored on HDFS (Hadoop Distributed File System). The data needs to be read from the filesystem before being processed. This is achieved using Input Format, which has the following responsibilities.
- Compute input splits
- Input splits represent the part of the data that will be processed by each Map phase. A unique input split is passed to the process. At the start of a Map Reduce job, input format will split the data into multiple parts based on logical record boundaries and HDFS block size. To get the input splits, the following method is called:
- List getSplits(JobContext ctx)
- Input splits represent the part of the data that will be processed by each Map phase. A unique input split is passed to the process. At the start of a Map Reduce job, input format will split the data into multiple parts based on logical record boundaries and HDFS block size. To get the input splits, the following method is called:
- Provide a logic to read the input split
- Each mapper gets a unique input split to process the data. Input format provides a logic to read the split, which is an implementation of the RecordReader interface. The record reader will read the split and emit <key,value> pairs as an input for each map function. The record reader is created using the following method:
- RecordReader<K,V> createRecordReader(InputSplit is, TaskAttemptContext ctx)
- Each mapper gets a unique input split to process the data. Input format provides a logic to read the split, which is an implementation of the RecordReader interface. The record reader will read the split and emit <key,value> pairs as an input for each map function. The record reader is created using the following method:
All the common formats will provide a way to split the data and read records. However, if you want to read a custom data set for which data parsing isn’t available out of the box with Hadoop, you are better off writing a custom input format.
How to write a Custom Input Format?
Writing a custom input format needs Java skills (the programming language in which Hadoop has been written). You have the option to implement Abstract methods of InputFormat class, or extend one of the pre-existing input formats. In our case, we had extended FileInputFormat, and overrode few critical methods like
- getSplits()
- getRecordReader()
The getSplits() will create the splits from the input data, while the getRecordReader() should return an instance of a Java object, which has the ability to read custom records, which in our case was the security vendor’s API.
You can use one of the predefined Record Reader classes or implement your own (most likely if you are writing a custom input format). In our case, we implemented RecordReader interface, and implemented the next() method which is called whenever a new record is found. This is the method where your core business logic is implemented. In our case, we had to write the integration logic by looking at the data, understanding the user who has logged in (available as a part of JobConf object), and then calling the vendor’s APIs to decrypt the data. Sample codes can be requested by contacting me directly.
Integrating a custom input format with SAS
Integrating a custom input format is fairly easy with SAS. SAS allows us to plug in custom formats, which are called before the data is processed via SAS Embedded Process using HDMD files.
When you generate an HDMD file using PROC HDMD, you can specify your custom input format as a part of the generated XML file. Please refer to PROC HDMD documentation.
The generated HDMD file would look something like this.
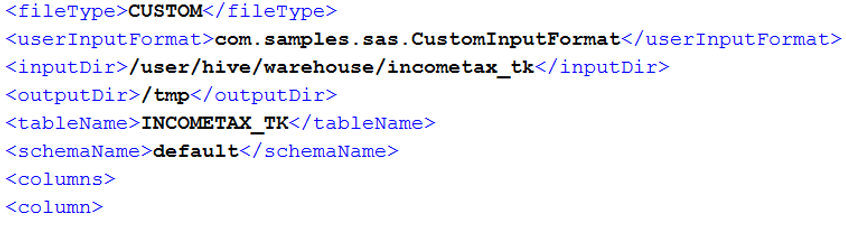
When loading the data from HDFS, SAS will ensure that the specified input format is called prior to any data processing taking place.
The ultimate solution
The solution was demonstrated using data from the tax authorities and included tokenization of data via hive UDFS, detokenization of data according to the policies set on the data security appliance, and performing analytics using SAS Visual Analytics. Only users with permissions on the specific policy were able to view the data, while users with no permissions had access to decrypted data. This additional security helped the enterprise protect users’ information from inadvertent access and resulted in widespread use of Big Data technologies within the Enterprise.
Summary
As you can see from the example above, SAS is open for business, and is already providing deep integration with Hadoop and other technologies using custom APIs. The sky is the limit for people willing to explore the capabilities of SAS.

18 Comments
Getting folks to learn DS2 is going to be the biggest challenge for SAS B.U. users.
DS2 is actually quite simple to learn. Infact SAS offers a training around DS2 which goes through the differences between DS and DS2, and you would be pleasantly surprised to know that it will take a good DS user a couple of hours at max to understand the concepts of DS2 and start using it.
Interesting article. its good to know there are a lot of options using SAS with Hadoop.
Lots to think about.
Very interesting.
Very interestng.
Awesome !
Out of curiosity, are there any plans on including this SAS/Access component on SAS UE so that one can test it?
By SAS/Access component do you mean to say the access to Hive UDFs via SAS? For SAS/Access component you would need to have SAS/Access to Hadoop licensed. Once you have that you can register the UDF in hive, and call it as a normal function. Do you have a specific use case at hand that we can help with?
Interesting! Good to know
Thanks for sharing this great piece. Just wondering if hadoop can be used in conjunction with cloud. If possible what are the potential risks/threats?
You can run this on the cloud or on-premise. If your Hadoop environment is on a SAS supported distribution on AWS or Azure, you should be able to run this directly on the Cloud.
Could it work with VA hosted in the SAS cloud?
Performance of data in/out from Hadoop and data security are the two major factors we need to address.
Thank you for your comment. Actually the Embedded Process runs directly on Hadoop so all processing is done as a part of the MR process.
It's a powerful and useful tool.
That's interesting, as it seems the bulk of the work is a type data management.
Interesting paper